L’intelligence artificielle a connu une croissance monumentale en comblant le fossé entre les capacités des humains et des machines. Chercheurs et passionnés, travaillent sur de nombreux aspects du domaine pour réaliser des choses étonnantes. L’un des nombreux domaines de ce type est le domaine de la vision par ordinateur.
Le programme de ce domaine est de permettre aux machines de voir le monde comme les humains le font, de le percevoir de manière similaire et même d’utiliser les connaissances pour une multitude des tâches telles que Image & Reconnaissance vidéo, Analyse d’image & Classification, Récréation multimédia, Systèmes de recommandation, Traitement du langage naturel, etc. Les progrès dans Computer Vision with Deep Learning a été construit et perfectionné avec le temps, principalement sur un algorithme particulier – un réseau neuronal convolutif.
Introduction

Un réseau neuronal convolutif (ConvNet / CNN) est un Deep Learning algorithme qui peut prendre une image d’entrée, attribuer de l’importance (learnabl e poids et biais) à divers aspects / objets de l’image et être capable de se différencier l’un de l’autre. Le prétraitement requis dans un ConvNet est bien inférieur à celui d’autres algorithmes de classification. Alors que dans les méthodes primitives, les filtres sont conçus à la main, avec suffisamment de formation, les ConvNets ont la capacité d’apprendre ces filtres / caractéristiques.
L’architecture d’un ConvNet est analogue à celle du modèle de connectivité des neurones chez l’homme Brain et s’est inspiré de l’organisation du Visual Cortex. Les neurones individuels ne répondent aux stimuli que dans une région restreinte du champ visuel connue sous le nom de champ récepteur. Une collection de ces champs se chevauchent pour couvrir toute la zone visuelle.
Pourquoi les ConvNets sur les réseaux neuronaux à feed-forward?

Une image n’est rien d’autre qu’une matrice de valeurs de pixels, non? Alors pourquoi ne pas simplement aplatir l’image (par exemple, une matrice d’image 3×3 en un vecteur 9×1) et la transmettre à un Perceptron à plusieurs niveaux à des fins de classification? Euh … pas vraiment.
Dans le cas d’images binaires extrêmement basiques, la méthode peut afficher un score de précision moyen lors de la prédiction de classes mais aurait peu ou pas de précision lorsqu’il s’agit d’images complexes ayant des dépendances de pixels
Un ConvNet est capable de capturer avec succès les dépendances spatiales et temporelles dans une image grâce à l’application de filtres appropriés. L’architecture effectue un meilleur ajustement à l’ensemble de données d’image en raison de la réduction du nombre de paramètres impliqués et de la réutilisabilité des poids. En d’autres termes, le réseau peut être formé pour mieux comprendre la sophistication de l’image.
Image d’entrée

Dans la figure, nous avons une image RVB qui a été séparée par ses trois plans de couleur – Rouge, Vert, et bleu. Il existe un certain nombre de ces espaces colorimétriques dans lesquels des images existent – Niveaux de gris, RVB, HSV, CMJN, etc.
Vous pouvez imaginer à quel point les choses seraient intensives en calcul une fois que les images atteignent des dimensions, disons 8K (7680 × 4320). Le rôle du ConvNet est de réduire les images sous une forme plus facile à traiter, sans perdre les fonctionnalités essentielles pour obtenir une bonne prédiction. Ceci est important lorsque nous devons concevoir une architecture qui est non seulement bonne pour l’apprentissage des fonctionnalités, mais également évolutive vers des ensembles de données massifs.
