Sztuczna inteligencja jest świadkiem ogromnego wzrostu w wypełnianiu luki między możliwościami ludzi i maszyn. Zarówno naukowcy, jak i pasjonaci pracują nad wieloma aspektami tej dziedziny, aby wydarzyć niesamowite rzeczy. Jednym z wielu takich obszarów jest dziedzina widzenia komputerowego.
Celem tej dziedziny jest umożliwienie maszynom patrzenia na świat tak, jak ludzie, postrzeganie go w podobny sposób, a nawet wykorzystywanie wiedzy dla wielu zadań, takich jak Obraz & Rozpoznawanie wideo, analiza obrazu & Klasyfikacja, odtwarzanie multimediów, systemy rekomendacji, przetwarzanie języka naturalnego itp. Postępy in Computer Vision with Deep Learning został skonstruowany i udoskonalony z czasem, głównie w oparciu o jeden konkretny algorytm – konwolucyjną sieć neuronową.
Wprowadzenie

Konwolucyjna sieć neuronowa (ConvNet / CNN) to uczenie głębokie algorytm, który może przyjąć obraz wejściowy, przypisać wagę (learnabl e wagi i uprzedzenia) do różnych aspektów / obiektów na obrazie i umieć odróżnić jeden od drugiego. Przetwarzanie wstępne wymagane w ConvNet jest znacznie niższe w porównaniu z innymi algorytmami klasyfikacji. Podczas gdy w prymitywnych metodach filtry są projektowane ręcznie, po odpowiednim przeszkoleniu, ConvNets mają zdolność uczenia się tych filtrów / charakterystyk.
Architektura ConvNet jest analogiczna do struktury połączeń neuronów u człowieka Brain i został zainspirowany organizacją Rdzenia Wizualnego. Poszczególne neurony reagują na bodźce tylko w ograniczonym obszarze pola widzenia, znanym jako pole odbioru. Zbiór takich pól nakłada się na cały obszar wizualny.
Dlaczego ConvNets zamiast Feed-Forward Neural Nets?

Obraz to nic innego jak macierz wartości pikseli, prawda? Dlaczego więc nie spłaszczyć obrazu (np. Matrycy obrazu 3×3 do wektora 9×1) i nie przesłać go do perceptronu wielopoziomowego w celu klasyfikacji? Uh … niezupełnie.
W przypadku skrajnie podstawowych obrazów binarnych metoda może pokazywać średni wynik precyzji podczas przewidywania klas, ale miałaby niewielką lub żadną dokładność, jeśli chodzi o złożone obrazy zależne od pikseli w całym tekście.
ConvNet jest w stanie skutecznie uchwycić zależności przestrzenne i czasowe na obrazie poprzez zastosowanie odpowiednich filtrów. Architektura zapewnia lepsze dopasowanie do zbioru danych obrazu ze względu na zmniejszenie liczby zaangażowanych parametrów i możliwość ponownego wykorzystania wag. Innymi słowy, można nauczyć sieć, aby lepiej rozumiała złożoność obrazu.
Obraz wejściowy

Na rysunku mamy obraz RGB rozdzielony trzema płaszczyznami koloru – czerwoną, zieloną, i niebieski. Istnieje wiele takich przestrzeni kolorów, w których istnieją obrazy – skala szarości, RGB, HSV, CMYK itp.
Możesz sobie wyobrazić, jak wymagałyby obliczeń rzeczy, gdy obrazy osiągnęłyby wymiary, powiedzmy 8K (7680 × 4320). Rolą ConvNet jest zredukowanie obrazów do postaci, która jest łatwiejsza do przetworzenia, bez utraty cech kluczowych dla uzyskania dobrej prognozy. Jest to ważne, gdy mamy zaprojektować architekturę, która jest nie tylko dobra w uczeniu się funkcji, ale także jest skalowalna do ogromnych zbiorów danych.
