Künstliche Intelligenz hat ein enormes Wachstum bei der Überbrückung der Kluft zwischen den Fähigkeiten von Mensch und Maschine verzeichnet. Forscher und Enthusiasten arbeiten gleichermaßen an zahlreichen Aspekten des Fachgebiets, um erstaunliche Dinge geschehen zu lassen. Einer von vielen solchen Bereichen ist die Domäne des Computer Vision.
Die Agenda für dieses Feld besteht darin, Maschinen zu ermöglichen, die Welt wie Menschen zu betrachten, sie auf ähnliche Weise wahrzunehmen und das Wissen sogar für eine Vielzahl zu nutzen von Aufgaben wie Bild & Videoerkennung, Bildanalyse & Klassifizierung, Medienwiederherstellung, Empfehlungssysteme, Verarbeitung natürlicher Sprache usw. Die Fortschritte in Computer Vision mit Deep Learning wurde mit der Zeit konstruiert und perfektioniert, hauptsächlich über einen bestimmten Algorithmus – ein Convolutional Neural Network.
Einführung

Ein Convolutional Neural Network (ConvNet / CNN) ist ein Deep Learning Algorithmus, der ein Eingabebild aufnehmen kann, Wichtigkeit zuweisen (learnabl e Gewichte und Vorurteile) auf verschiedene Aspekte / Objekte im Bild und in der Lage sein, voneinander zu unterscheiden. Die in einem ConvNet erforderliche Vorverarbeitung ist im Vergleich zu anderen Klassifizierungsalgorithmen viel geringer. Während bei primitiven Methoden Filter von Hand entwickelt wurden und ausreichend geschult sind, können ConvNets diese Filter / Eigenschaften erlernen.
Die Architektur eines ConvNet entspricht der des Konnektivitätsmusters von Neuronen im Menschen Gehirn und wurde von der Organisation des Visual Cortex inspiriert. Einzelne Neuronen reagieren auf Reize nur in einem begrenzten Bereich des Gesichtsfeldes, der als Rezeptionsfeld bekannt ist. Eine Sammlung solcher Felder überlappt sich und deckt den gesamten visuellen Bereich ab.
Warum ConvNets über vorwärtsgerichtete neuronale Netze?

Ein Bild ist nichts anderes als eine Matrix von Pixelwerten, oder? Warum also nicht einfach das Bild abflachen (z. B. 3×3-Bildmatrix in einen 9×1-Vektor) und es zu Klassifizierungszwecken einem mehrstufigen Perzeptron zuführen? Äh … nicht wirklich.
In Fällen von extrem einfachen Binärbildern zeigt die Methode möglicherweise eine durchschnittliche Genauigkeit bei der Vorhersage von Klassen, hat jedoch bei komplexen Bildern mit Pixelabhängigkeiten nur eine geringe bis keine Genauigkeit
Ein ConvNet kann die räumlichen und zeitlichen Abhängigkeiten in einem Bild durch Anwendung relevanter Filter erfolgreich erfassen. Die Architektur passt sich aufgrund der Verringerung der Anzahl der beteiligten Parameter und der Wiederverwendbarkeit von Gewichten besser an den Bilddatensatz an. Mit anderen Worten, das Netzwerk kann trainiert werden, um die Komplexität des Bildes besser zu verstehen.
Eingabebild

In der Abbildung haben wir ein RGB-Bild, das durch seine drei Farbebenen getrennt wurde – Rot, Grün, und Blau. Es gibt eine Reihe solcher Farbräume, in denen Bilder existieren – Graustufen, RGB, HSV, CMYK usw.
Sie können sich vorstellen, wie rechenintensiv die Dinge werden würden, wenn die Bilder Dimensionen erreichen, beispielsweise 8K (7680 ×) 4320). Die Rolle des ConvNet besteht darin, die Bilder in eine Form zu reduzieren, die einfacher zu verarbeiten ist, ohne Funktionen zu verlieren, die für eine gute Vorhersage entscheidend sind. Dies ist wichtig, wenn wir eine Architektur entwerfen möchten, die nicht nur gut zum Lernen von Funktionen geeignet ist, sondern auch auf umfangreiche Datensätze skalierbar ist.
Faltungsschicht – Der Kernel
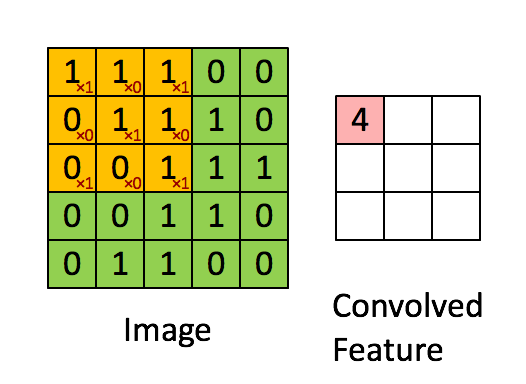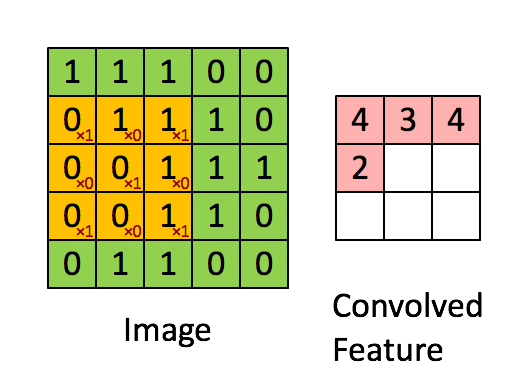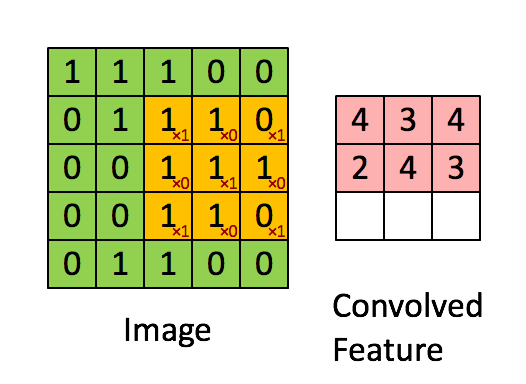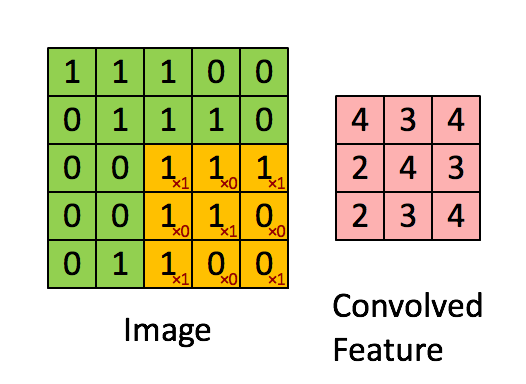
Bild Abmessungen = 5 (Höhe) x 5 (Breite) x 1 (Anzahl der Kanäle, z. B. RGB)
In der obigen Demonstration ähnelt der grüne Bereich unserem 5x5x1-Eingabebild I. Das am Tragen beteiligte Element Die Faltungsoperation im ersten Teil einer Faltungsschicht wird als Kernel / Filter K bezeichnet und in der Farbe Gelb dargestellt. Wir haben K als 3x3x1-Matrix ausgewählt.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Der Kernel verschiebt sich aufgrund der Schrittlänge = 1 (ohne Schritt) jedes Mal 9 Mal, wenn eine Matrix ausgeführt wird Multiplikationsoperation zwischen K und dem Teil P des Bildes, über dem der Kernel schwebt.

Der Filter bewegt sich nach rechts mit einem bestimmten Schrittwert, bis die gesamte Breite analysiert ist. Wenn Sie fortfahren, springt es mit demselben Schrittwert zum Anfang (links) des Bildes und wiederholt den Vorgang, bis das gesamte Bild durchlaufen wird.