Couche de convolution – Le noyau
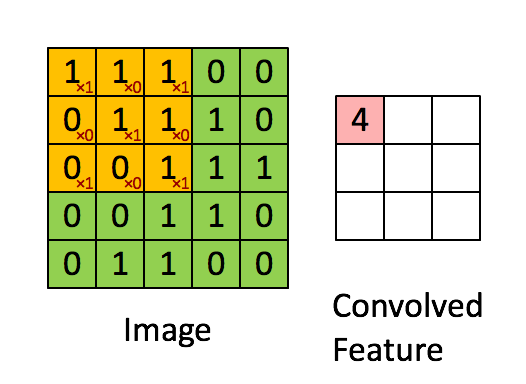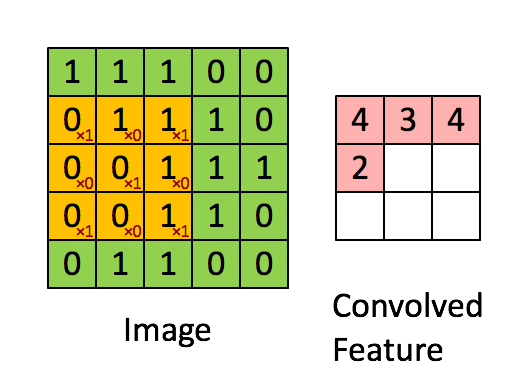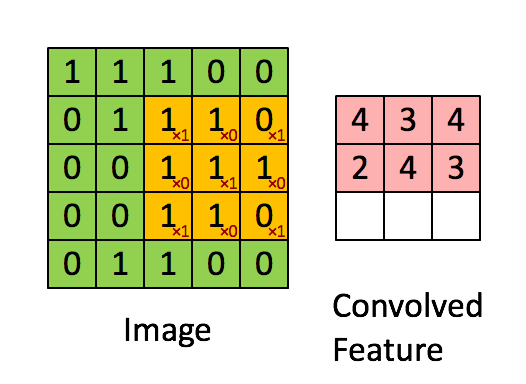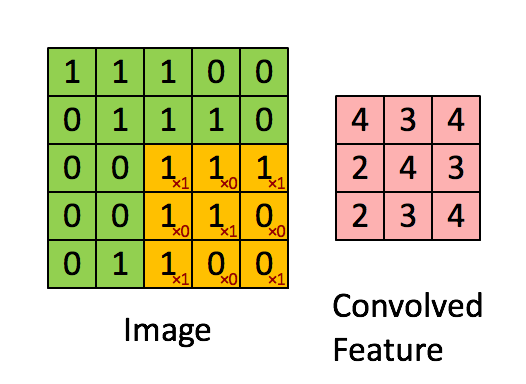
Image Dimensions = 5 (Hauteur) x 5 (Largeur) x 1 (Nombre de canaux, par exemple RVB)
Dans la démonstration ci-dessus, la section verte ressemble à notre image d’entrée 5x5x1, I. L’élément impliqué dans le transport L’opération de convolution dans la première partie d’une couche convolutive est appelée le noyau / filtre, K, représenté dans la couleur jaune. Nous avons sélectionné K comme matrice 3x3x1.