Warstwa konwolucji – jądro
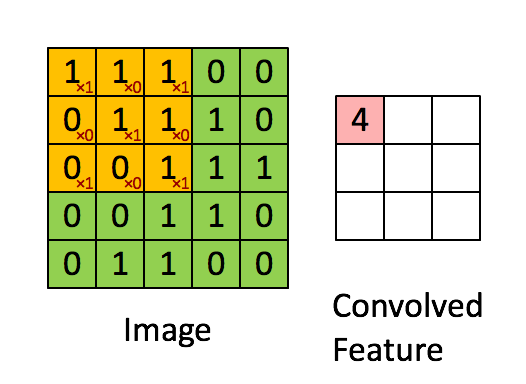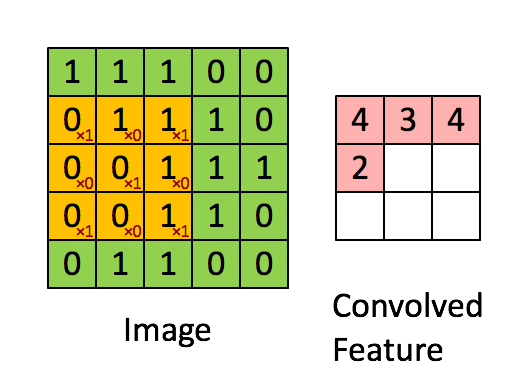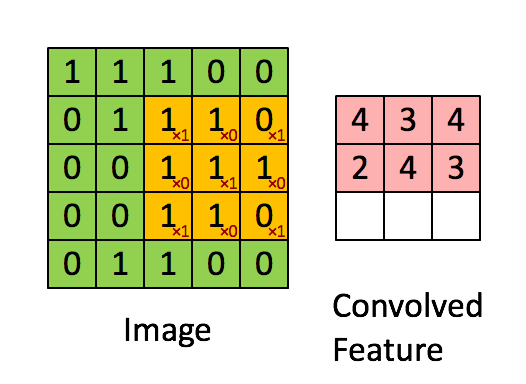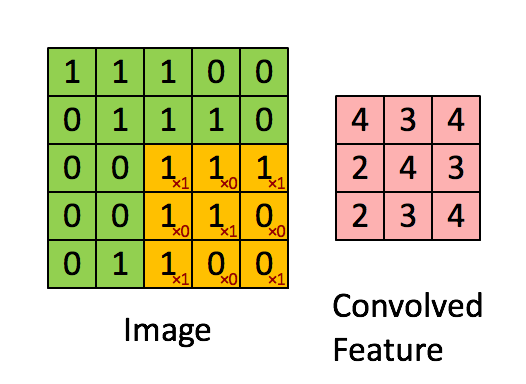
Obraz Wymiary = 5 (wysokość) x 5 (szerokość) x 1 (liczba kanałów, np. RGB)
W powyższej demonstracji sekcja zielona przypomina nasz obraz wejściowy 5x5x1, I. Element zaangażowany w przenoszenie operacja splotu w pierwszej części warstwy splotu nazywana jest jądrem / filtrem, K, reprezentowanym kolorem żółtym. Wybraliśmy K jako macierz 3x3x1.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Jądro przesuwa się 9 razy z powodu długości kroku = 1 (bez kroku), za każdym razem wykonując macierz operacja mnożenia między K a częścią P obrazu, nad którą unosi się jądro.

Filtr przesuwa się w prawo z określoną wartością kroku, aż przeanalizuje całą szerokość. Przechodząc dalej, przeskakuje na początek (po lewej) obrazu z tą samą wartością kroku i powtarza ten proces, aż przejdzie cały obraz.
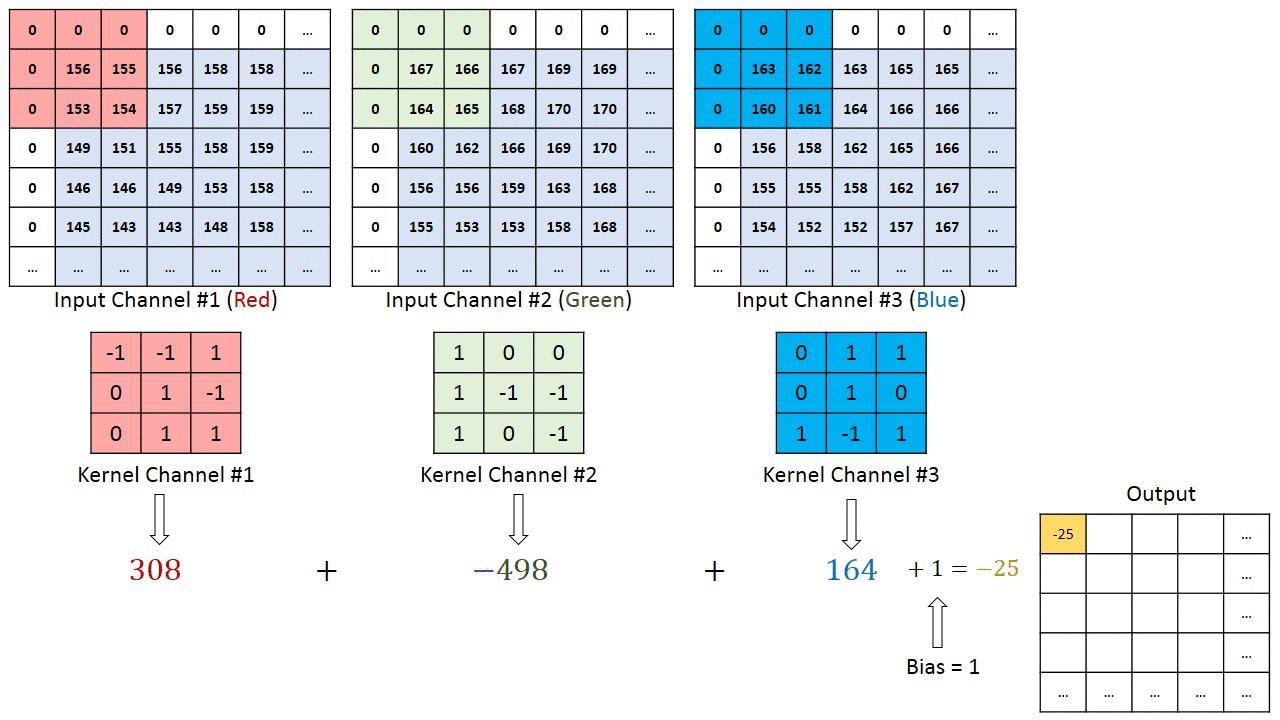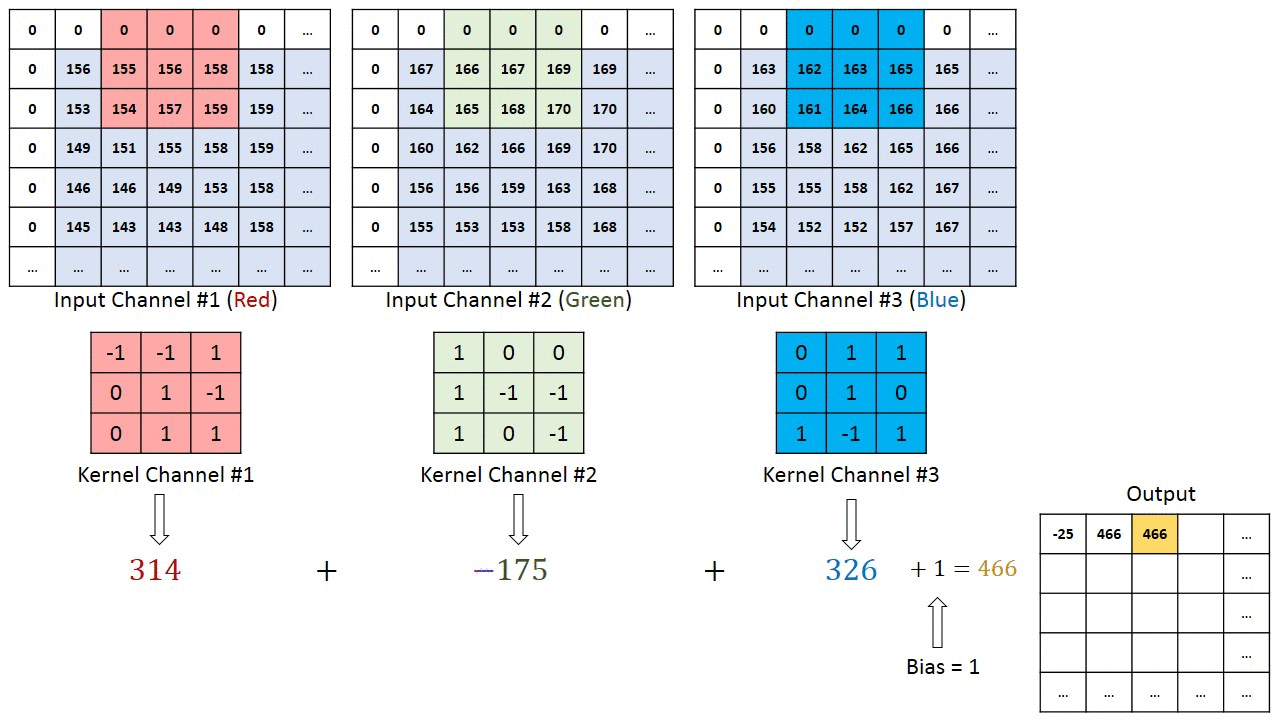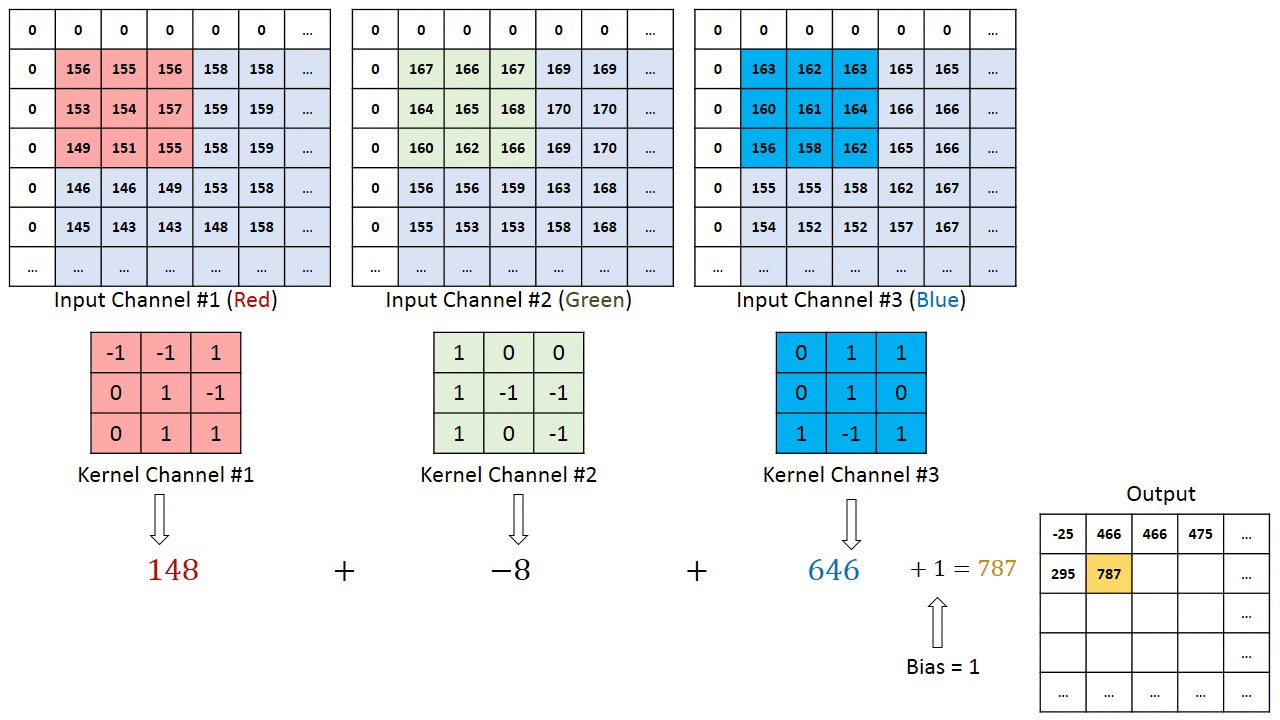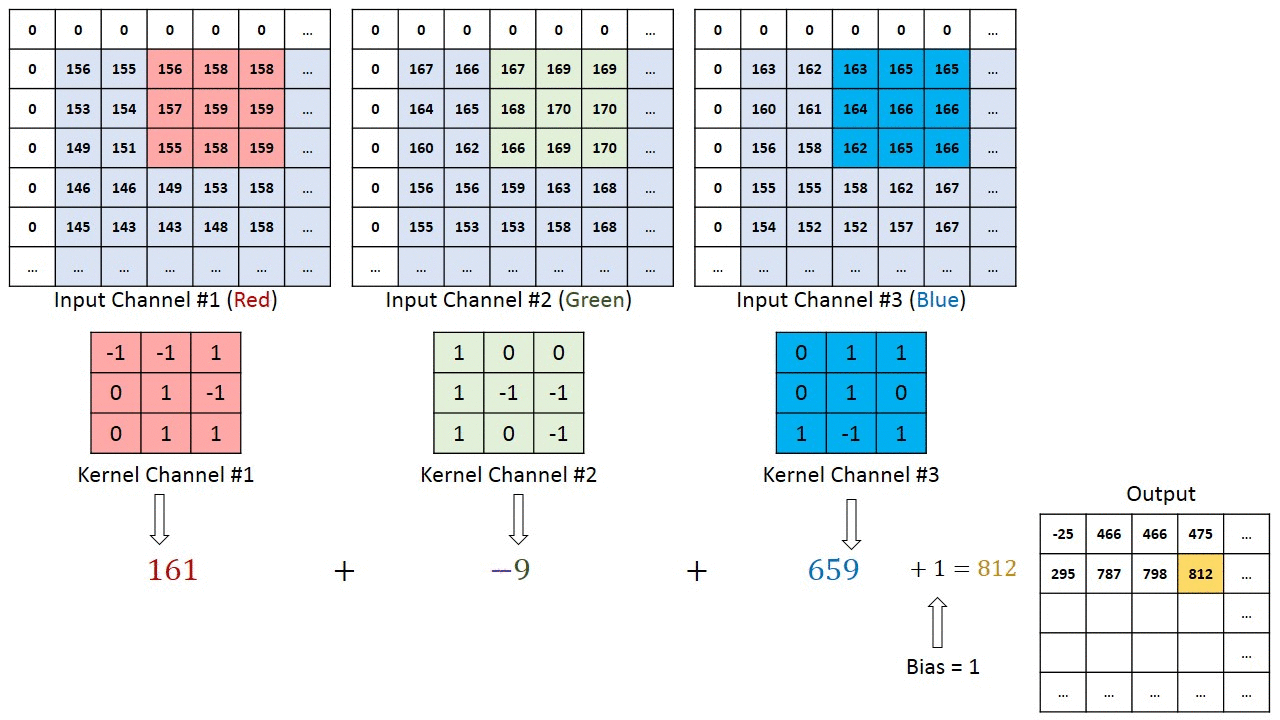
W przypadku obrazów z wieloma kanałami (np. RGB ), Kernel ma taką samą głębię jak obraz wejściowy. Mnożenie macierzy jest wykonywane między stosem Kn i In (;;), a wszystkie wyniki są sumowane z odchyleniem, aby otrzymać