Tekoäly on nähnyt monumentaalisen kasvun kuilun kaventamisessa ihmisten ja koneiden kykyjen välillä. Tutkijat ja harrastajat työskentelevät lukuisilla kentän osa-alueilla saadakseen aikaan hämmästyttäviä asioita. Yksi monista tällaisista alueista on Computer Vision -alue.
Tämän kentän agendana on antaa koneille mahdollisuus nähdä maailma ihmisinä, havaita se samalla tavalla ja jopa käyttää tietoa suurelle joukolle. tehtävistä, kuten Image & Videotunnistus, Kuvan analyysi & Luokittelu, Median virkistys, Suositusjärjestelmät, Luonnollisen kielen käsittely jne. in Computer Vision with Deep Learning on rakennettu ja täydennetty ajan myötä, pääasiassa yhdellä tietyllä algoritmilla – konvoluutiohermoverkolla.
Johdanto

Konvoluutiohermoverkko (ConvNet / CNN) on syvällinen oppiminen algoritmi, joka voi ottaa sisääntulokuvan, antaa merkityksen (oppimiskelpoinen) Painot ja painotukset) kuvan eri näkökohtiin / esineisiin ja pystyä erottamaan ne toisistaan. ConvNetissä vaadittu esikäsittely on paljon pienempi verrattuna muihin luokittelualgoritmeihin. Vaikka primitiivisissä menetelmissä suodattimet suunnitellaan käsin ja riittävän koulutuksen avulla, ConvNetsillä on kyky oppia nämä suodattimet / ominaisuudet.
ConvNetin arkkitehtuuri on analoginen ihmisen neuronien liitäntämallin kanssa. Aivot ja innoittamana Visual Cortexin organisaatio. Yksittäiset neuronit reagoivat ärsykkeisiin vain visuaalisen kentän rajoitetulla alueella, joka tunnetaan nimellä vastaanottokenttä. Kokoelma tällaisia kenttiä menee päällekkäin koko visuaalisen alueen kanssa.
Miksi ConvNets yli syötteen välittävien hermoverkkojen yli?

Kuva ei ole muuta kuin pikseliarvojen matriisi, eikö? Joten miksi ei vain tasoittaisi kuvaa (esim. 3×3-kuvamatriisi 9×1-vektoriksi) ja syötettäisi se monitasoiseen Perceptroniin luokittelua varten? Uh .. ei oikeastaan.
Erittäin yksinkertaisten binaarikuvien tapauksessa menetelmä saattaa näyttää keskimääräisen tarkkuustason luokkien ennustamisen yhteydessä, mutta sillä ei ole juurikaan tai ei lainkaan tarkkuutta kompleksisten kuvien suhteen, joissa on pikseliriippuvuuksia
ConvNet pystyy sieppaamaan onnistuneesti alueelliset ja ajalliset riippuvuudet kuvaan soveltuvien suodattimien avulla. Arkkitehtuuri soveltuu paremmin kuva-aineistoon johtuen parametrien määrän vähenemisestä ja painojen uudelleenkäytettävyydestä. Toisin sanoen verkko voidaan kouluttaa ymmärtämään kuvan hienostuneisuutta paremmin.
Syöttökuva

Kuvassa on RGB-kuva, joka on erotettu kolmella väritasolla – punainen, vihreä, ja sininen. On olemassa useita tällaisia väriavaruuksia, joissa kuvia on – harmaasävy, RGB, HSV, CMYK jne.
Voitte kuvitella, kuinka laskennallisesti intensiiviset asiat saisivat, kun kuvat saavuttavat mitat, esimerkiksi 8K (7680 × 4320). ConvNetin tehtävänä on pienentää kuvat muotoon, jota on helpompi käsitellä menettämättä ominaisuuksia, jotka ovat kriittisiä hyvän ennusteen saamiseksi. Tämä on tärkeää, kun aiomme suunnitella arkkitehtuurin, joka on paitsi hyvä ominaisuuksien oppimisessa, myös skaalautuva massiivisiin tietojoukoihin.