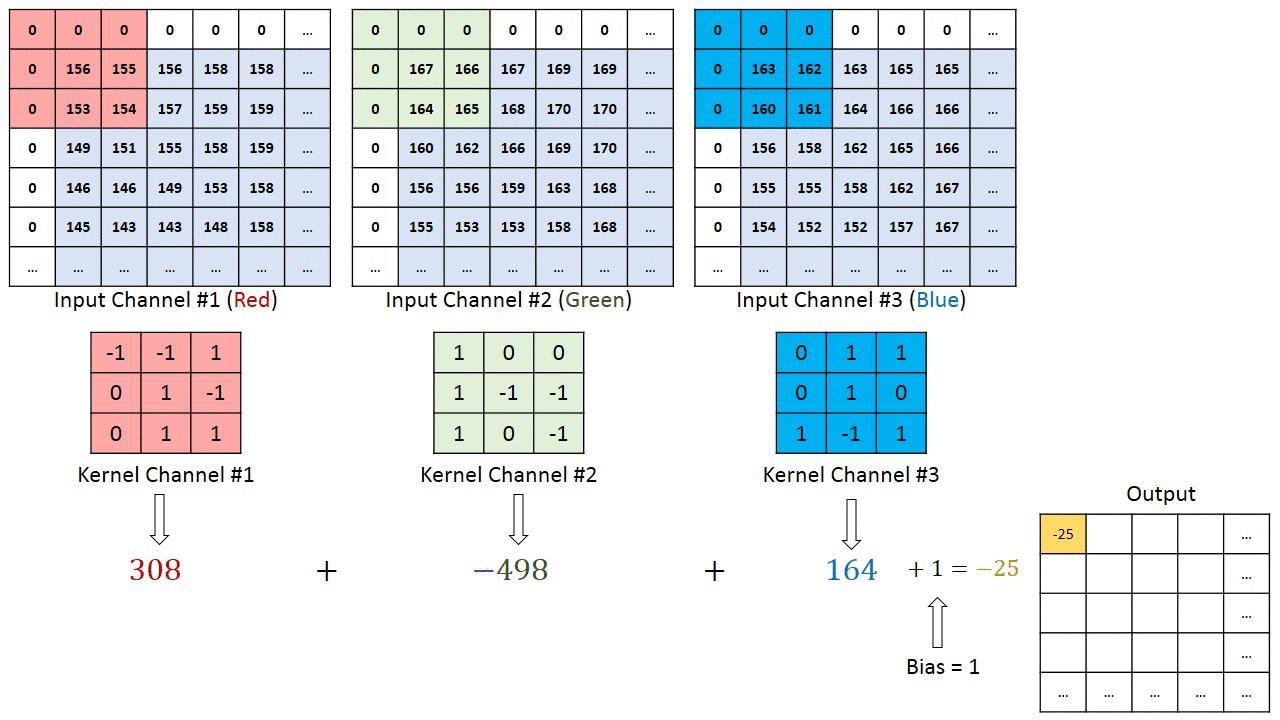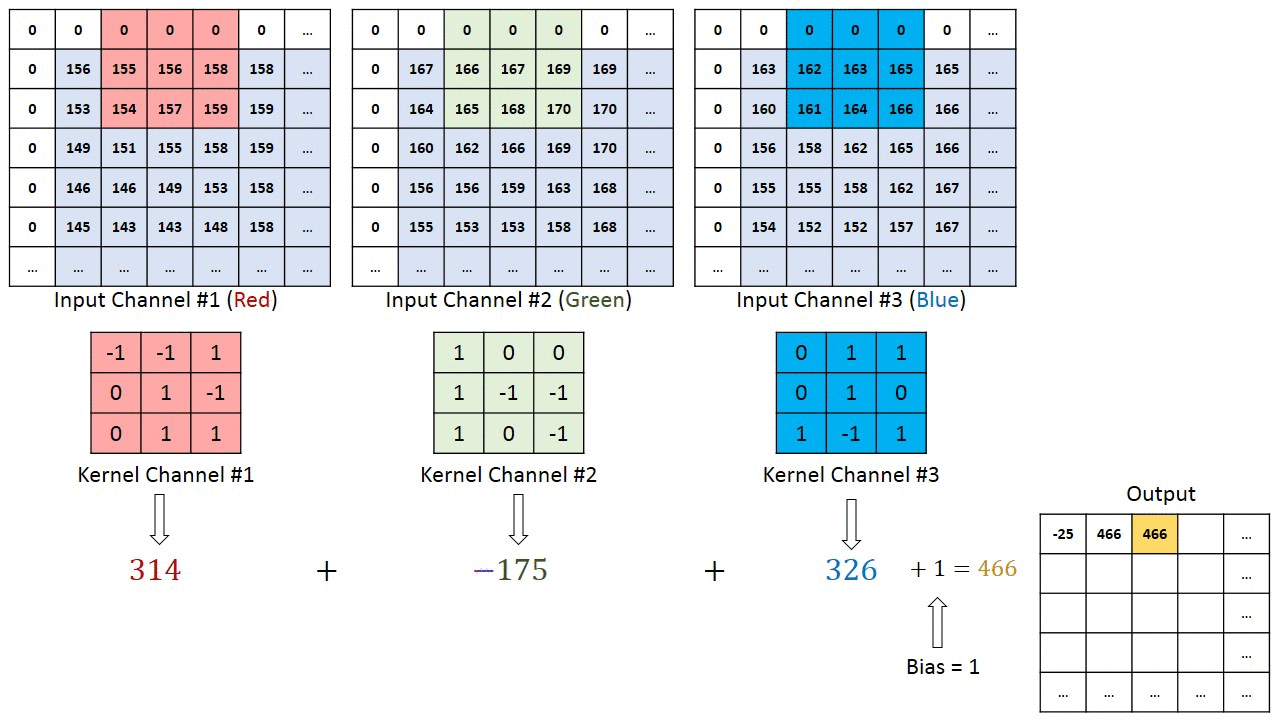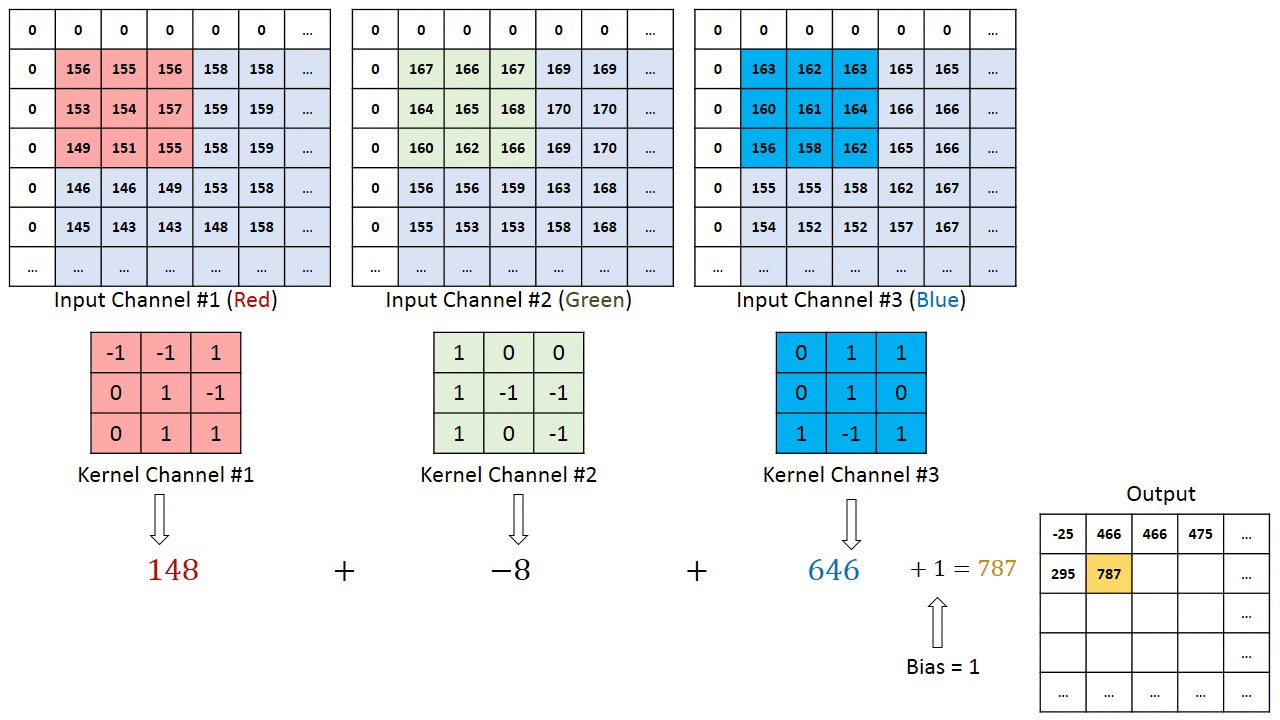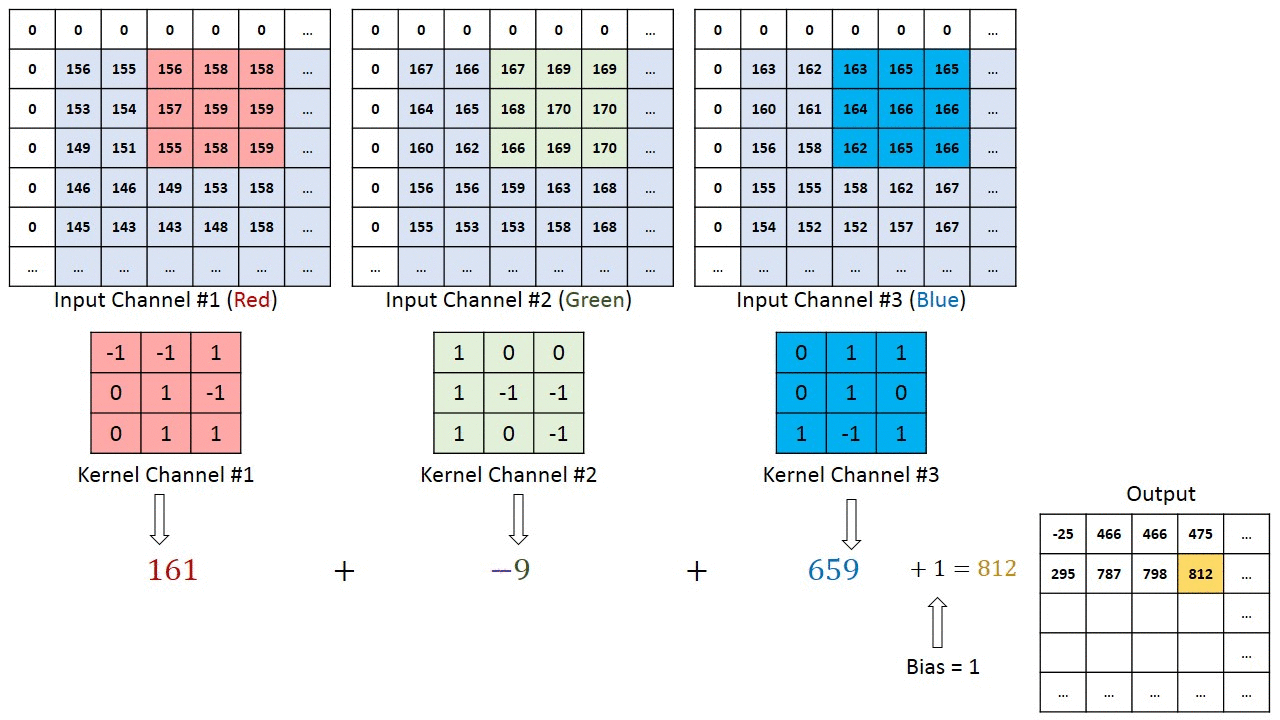
Bei Bildern mit mehreren Kanälen (z. B. RGB) ) hat der Kernel die gleiche Tiefe wie das Eingabebild. Die Matrixmultiplikation wird zwischen Kn und In-Stack (;;) durchgeführt, und alle Ergebnisse werden mit der Vorspannung summiert, um eine gequetschte Ausgabe eines Kanals mit verschlungenen Merkmalen zu erhalten.
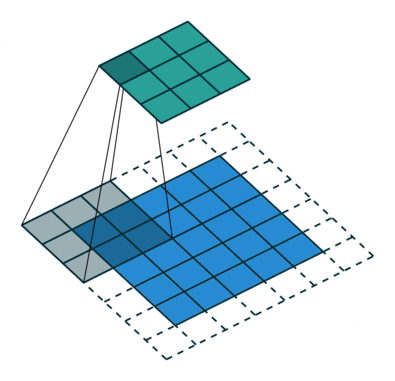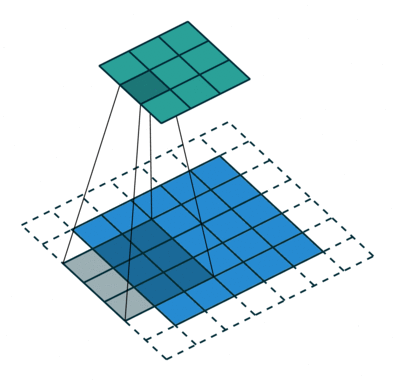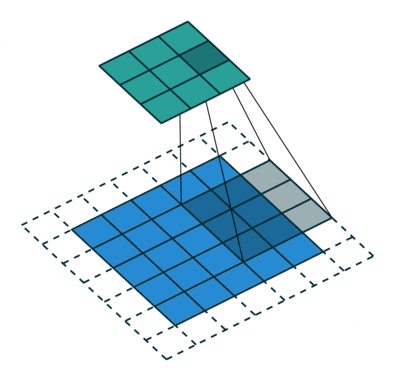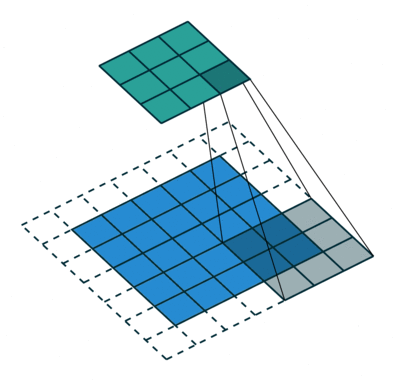
Das Ziel der Faltungsoperation besteht darin, die übergeordneten Merkmale wie Kanten zu extrahieren. aus dem Eingabebild. ConvNets müssen nicht nur auf eine Faltungsschicht beschränkt sein. Herkömmlicherweise ist der erste ConvLayer für die Erfassung der Low-Level-Funktionen wie Kanten, Farbe, Verlaufsausrichtung usw. verantwortlich. Mit hinzugefügten Ebenen passt sich die Architektur auch den High-Level-Funktionen an und gibt uns ein Netzwerk, das ein umfassendes Verständnis bietet von Bildern im Datensatz, ähnlich wie wir es tun würden.
Es gibt zwei Arten von Ergebnissen für die Operation – eine, bei der das Faltungsmerkmal im Vergleich zur Eingabe eine geringere Dimensionalität aufweist, und die andere, bei der Die Dimensionalität wird entweder erhöht oder bleibt gleich. Dies erfolgt durch Anwenden von Valid Padding bei ersteren oder Same Padding bei letzteren.
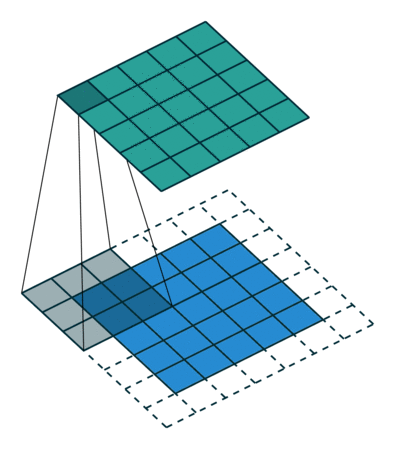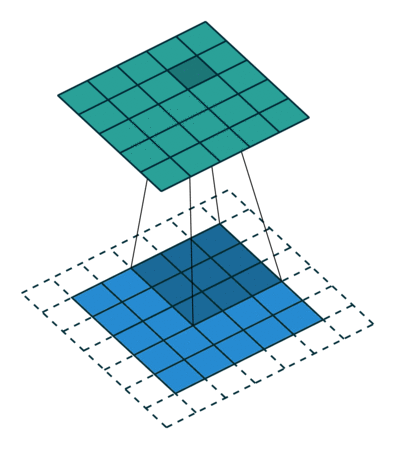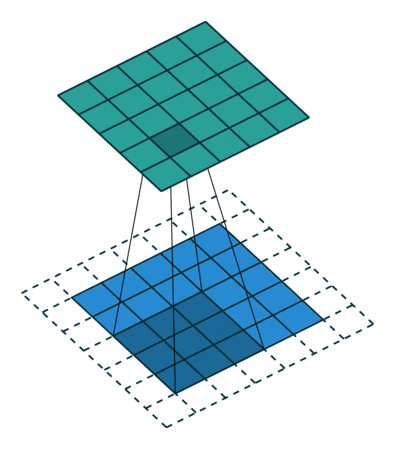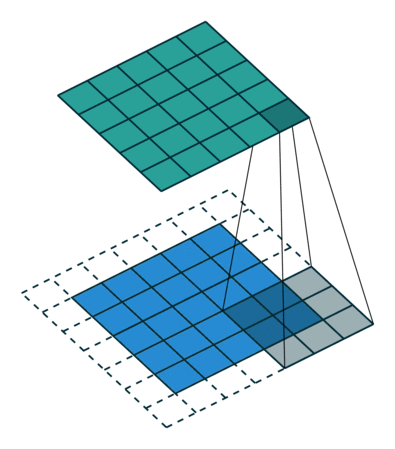
Wenn wir das 5x5x1-Bild in ein 6x6x1-Bild erweitern und dann den 3x3x1-Kernel darüber anwenden, stellen wir fest, dass das Die gefaltete Matrix hat die Abmessungen 5x5x1. Daher der Name – Same Padding.
Wenn wir andererseits dieselbe Operation ohne Padding ausführen, wird eine Matrix mit den Abmessungen des Kernels (3x3x1) selbst angezeigt – Valid Padding.
Das folgende Repository enthält viele solcher GIFs, mit denen Sie besser verstehen können, wie Polsterung und Schrittlänge zusammenarbeiten, um für unsere Anforderungen relevante Ergebnisse zu erzielen.
Pooling Layer
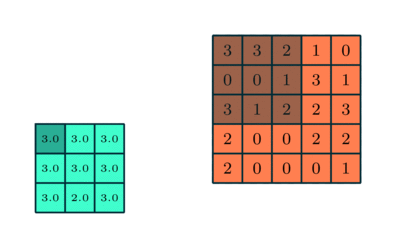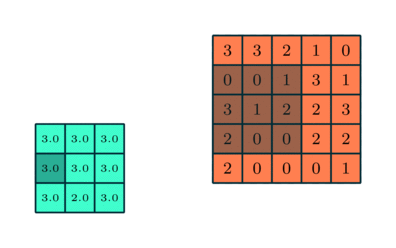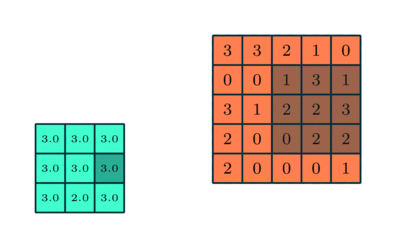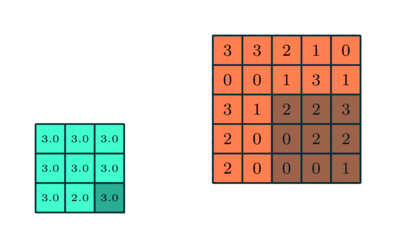
Ähnlich wie bei der Faltungsschicht die Pooling-Schicht ist für die Reduzierung der räumlichen Größe des Convolved Feature verantwortlich. Dies dient dazu, die Rechenleistung zu verringern, die erforderlich ist, um die Daten durch Dimensionsreduzierung zu verarbeiten. Darüber hinaus ist es nützlich, um dominante Merkmale zu extrahieren, die rotations- und positionsinvariant sind, wodurch der Prozess des effektiven Trainings des Modells aufrechterhalten wird.
Es gibt zwei Arten von Pooling: Max Pooling und Average Pooling. Max Pooling gibt den Maximalwert aus dem Teil des Bildes zurück, der vom Kernel abgedeckt wird. Auf der anderen Seite gibt Average Pooling den Durchschnitt aller Werte aus dem vom Kernel abgedeckten Teil des Bildes zurück.
Max Pooling fungiert auch als Rauschunterdrücker. Es verwirft die verrauschten Aktivierungen vollständig und führt neben der Dimensionsreduzierung auch eine Entrauschung durch. Andererseits führt Average Pooling einfach eine Dimensionsreduzierung als Rauschunterdrückungsmechanismus durch. Daher können wir sagen, dass Max Pooling viel besser abschneidet als Average Pooling.
Die Faltungsschicht und die Poolschicht bilden zusammen die i-te Schicht eines Faltungs-Neuronalen Netzwerks. Abhängig von der Komplexität der Bilder kann die Anzahl solcher Ebenen erhöht werden, um Details auf niedriger Ebene noch weiter zu erfassen, jedoch auf Kosten einer höheren Rechenleistung.
Nachdem wir den obigen Prozess durchlaufen haben, haben wir Das Modell konnte die Funktionen erfolgreich verstehen. In Zukunft werden wir die endgültige Ausgabe reduzieren und sie zu Klassifizierungszwecken einem regulären neuronalen Netz zuführen.
Klassifizierung – Vollständig verbundene Schicht (FC-Schicht)

Das Hinzufügen einer vollständig verbundenen Ebene ist eine (normalerweise) kostengünstige Methode zum Lernen nichtlinearer Kombinationen der Merkmale auf hoher Ebene, wie sie durch die Ausgabe der Faltungsschicht dargestellt werden. Die vollständig verbundene Ebene lernt in diesem Raum eine möglicherweise nichtlineare Funktion.
Nachdem wir unser Eingabebild in eine geeignete Form für unser mehrstufiges Perzeptron konvertiert haben, werden wir das Bild in eine reduzieren Spaltenvektor. Die abgeflachte Ausgabe wird einem neuronalen Feed-Forward-Netzwerk zugeführt, und die Backpropagation wird auf jede Trainingsiteration angewendet. Über eine Reihe von Epochen hinweg kann das Modell zwischen dominierenden und bestimmten Merkmalen auf niedriger Ebene in Bildern unterscheiden und diese mithilfe der Softmax-Klassifizierungstechnik klassifizieren.
Es stehen verschiedene Architekturen von CNNs zur Verfügung, die maßgeblich waren Erstellen von Algorithmen, die die KI in absehbarer Zeit als Ganzes antreiben und antreiben sollen. Einige von ihnen sind unten aufgeführt:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