ściśnięty kanał o jednej głębokości, konwertowany wynik funkcji.
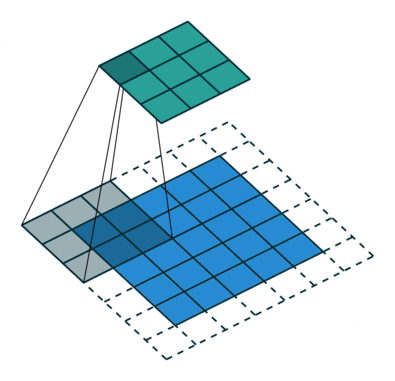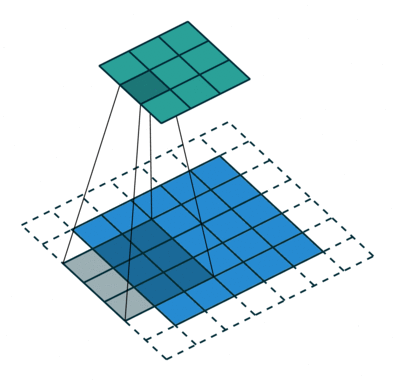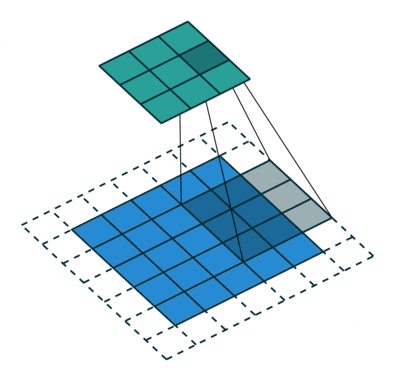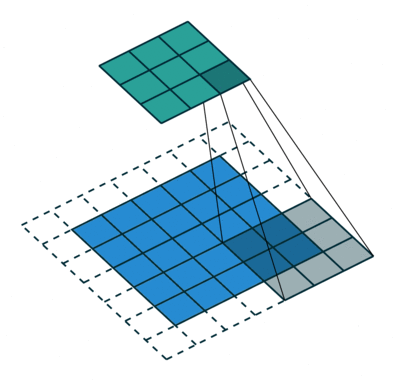
Celem operacji konwolucji jest wyodrębnienie cech wysokiego poziomu, takich jak krawędzie, z obrazu wejściowego. Sieci Convolution nie muszą być ograniczone tylko do jednej warstwy konwolucyjnej. Tradycyjnie, pierwszy ConvLayer jest odpowiedzialny za przechwytywanie cech niskiego poziomu, takich jak krawędzie, kolor, orientacja gradientu itp. Dzięki dodanym warstwom architektura dostosowuje się również do funkcji wysokiego poziomu, dając nam sieć, która ma pełnowartościowe zrozumienie obrazów w zbiorze danych, podobnie jak byśmy to zrobili.