Convolution Layer – The Kernel
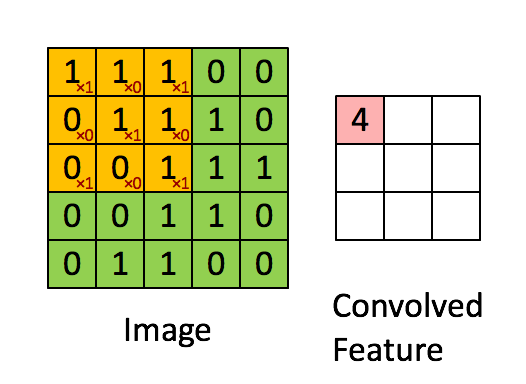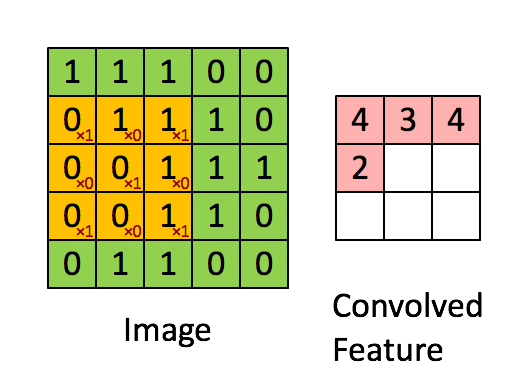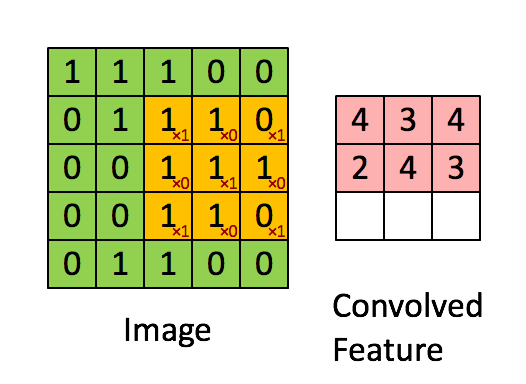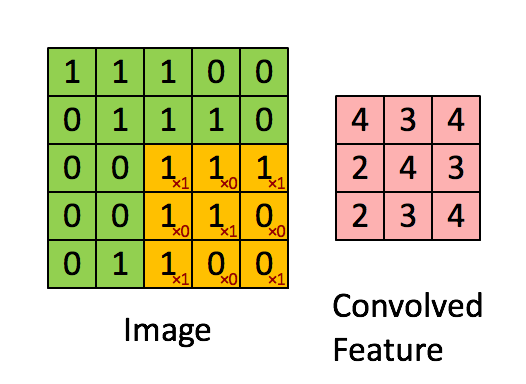
Kuva Mitat = 5 (korkeus) x 5 (leveys) x 1 (kanavien lukumäärä, esim. RGB)
Yllä olevassa esittelyssä vihreä osa muistuttaa 5x5x1-tulokuvaa I. Konvoluutiokerroksen ensimmäisen osan konvoluutiooperaatiota kutsutaan ytimeksi / suodattimeksi K, joka on edustettu keltaisella värillä. Olemme valinneet K 3x3x1-matriisiksi.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Ydin siirtyy 9 kertaa juoksupituus = 1 (ei-ohjattu) vuoksi joka kerta, kun suoritetaan matriisi. kertotoiminto K: n ja kuvan osan P välillä, jonka päällä ydin leijuu.

Suodatin siirtyy oikealle tietyllä Stride-arvolla, kunnes se jäsentää koko leveyden. Sieltä eteenpäin se hyppää kuvan alkuun (vasemmalle) samalla Stride-arvolla ja toistaa prosessia, kunnes koko kuva kulkee.
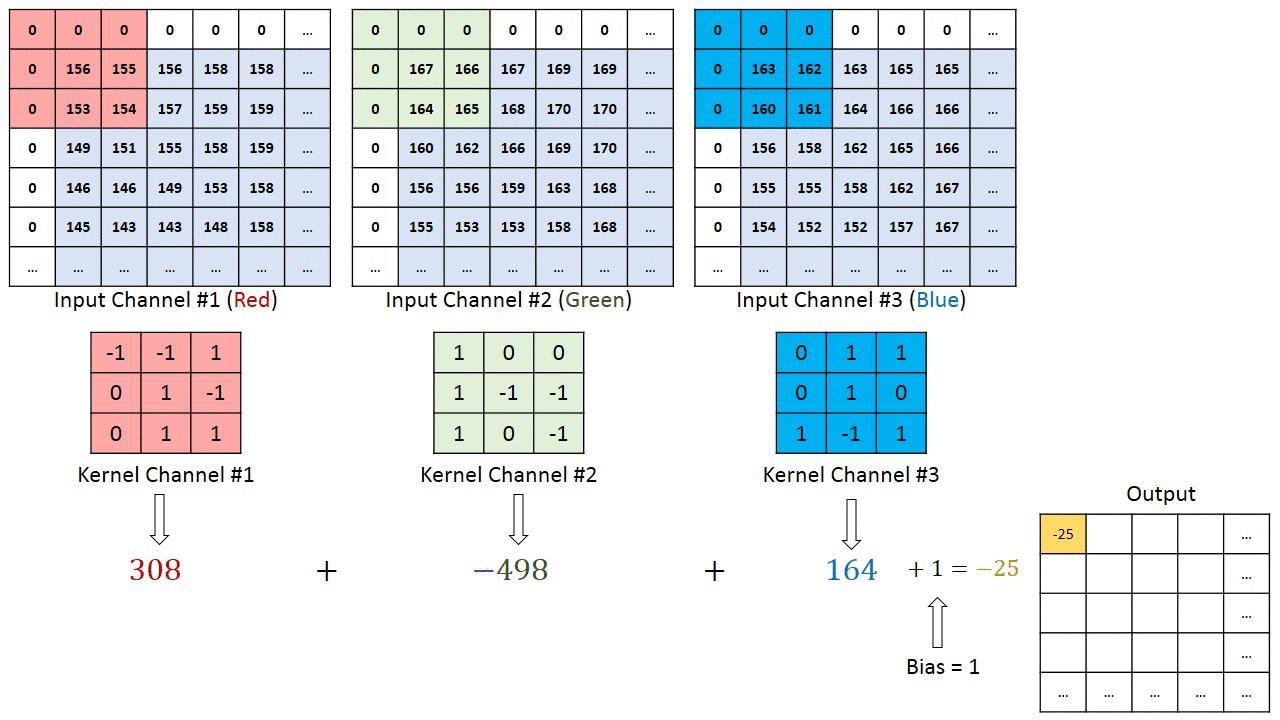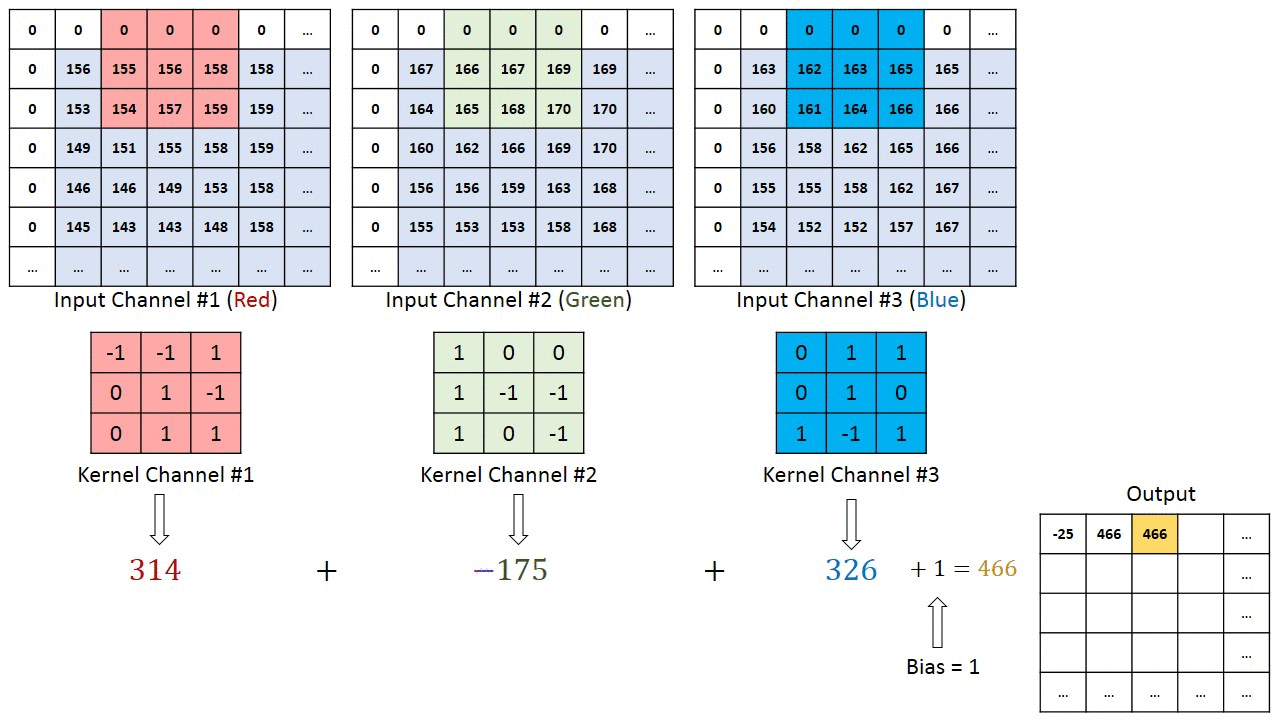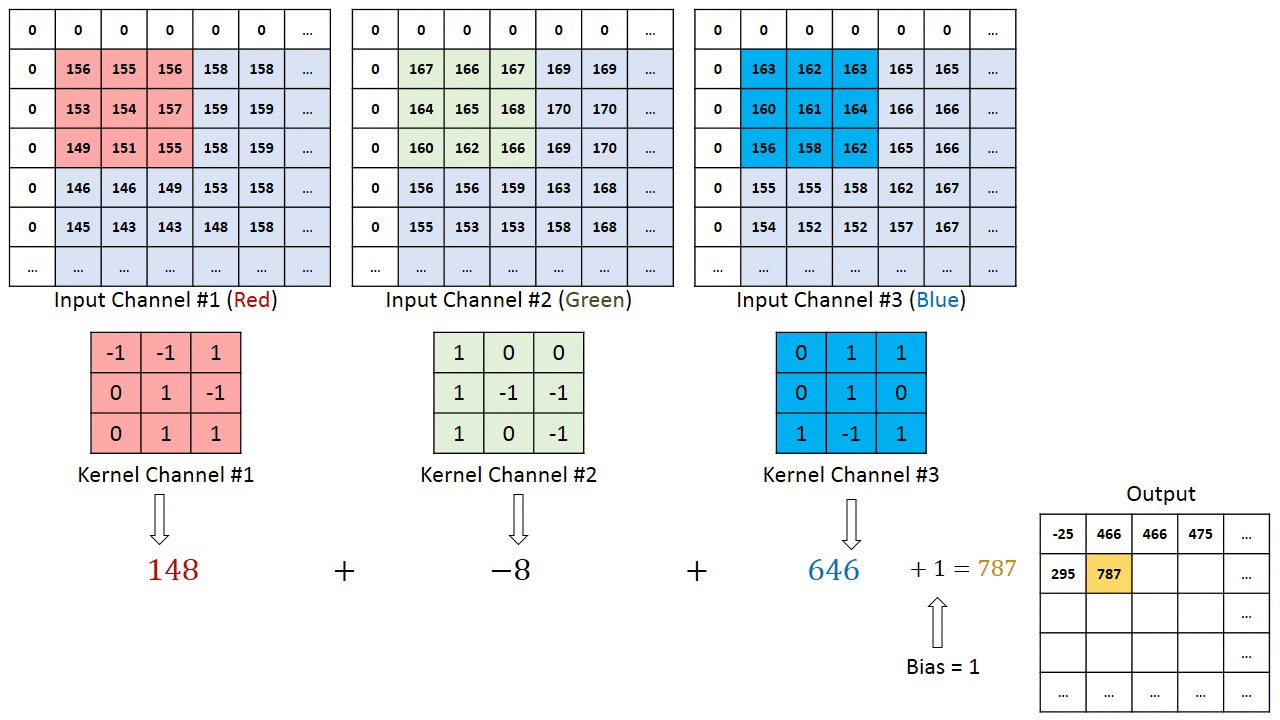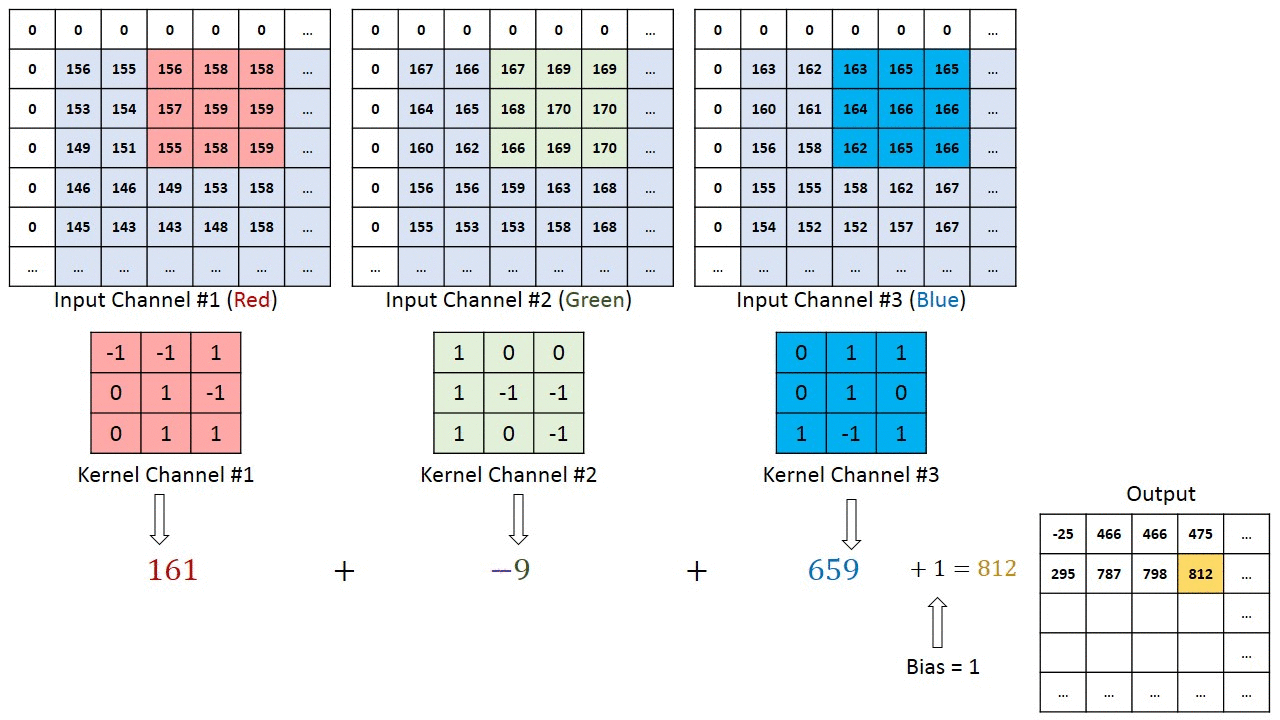
Jos kyseessä on monikanavainen kuva (esim. ), ytimen syvyys on sama kuin tulokuvan. Matriisikertolasku suoritetaan Kn: n ja pinon (;;) välillä ja kaikki tulokset summataan esijännityksellä, jotta saadaan puristettu yhden syvyyden kanava Kierretty ominaisuusulostulo.
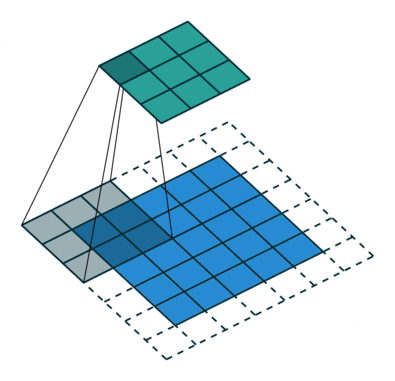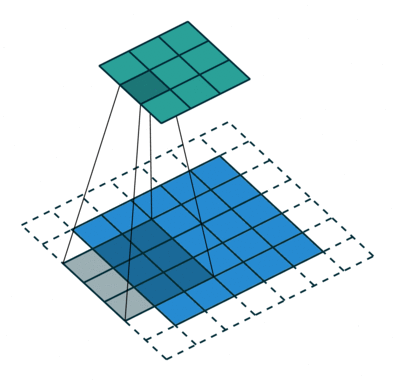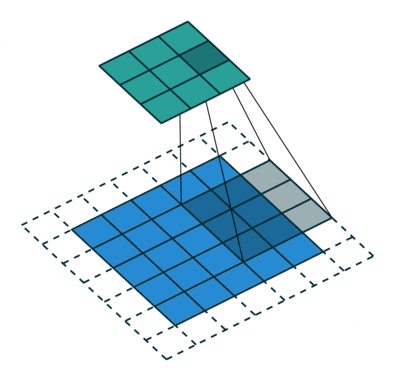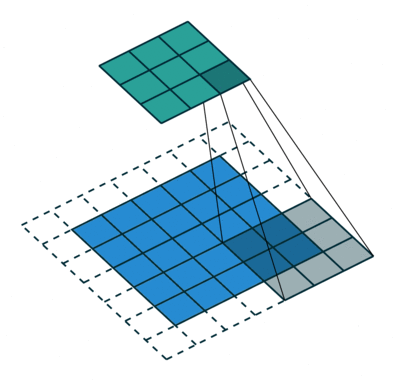
Konvoluutiotoiminnon tarkoituksena on purkaa korkean tason ominaisuudet, kuten reunat, tulokuvasta. ConvNets-verkkoja ei tarvitse rajoittaa vain yhteen konvoluutiokerrokseen. Perinteisesti ensimmäinen ConvLayer on vastuussa matalan tason ominaisuuksien, kuten reunojen, värin, kaltevuuden suunnan jne. Kaappaamisesta. Lisättyjen tasojen avulla arkkitehtuuri sopeutuu myös korkean tason ominaisuuksiin, mikä antaa meille verkon, joka ymmärtää terveellisesti kuvia tietojoukosta, samanlainen kuin tekisimme.
Toiminnalla on kahdenlaisia tuloksia – toisessa yhdistetyn ominaisuuden ulottuvuus pienenee tuloon verrattuna ja toinen jossa ulottuvuus joko kasvaa tai pysyy samana. Tämä tehdään soveltamalla kelvollista täytettä ensimmäisen tapauksessa tai samaa täyttöä jälkimmäisen tapauksessa.
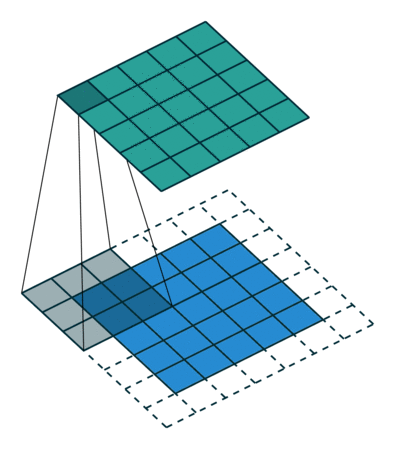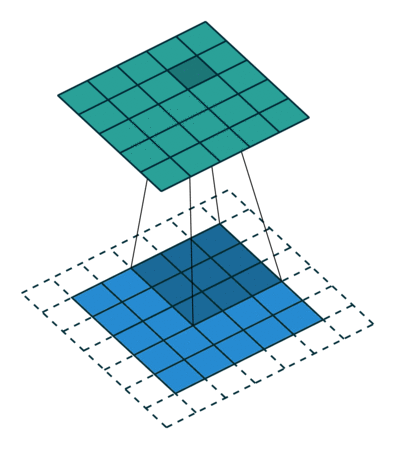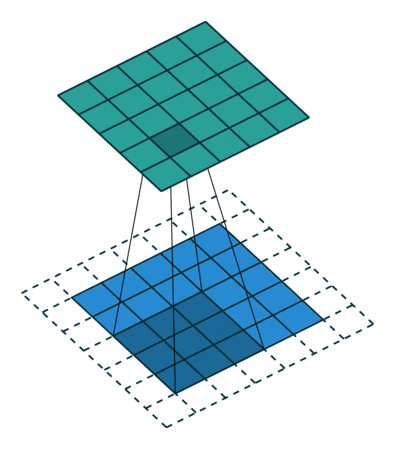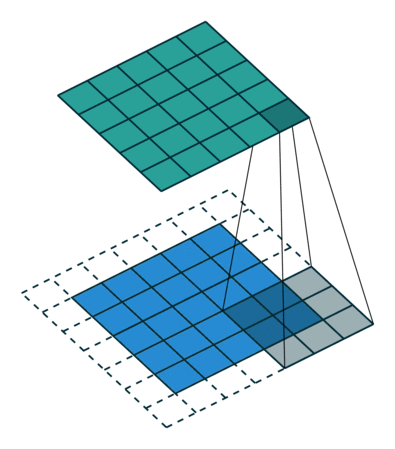
Kun kasvatamme 5x5x1-kuvaa 6x6x1-kuvaan ja käytämme sitten 3x3x1-ydintä sen päälle, havaitsemme, että sekoitettu matriisi osoittautuu kooltaan 5x5x1. Tästä syystä nimi – Sama täyte.
Toisaalta, jos suoritamme saman toiminnon ilman täyttöä, meille esitetään matriisi, jolla on itse ytimen (3x3x1) mitat – kelvollinen täyte.
Seuraavassa arkistossa on monia tällaisia GIF-tiedostoja, jotka auttavat sinua saamaan paremman käsityksen siitä, kuinka pehmuste ja askelpituus toimivat yhdessä saavuttaaksemme tarpeitamme vastaavia tuloksia.
Pooling Layer
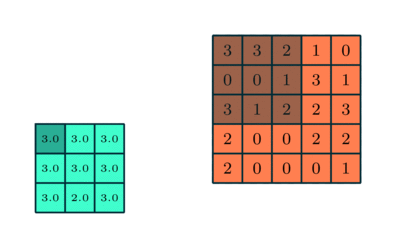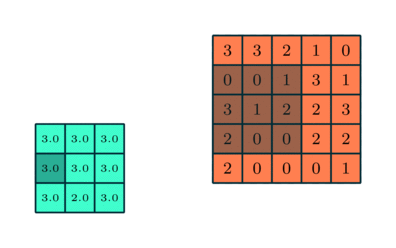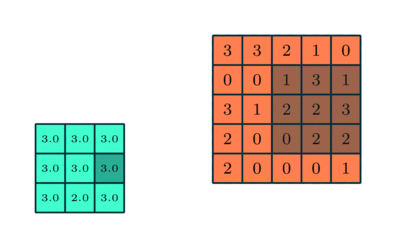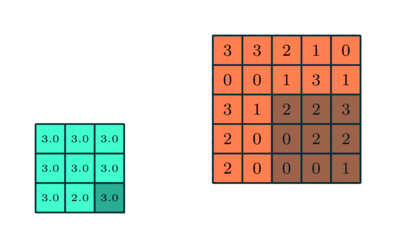
Samanlainen kuin Convolutional Layer, Pooling-kerros on vastuussa Convolved-ominaisuuden tilakoon pienentämisestä. Tämän tarkoituksena on vähentää datan käsittelyyn tarvittavaa laskentatehoa ulottuvuuden pienennyksen avulla. Lisäksi siitä on hyötyä hallitsevien ominaisuuksien poimimiselle, jotka ovat rotaatio- ja sijaintivariantteja, mikä ylläpitää mallin tehokkaan kouluttamisen prosessia.
Poolointia on kahta tyyppiä: Max Pooling ja Average Pooling. Max Pooling palauttaa maksimiarvon kuvan ytimen peittämästä osasta. Toisaalta Keskimääräinen yhdistäminen palauttaa kaikkien arvojen keskiarvon ytimen peittämästä kuvan osasta.
Max Pooling toimii myös melunvaimennimena. Se hylkää meluiset aktivaatiot kokonaan ja suorittaa myös melunvaimennuksen yhdessä ulottuvuuden vähentämisen kanssa. Toisaalta keskimääräinen poolointi yksinkertaisesti vähentää ulottuvuutta melua vaimentavana mekanismina. Siksi voimme sanoa, että Max Pooling toimii paljon paremmin kuin keskimääräinen pooling.
Konvoluutiokerros ja poolointikerros muodostavat yhdessä konvoluutiohermoverkon i-kerroksen. Kuvien monimutkaisuudesta riippuen tällaisten kerrosten määrää voidaan lisätä, jotta matalamman tason yksityiskohdat saadaan vielä pidemmälle, mutta enemmän laskentatehoa.
Yllä olevan prosessin läpi olemme saaneet onnistuneesti mahdollisti mallin ymmärtämään ominaisuuksia. Siirtymällä eteenpäin tasoitamme lopullisen tuotoksen ja syötämme sen säännölliseen hermoverkkoon luokittelua varten.
Luokitus – täysin yhdistetty kerros (FC-kerros)

Täysin yhdistetyn kerroksen lisääminen on (yleensä) halpa tapa oppia korkean tason ominaisuuksien epälineaarisia yhdistelmiä, kuten konvoluutiokerroksen tulos kuvaa. Täysin yhdistetty kerros oppii mahdollisesti ei-lineaarista funktiota siinä tilassa.
Nyt kun olemme muuttaneet tulokuvamme sopivaksi muodoksi monitasoiselle Perceptron-laitteellemme, tasoitamme kuvan sarakevektori. Tasoitettu ulostulo syötetään eteenpäin suuntautuvaan hermoverkkoon ja taaksekasvatus levitetään jokaiseen koulutuksen iteraatioon. Aikakausien aikana malli pystyy erottamaan kuvissa hallitsevat ja tietyt matalan tason piirteet ja luokittelemaan ne Softmax-luokittelutekniikan avulla.
Saatavilla on useita CNN-arkkitehtuureja, jotka ovat olleet avainasemassa rakennusalgoritmeja, jotka käyttävät ja käyttävät tekoälyä kokonaisuutena lähitulevaisuudessa. Jotkut heistä on lueteltu alla:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