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Le noyau se décale 9 fois à cause de Stride Length = 1 (Non-Strided), chaque fois exécutant une matrice opération de multiplication entre K et la partie P de l’image sur laquelle le noyau plane.

Le filtre se déplace vers la droite avec une certaine valeur de foulée jusqu’à ce qu’il analyse la largeur complète. En continuant, il saute au début (à gauche) de l’image avec la même valeur de foulée et répète le processus jusqu’à ce que l’image entière soit traversée.
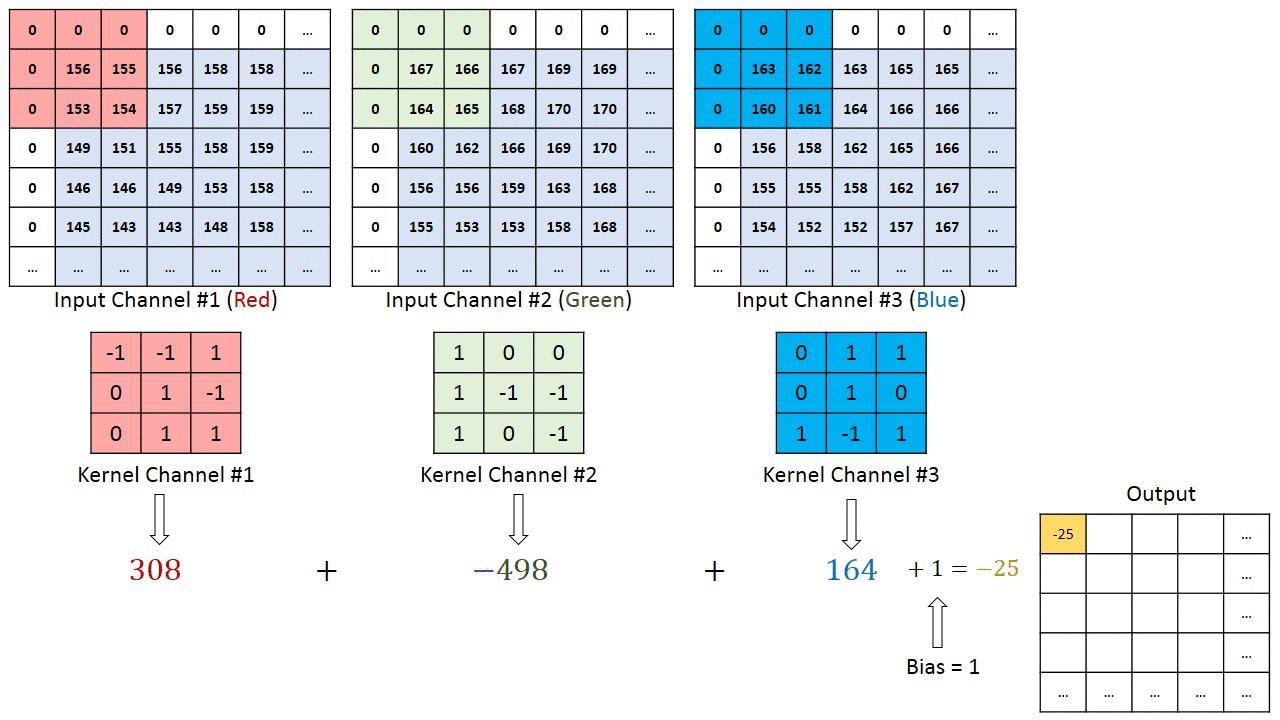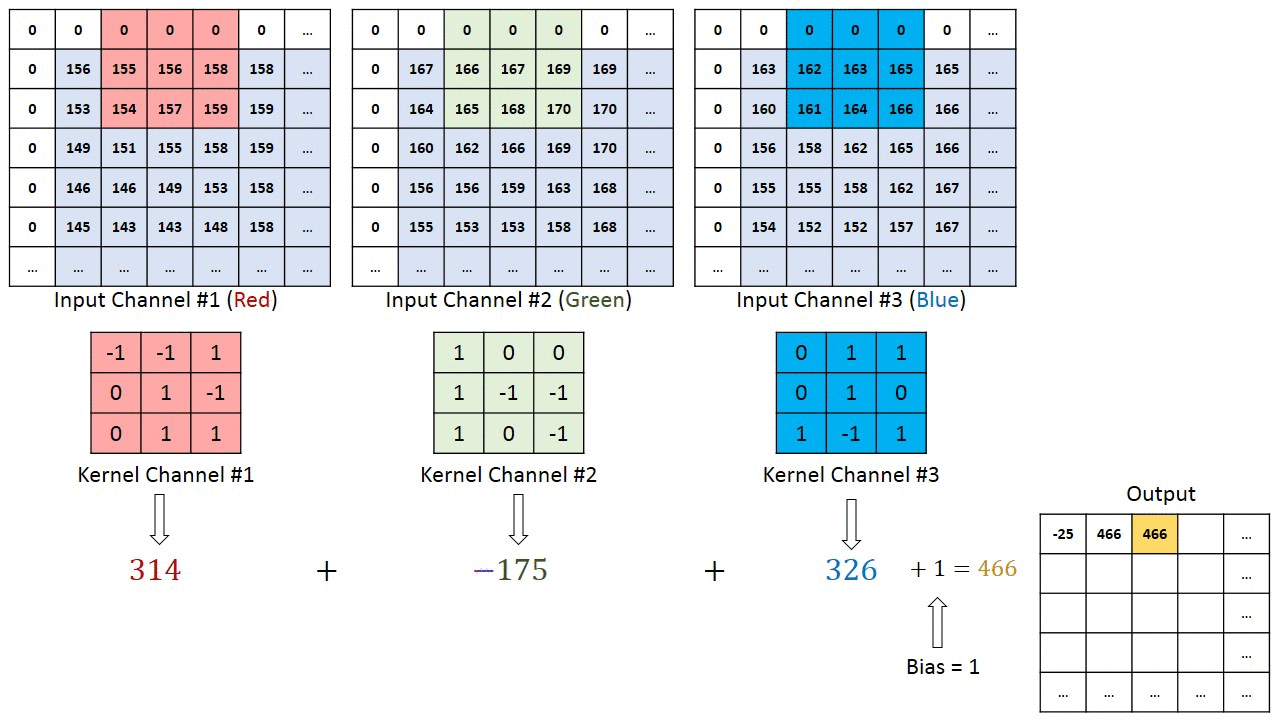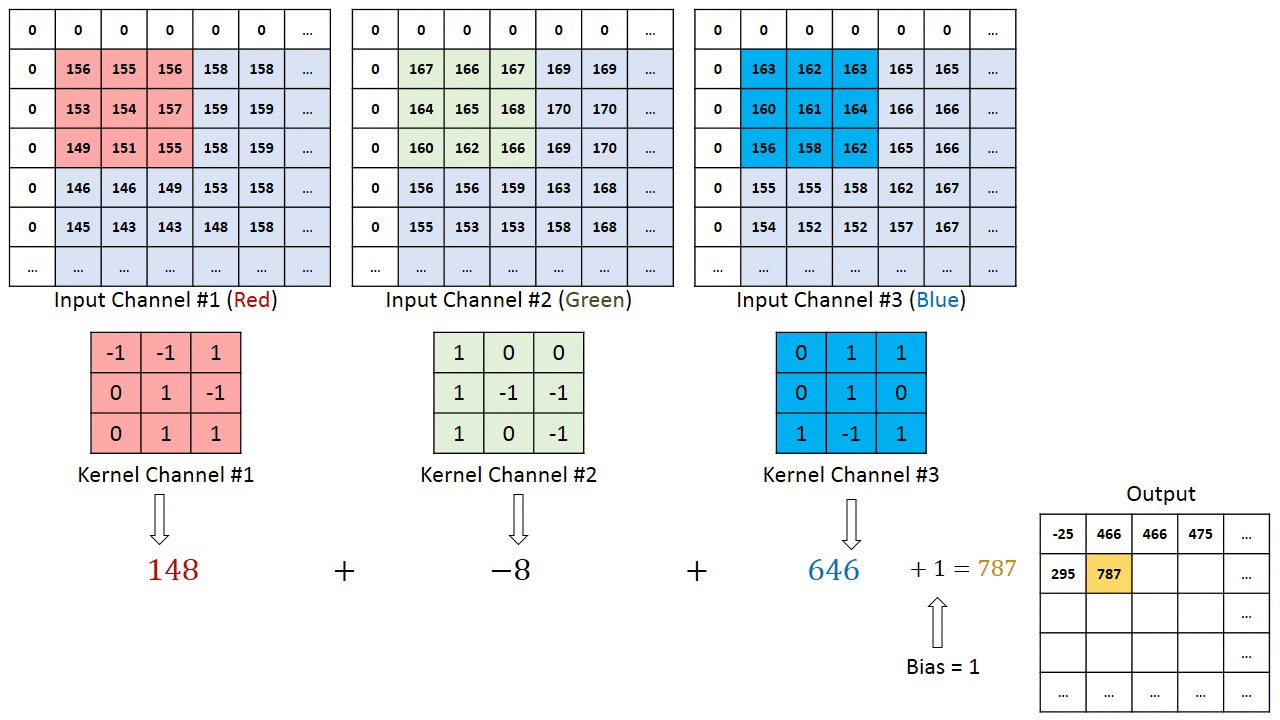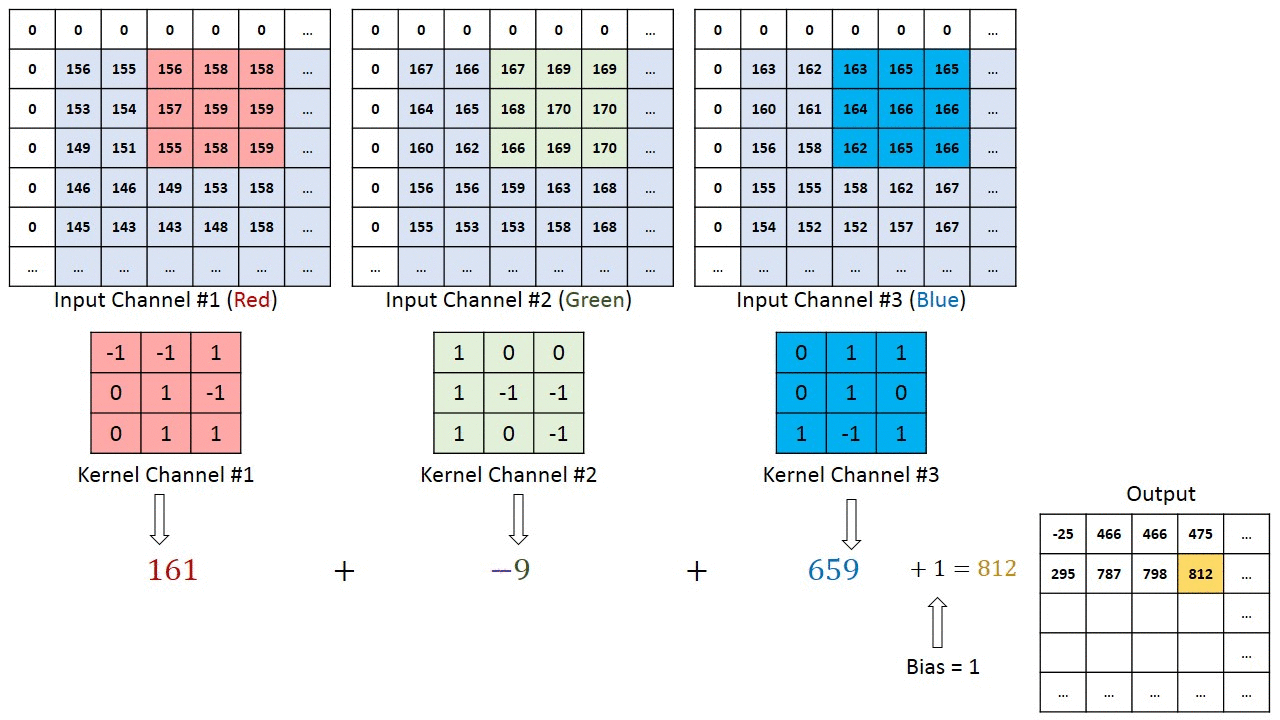
Dans le cas d’images à plusieurs canaux (par exemple RVB ), le noyau a la même profondeur que celle de l’image d’entrée. La multiplication matricielle est effectuée entre Kn et In stack (;;) et tous les résultats sont additionnés avec le biais pour nous donner un canal à une profondeur écrasé Sortie d’entités alambiquées.
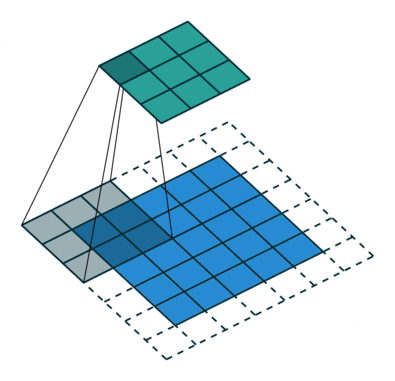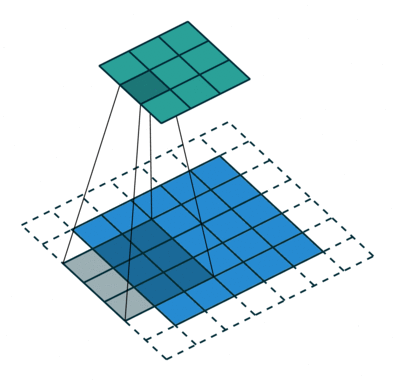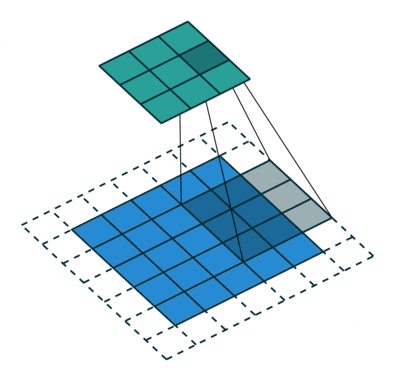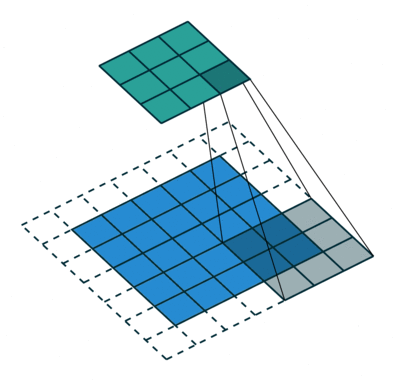
L’objectif de l’opération de convolution est d’extraire les fonctionnalités de haut niveau telles que les arêtes, à partir de l’image d’entrée. Les ConvNets n’ont pas besoin d’être limités à une seule couche convolutionnelle. Conventionnellement, le premier ConvLayer est chargé de capturer les fonctionnalités de bas niveau telles que les bords, la couleur, l’orientation du dégradé, etc. Avec des couches ajoutées, l’architecture s’adapte également aux fonctionnalités de haut niveau, nous donnant un réseau qui a la compréhension saine d’images dans l’ensemble de données, comme nous le ferions.
Il y a deux types de résultats à l’opération – l’un dans lequel l’entité convoluée est réduite en dimensionnalité par rapport à l’entrée, et l’autre dans lequel la dimensionnalité est augmentée ou reste la même. Cela se fait en appliquant un remplissage valide dans le cas du premier, ou même remplissage dans le cas du second.
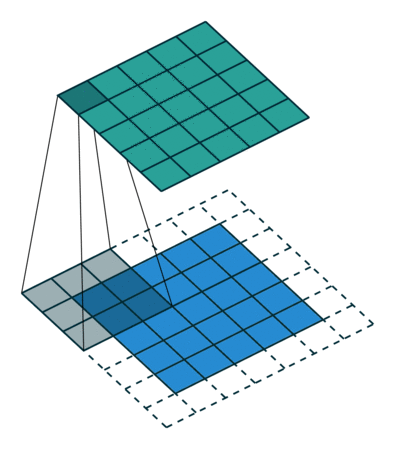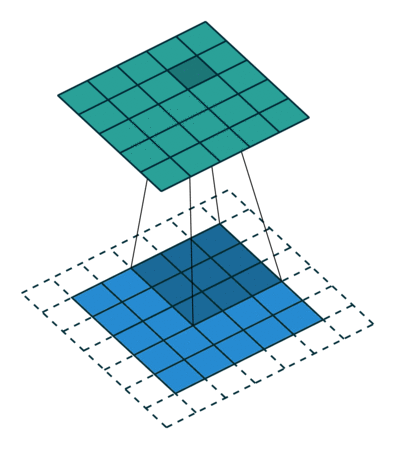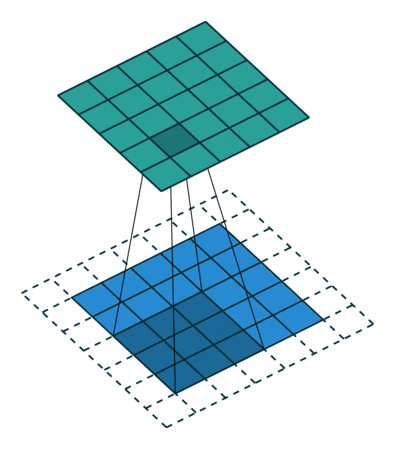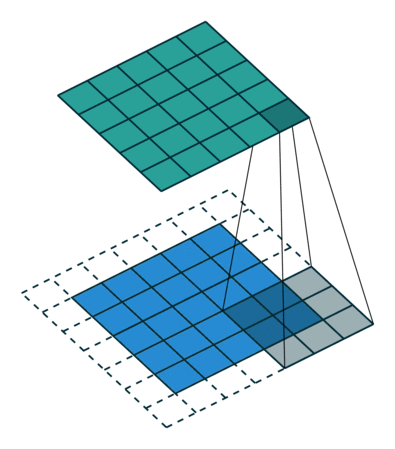
Lorsque nous augmentons l’image 5x5x1 en une image 6x6x1 puis appliquons le noyau 3x3x1 dessus, nous constatons la matrice convoluée se révèle être de dimensions 5x5x1. D’où le nom – Same Padding.
Par contre, si nous effectuons la même opération sans remplissage, on nous présente une matrice qui a les dimensions du noyau (3x3x1) lui-même – Valid Padding.
Le référentiel suivant contient de nombreux GIF de ce type qui vous aideraient à mieux comprendre comment Padding et Stride Length fonctionnent ensemble pour obtenir des résultats adaptés à nos besoins.
Pooling Layer
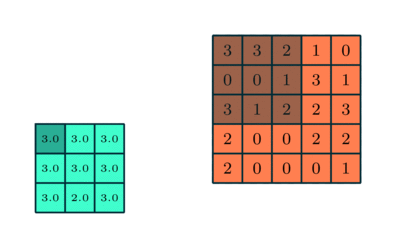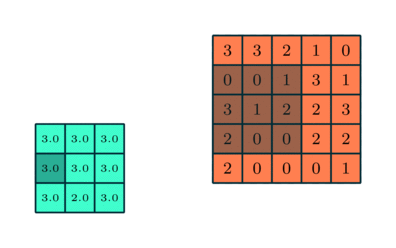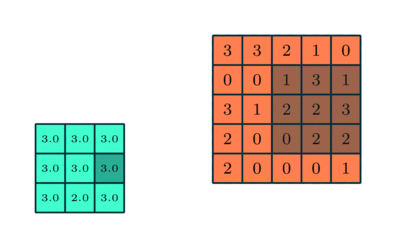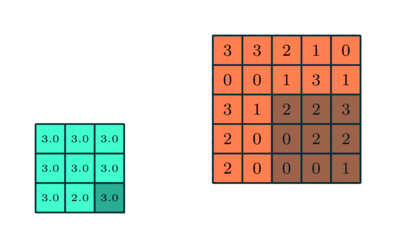
Semblable à la couche convolutionnelle, la couche de regroupement est responsable de la réduction de la taille spatiale de l’entité convoluée. Cela permet de réduire la puissance de calcul requise pour traiter les données grâce à la réduction de la dimensionnalité. De plus, il est utile pour extraire des caractéristiques dominantes qui sont invariantes en rotation et en position, conservant ainsi le processus d’entraînement efficace du modèle.
Il existe deux types de regroupement: le regroupement maximal et le regroupement moyen. Max Pooling renvoie la valeur maximale de la partie de l’image couverte par le noyau. D’autre part, Average Pooling renvoie la moyenne de toutes les valeurs de la partie de l’image couverte par le noyau.
Max Pooling fonctionne également comme un suppresseur de bruit. Il supprime complètement les activations bruyantes et effectue également la suppression du bruit avec la réduction de la dimensionnalité. D’autre part, Average Pooling effectue simplement une réduction de dimensionnalité comme un mécanisme de suppression du bruit. Par conséquent, nous pouvons dire que le regroupement maximal fonctionne bien mieux que le regroupement moyen.
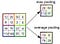
La couche convolutionnelle et la couche de regroupement forment ensemble la i-ème couche d’un réseau neuronal convolutif. En fonction de la complexité des images, le nombre de ces couches peut être augmenté pour capturer encore plus les détails de bas niveau, mais au prix d’une plus grande puissance de calcul.
Après avoir suivi le processus ci-dessus, nous avons a permis au modèle de comprendre les fonctionnalités. En poursuivant, nous allons aplatir la sortie finale et la transmettre à un réseau neuronal régulier à des fins de classification.
Classification – Couche entièrement connectée (couche FC)

L’ajout d’une couche entièrement connectée est un moyen (généralement) bon marché d’apprendre des combinaisons non linéaires des caractéristiques de haut niveau telles que représentées par la sortie de la couche convolutive. La couche Fully-Connected apprend une fonction peut-être non linéaire dans cet espace.
Maintenant que nous avons converti notre image d’entrée en une forme appropriée pour notre Perceptron à plusieurs niveaux, nous allons aplatir l’image en un vecteur colonne. La sortie aplatie est transmise à un réseau neuronal à rétroaction et une rétropropagation appliquée à chaque itération d’entraînement. Sur une série d’époques, le modèle est capable de faire la distinction entre les caractéristiques dominantes et certaines caractéristiques de bas niveau dans les images et de les classer à l’aide de la technique de classification Softmax.
Il existe différentes architectures de CNN disponibles qui ont joué un rôle clé dans construire des algorithmes qui alimenteront et alimenteront l’IA dans son ensemble dans un avenir prévisible. Certains d’entre eux ont été répertoriés ci-dessous:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