Istnieją dwa typy wyników operacji – jeden, w którym element splotu ma zmniejszoną wymiarowość w porównaniu z danymi wejściowymi, a drugi, w którym wymiarowość jest zwiększona lub pozostaje taka sama. Odbywa się to poprzez zastosowanie prawidłowego dopełnienia w przypadku pierwszego lub samego dopełnienia w przypadku drugiego.
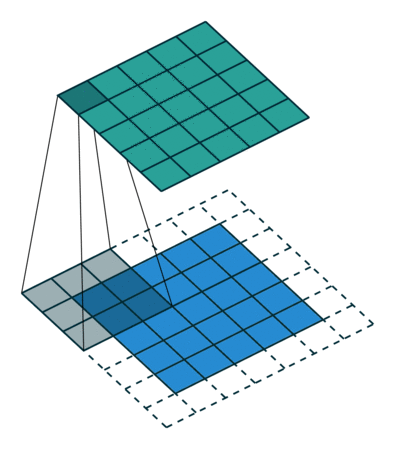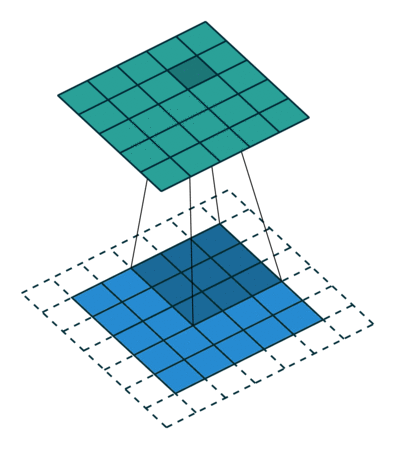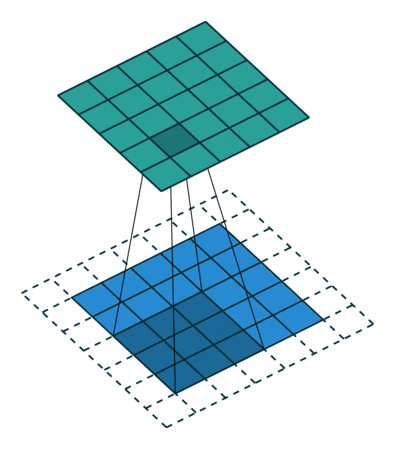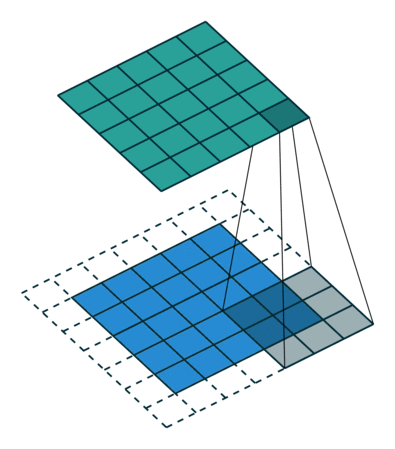
Kiedy powiększamy obraz 5x5x1 do obrazu 6x6x1, a następnie nakładamy na niego jądro 3x3x1, okazuje się, że Okazuje się, że zwinięta macierz ma wymiary 5x5x1. Stąd nazwa – Same Padding.
Z drugiej strony, jeśli wykonamy tę samą operację bez dopełnienia, otrzymamy macierz, która ma wymiary samego jądra (3x3x1) – Valid Padding.
Poniższe repozytorium zawiera wiele takich GIF-ów, które pomogłyby Ci lepiej zrozumieć, w jaki sposób dopełnienie i długość kroku współpracują, aby osiągnąć wyniki odpowiadające naszym potrzebom.
Warstwa puli
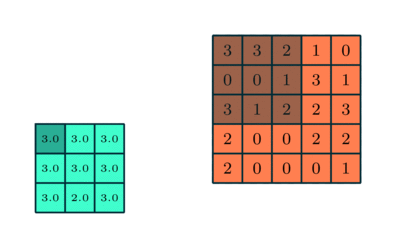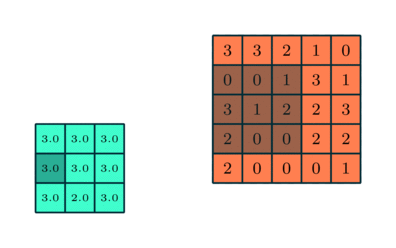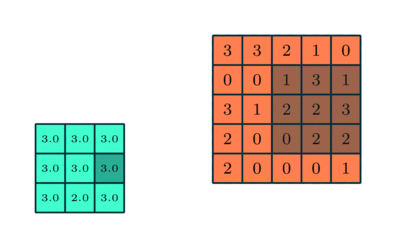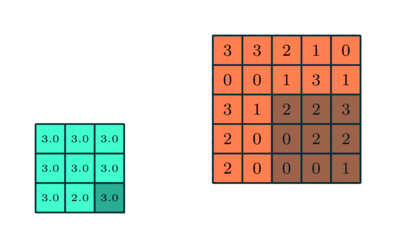
Podobnie jak warstwa splotowa, warstwa puli jest odpowiedzialny za zmniejszenie przestrzennego rozmiaru elementu konwekcyjnego. Ma to na celu zmniejszenie mocy obliczeniowej wymaganej do przetwarzania danych poprzez redukcję wymiarowości. Ponadto jest to przydatne do wyodrębniania dominujących cech, które są niezmienne rotacyjne i pozycyjne, co pozwala na utrzymanie procesu efektywnego uczenia modelu.
Istnieją dwa rodzaje puli: maksymalne i średnie łączenie. Max Pooling zwraca maksymalną wartość z części obrazu pokrytej przez jądro. Z drugiej strony, Średnia pula zwraca średnią wszystkich wartości z części obrazu pokrytej przez jądro.
Maksymalna pula działa również jako tłumik szumów. Całkowicie odrzuca hałaśliwe aktywacje, a także usuwa szumy wraz z redukcją wymiarowości. Z drugiej strony, Average Pooling po prostu wykonuje redukcję wymiarowości jako mechanizm tłumienia szumów. Dlatego możemy powiedzieć, że Max Pooling działa dużo lepiej niż Average Pooling.
Warstwa konwolucyjna i warstwa puli tworzą razem i-tą warstwę konwolucyjnej sieci neuronowej. W zależności od złożoności obrazów liczba takich warstw może zostać zwiększona, aby jeszcze bardziej uchwycić szczegóły niskiego poziomu, ale kosztem większej mocy obliczeniowej.
Po przejściu przez powyższy proces otrzymaliśmy z powodzeniem umożliwiło modelowi zrozumienie funkcji. Idąc dalej, zamierzamy spłaszczyć ostateczne wyjście i przesłać je do zwykłej sieci neuronowej w celu klasyfikacji.
Klasyfikacja – w pełni połączona warstwa (warstwa FC)

Dodanie warstwy w pełni połączonej jest (zwykle) tanim sposobem uczenia się nieliniowych kombinacji cech wysokiego poziomu, reprezentowanych przez dane wyjściowe warstwy splotowej. Warstwa w pełni połączona uczy się prawdopodobnie nieliniowej funkcji w tej przestrzeni.
Teraz, gdy przekonwertowaliśmy nasz obraz wejściowy do postaci odpowiedniej dla naszego wielopoziomowego perceptronu, spłaszczymy obraz do postaci wektor kolumnowy. Spłaszczony sygnał wyjściowy jest podawany do sieci neuronowej ze sprzężeniem zwrotnym, a propagacja wsteczna jest stosowana w każdej iteracji uczenia. W ciągu szeregu epok model jest w stanie rozróżnić dominujące i pewne cechy niskiego poziomu w obrazach i sklasyfikować je za pomocą techniki klasyfikacji Softmax.
Dostępne są różne architektury CNN, które były kluczowe w tworzenie algorytmów, które zasilą i będą zasilać sztuczną inteligencję jako całość w dającej się przewidzieć przyszłości. Niektóre z nich zostały wymienione poniżej:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
