Introducción a la instrucción MERGE y la modificación de datos de SQL Server
La instrucción MERGE se utiliza para realizar cambios en una tabla en función de los valores coincidentes de otra. Se puede utilizar para combinar operaciones de inserción, actualización y eliminación en una sola declaración. En este artículo, exploraremos cómo usar la declaración MERGE. Analizamos algunas prácticas recomendadas, limitaciones y un resumen con varios ejemplos.
Este es el quinto artículo de una serie de artículos. Puede comenzar por el principio leyendo Introducción a las declaraciones de modificación de datos de SQL Server.
Todos los ejemplos de esta lección se basan en Microsoft SQL Server Management Studio y la base de datos AdventureWorks2012. Puede comenzar a usar estas herramientas gratuitas usando mi Guía Comenzando con SQL Server
Antes de comenzar
Aunque este artículo usa la base de datos AdventureWorks para sus ejemplos, he decidido crear Varias tablas de ejemplo para usar dentro de la base de datos para ayudar a ilustrar mejor los conceptos cubiertos. Puede encontrar la secuencia de comandos que necesitará ejecutar aquí. Observe que hay una sección especial relacionada con MERGE.
Estructura básica
La instrucción MERGE combina las operaciones INSERT, DELETE y UPDATE en una tabla. Una vez que comprenda cómo funciona, verá que simplifica el procedimiento con el uso de las tres declaraciones por separado para sincronizar datos.
A continuación se muestra un formato generalizado para la declaración de combinación.
MERGE targetTableUsing sourceTableON mergeConditionWHEN MATCHEDTHEN updateStatementWHEN NOT MATCHED BY TARGETTHEN insertStatementWHEN NOT MATCHED BY SOURCETHEN deleteStatement
La instrucción merge funciona usando dos tablas, sourceTable y targetTable. TargetTable es la tabla que se modificará en función de los datos contenidos en sourceTable.
Las dos tablas se comparan mediante una mergeCondition . Esta condición especifica cómo las filas de sourceTable se comparan con targetTable. Si está familiarizado con INNER JOINS, puede pensar en esto como la condición de unión utilizada para hacer coincidir filas.
Normalmente, coincidiría con un identificador único, como una clave principal. Si la tabla de origen era NewProduct y ProductMaster de destino y la clave principal para ambos ProductID, entonces una buena condición de combinación para usar sería:
NewProduct.ProductID = ProductMaster.ProductID
Se produce una condición de combinación en uno de tres estados: COINCIDIDO, NO COINCIDIDO o NO COINCIDIDO POR FUENTE.
Condiciones de fusión
Repasemos lo que significan las distintas condiciones:
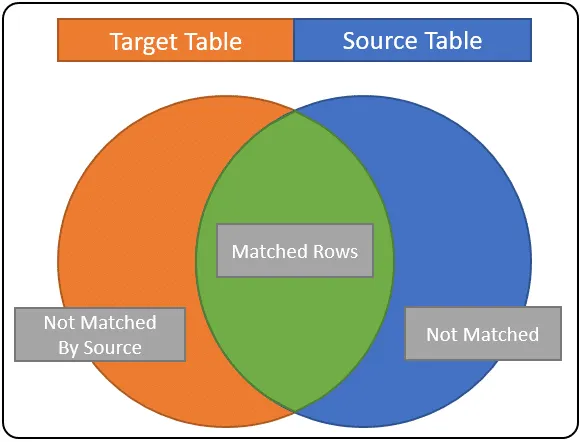
COINCIDIDO – estas son filas que satisfacen la condición de coincidencia. Son comunes a las tablas de origen y destino. En nuestro diagrama, se muestran en verde. Cuando utiliza esta condición en una declaración de fusión, usted; más como actualizar las columnas de la fila de destino con los valores de la columna sourceTable.
NOT MATCHED – Esto también se conoce como NOT MATCHED BY TARGET; son filas de la tabla de origen que no coinciden con ninguna fila de la tabla de destino. Estas filas están representadas por el área azul de arriba. En la mayoría de los casos, se puede utilizar para inferir que las Filas de origen deben agregarse a la tabla de destino.
NO COINCIDEN POR LA FUENTE: estas son filas de la tabla de destino que nunca coincidieron con un registro de origen; estas son las filas en el área naranja. Si su objetivo es sincronizar completamente los datos de targetTable con la fuente, entonces usará esta condición de coincidencia para ELIMINAR filas.
Si tiene problemas para entender cómo funciona esto, considere que la condición de fusión es como una condición de unión. Las FILAS de la sección verde representan filas que coinciden con la condición de combinación, las filas de la sección azul son aquellas que se encuentran en la tabla de origen, pero no en el destino. Las filas de la sección naranja son aquellas que se encuentran solo en el destino.
En estos escenarios coincidentes, puede incorporar fácilmente actividades de agregar, eliminar y actualizar en una sola declaración para sincronizar los cambios entre dos tablas.
Veamos un ejemplo.
Ejemplo MERGE
Supongamos que nuestro objetivo es sincronizar cualquier cambio realizado en esqlProductSource con esqlProductTarget. Aquí hay un diagrama de estas dos tablas:
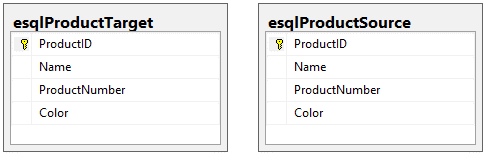
Nota: Por el bien de este ejemplo, ejecuté los scripts de los que hablé en la introducción para crear y completar dos tablas: esqlProductSource y esqlProductTarget.
Antes de construir la instrucción MERGE, veamos cómo sincronizaríamos la tabla usando la instrucción UPDATE, INSERT y DELETE para modificar, agregar y elimine filas en la tabla de destino.
Creo que una vez que vea cómo hacemos esto individualmente, entonces ver la combinación en una sola operación tiene más sentido.
Usar UPDATE para sincronizar cambios de una tabla a la siguiente
Para actualizar la tabla de destino con los valores modificados en la fuente del producto, podemos usar una instrucción UPDATE. Dado que ProductID es la clave principal de ambas tablas, se convierte en nuestra mejor opción para hacer coincidir filas entre las tablas.
Si fuéramos a actualizar los valores de las columnas en la tabla de destino usando la columna de origen, podríamos hacerlo usando la siguiente declaración de actualización
UPDATE esqlProductTargetSET Name = S.Name, ProductNumber = S.ProductNumber, Color = S.ColorFROM esqlProductTarget T INNER JOIN esqlProductSource S ON S.ProductID = T.ProductID
Esta declaración actualizará la columna en esqlProductTarget con los valores de columna correspondientes encontrados en esqlProductSource para que coincidan los ID de producto.
INSERTAR filas encontradas en una tabla pero no en la otra
Ahora veamos cómo puede identificar las filas de la tabla de origen que necesitamos insertar en la orientación del producto. Para hacer esto, podemos usar la subconsulta para encontrar filas en la tabla de origen que no están en el destino.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Nota: también podría usar una combinación externa hacer lo mismo. Si está interesado en saber por qué, consulte este artículo.
Esta declaración insertará una nueva fila en esqlProductTarget de todas las filas en esqlProductSource que no se encuentran en esqlProductTarget.
Eliminando Filas
La última actividad de sincronización que necesitamos hacer, elimina cualquier fila de la tabla de destino que no esté en la fuente SQL. Como hicimos con la declaración de inserción, usaremos una subconsulta. Pero esta vez identificaremos filas en esqlProductTarget que no se encuentran en esqlProductSource. Aquí está la declaración DELETE que podemos usar:
DELETE esqlProductTargetFROM esqlProductTarget TWHERE NOT EXISTS (SELECT S.ProductID FROM esqlProductSource S WHERE T.ProductID = S.ProductID)
Ahora que ha visto cómo hacer las distintas operaciones individualmente, veamos cómo se unen en el sentencia merge.
Observe que la mayor parte del trabajo pesado se realiza mediante la condición de fusión y sus resultados. En lugar de tener que configurar repetidamente la coincidencia, como hicimos en la instrucción delete, se hace una vez.
Compare nuevamente la instrucción Insert con la instrucción merge anterior.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Dado que la instrucción MERGE establece la tabla de origen y destino, así como también cómo coinciden, todo lo codificado por colores en rojo es redundante; por lo tanto, no en la parte de inserción de la combinación.
Registro de cambios MERGE usando OUTPUT
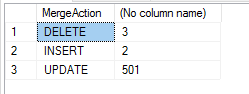
Puede usar la cláusula OUTPUT para registrar cualquier cambio. En este caso, la variable especial $ action se puede utilizar para registrar la acción de combinación. Esta variable tomará uno de tres valores: «INSERT», «UPDATE» o «DELETE».
Continuaremos usando nuestro ejemplo, pero esta vez registraremos los cambios y resumiremos el cambios.
Si lo anterior se ejecuta en datos de muestra nuevos, se genera el siguiente resumen: