Introduktion till MERGE Statement och SQL Server Data Modification
MERGE-setningen används för att göra ändringar i en tabell baserat på värden matchade från anther. Den kan användas för att kombinera infoga, uppdatera och ta bort operationer i ett uttalande. I den här artikeln kommer vi att undersöka hur man använder MERGE-uttalandet. Vi diskuterar några bästa metoder, begränsningar och sammanfattning med flera exempel.
Detta är den femte artikeln i en serie artiklar. Du kan börja från början med att läsa Introduktion till SQL Server Data Modification Statements.
Alla exempel för den här lektionen är baserade på Microsoft SQL Server Management Studio och AdventureWorks2012-databasen. Du kan komma igång med dessa gratisverktyg med hjälp av min guide Komma igång med SQL Server
Innan vi börjar
Även om den här artikeln använder AdventureWorks-databasen för sina exempel, har jag beslutat att skapa flera exempelstabeller för användning i databasen för att bättre illustrera de begrepp som omfattas. Du hittar skriptet du behöver köra här. Observera att det finns ett speciellt avsnitt som rör MERGE.
Grundstruktur
MERGE-uttalandet kombinerar INSERT-, DELETE- och UPDATE-operationer i en tabell. När du förstår hur det fungerar ser du att det förenklar proceduren med att använda alla tre påståenden för att synkronisera data.
Nedan följer ett generaliserat format för sammanslagningsuttalandet.
MERGE targetTableUsing sourceTableON mergeConditionWHEN MATCHEDTHEN updateStatementWHEN NOT MATCHED BY TARGETTHEN insertStatementWHEN NOT MATCHED BY SOURCETHEN deleteStatement
Sammanfogningsuttalandet fungerar med två tabeller, sourceTable och targetTable. Måltabellen är den tabell som ska modifieras baserat på data som finns i källtabellen.
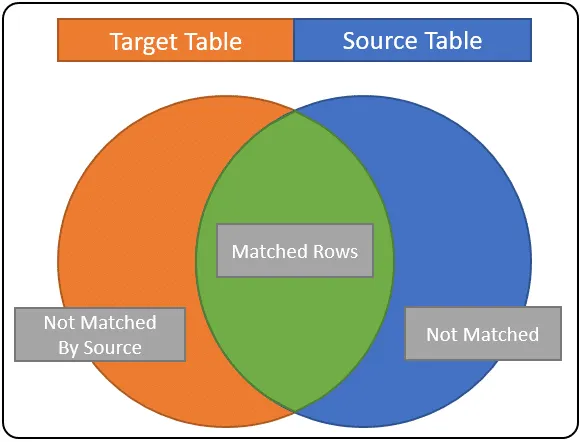
De två tabellerna jämförs med hjälp av en mergeCondition . Detta villkor anger hur rader från källtabellen matchas med måltabellen. Om du känner till INNER JOINS kan du tänka på detta som det kopplingsvillkor som används för att matcha rader.
Normalt skulle du matcha en unik identifierare, till exempel en primär nyckel. Om källtabellen var NewProduct och mål ProductMaster och den primära nyckeln för båda ProductID, skulle ett bra sammanslagningsvillkor vara:
NewProduct.ProductID = ProductMaster.ProductID
Ett sammanslagningsresultat resulterar i ett av tre tillstånd: MATCHED, NOT MATCHED eller NOT MATCHED BY SOURCE.
Sammanfoga villkor
Låt oss gå igenom vad de olika förhållandena betyder:
MATCHED – det här är rader som uppfyller matchvillkoret. De är gemensamma för både käll- och måltabellerna. I vårt diagram visas de som gröna. När du använder detta villkor i ett sammanslagningsmeddelande du; mest som att uppdatera målradkolumnerna med sourceTable-kolumnvärden.
NOT MATCHED – Detta är också känt som NOT MATCHED BY TARGET; det här är rader från källtabellen som inte matchade några rader i måltabellen. Dessa rader representeras av det blå området ovan. I de flesta fall kan man dra slutsatsen att källraderna ska läggas till i måltabellen.
INTE MATCHED OF SOURCE – det här är rader i måltabellen som aldrig matchades av en källpost; det här är raderna i det orange området. Om ditt mål är att helt synkronisera måltabeldata med källan använder du detta matchningsvillkor för att RADERA rader.
Om du har problem med att förstå hur detta fungerar, överväg att sammanslagningsvillkoret är som ett anslutningsvillkor. RADER i det gröna avsnittet representerar rader som matchar sammanslagningsvillkoret, rader i det blå avsnittet är de rader som finns i källtabellen, men inte i målet. Raderna i det orange avsnittet är de rader som bara finns i målet.
Ge dessa matchande scenarier, du kan enkelt införliva lägga till, ta bort och uppdatera aktiviteter i ett enda uttalande för att synkronisera ändringar mellan två tabeller.
Låt oss titta på ett exempel.
KOPPLA EXEMPEL
Låt oss anta att vårt mål är att synkronisera alla ändringar som görs i esqlProductSource med esqlProductTarget. Här är ett diagram över dessa två tabeller:
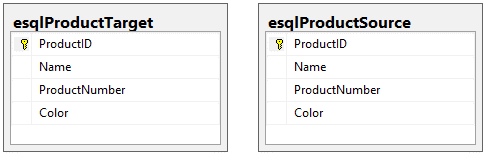
Obs! För detta exemplets skull körde jag de skript jag pratade om i inledningen för att skapa och fylla i två tabeller: esqlProductSource och esqlProductTarget.
Innan vi konstruerar MERGE-satsen, låt oss titta på hur vi skulle synkronisera tabellen med UPDATE, INSERT och DELETE-satsen för att ändra, lägga till , och ta bort rader i måltabellen.
Jag tror att när du förstår hur vi gör detta individuellt, är det mer meningsfullt att se kombinerat i en enda åtgärd.
Att använda UPPDATERING för att synkronisera ändringar från en tabell till nästa
För att uppdatera måltabellen med de ändrade värdena i produktkällan kan vi använda ett UPDATE-uttalande. Med tanke på att ProductID är båda tabellens primära nyckel blir det vårt bästa val matchningsrader mellan tabellerna.
Om vi skulle uppdatera kolumnvärdena i måltabellen med hjälp av källkolumnerna skulle vi kunna göra det med följande uppdateringsuttalande
UPDATE esqlProductTargetSET Name = S.Name, ProductNumber = S.ProductNumber, Color = S.ColorFROM esqlProductTarget T INNER JOIN esqlProductSource S ON S.ProductID = T.ProductID
Detta uttalande kommer att uppdatera kolumnen i esqlProductTarget med motsvarande kolumnvärden som finns i esqlProductSource för matchande produkt-ID. kan identifiera raderna från källtabellen som vi behöver infoga i produktmålet. För att göra detta kan vi använda underfrågan för att hitta rader i källtabellen som inte finns i målet.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Obs! Jag kan också använda en yttre koppling att göra detsamma. Om du är intresserad av varför, kolla in den här artikeln.
Detta uttalande infogar en ny rad i esqlProductTarget från alla rader i esqlProductSource som inte finns i esqlProductTarget.
Tar bort Rader
Den senaste synkroniseringsaktiviteten vi behöver göra tar bort alla rader i måltabellen som inte finns i SQL Source. Som vi gjorde med infogningsuttalandet använder vi en underfråga. Men den här gången kommer vi att identifiera rader i esqlProductTarget som inte finns i esqlProductSource. Här är DELETE-uttalandet vi kan använda:
DELETE esqlProductTargetFROM esqlProductTarget TWHERE NOT EXISTS (SELECT S.ProductID FROM esqlProductSource S WHERE T.ProductID = S.ProductID)
Nu när du har sett hur man gör de olika operationerna individuellt, kan vi se hur de kommer samman i Sammanfoga uttalande.
Observera att det mesta av tunga lyft görs av sammanslagningsvillkoret och dess resultat. I stället för att behöva ställa in matchningen upprepade gånger, som vi gjorde med borttagningsuttrycket, görs det en gång.
Jämför igen infoga uttalandet med sammanfogningsuttalandet ovan.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Med tanke på MERGE-uttalandet fastställs käll- och måltabellen, liksom hur de matchar, är allt färgkodat i rött överflödigt. därför inte i insatsdelen av sammanslagningen.
Logga MERGE Ändringar med OUTPUT
Du kan använda OUTPUT-satsen för att logga alla ändringar. I detta fall kan den speciella variabeln $ $ användas för att logga sammanfogningsåtgärden. Denna variabel tar ett av tre värden: ”INSERT”, ”UPDATE” eller ”DELETE”.
Vi fortsätter att använda vårt exempel, men den här gången loggar vi ändringarna och sammanfattar ändras.
Om ovanstående körs på färska exempeldata genereras följande sammanfattning: