Úvod do prohlášení o sloučení a úpravě dat serveru SQL
Příkaz Sloučení se používá k provádění změn v jedné tabulce na základě hodnot odpovídajících prašníku. Lze jej použít ke spojení operací vložení, aktualizace a odstranění do jednoho příkazu. V tomto článku prozkoumáme, jak používat prohlášení SLOUČENÍ. Diskutujeme o některých osvědčených postupech, omezeních a shrnutí s několika příklady.
Toto je pátý článek v řadě článků. Můžete začít na začátku přečtením Úvod k příkazům k úpravám dat na serveru SQL.
Všechny příklady této lekce jsou založeny na Microsoft SQL Server Management Studio a databázi AdventureWorks2012. Tyto bezplatné nástroje můžete začít používat pomocí mého průvodce Začínáme s používáním serveru SQL Server
Než začneme
Ačkoli tento článek používá pro své příklady databázi AdventureWorks, rozhodl jsem se vytvořit několik příkladů tabulek pro použití v databázi, které vám pomohou lépe ilustrovat pojaté koncepty. Zde najdete skript, který budete potřebovat ke spuštění. Všimněte si, že ke SLOUČENÍ existuje speciální sekce.
Základní struktura
Příkaz SLOUČENÍ kombinuje operace INSERT, DELETE a UPDATE do jedné tabulky. Jakmile pochopíte, jak to funguje, uvidíte, že to zjednodušuje postup při použití všech tří příkazů samostatně k synchronizaci dat.
Níže je uveden obecný formát příkazu sloučení.
MERGE targetTableUsing sourceTableON mergeConditionWHEN MATCHEDTHEN updateStatementWHEN NOT MATCHED BY TARGETTHEN insertStatementWHEN NOT MATCHED BY SOURCETHEN deleteStatement
Příkaz sloučení funguje pomocí dvou tabulek, sourceTable a targetTable. TargetTable je tabulka, která má být upravena na základě dat obsažených ve zdrojové tabulce.
Tyto dvě tabulky jsou porovnávány pomocí mergeCondition . Tato podmínka určuje, jak se řádky ze zdrojové tabulky shodují s cílovou tabulkou. Pokud jste obeznámeni s INNER JOINS, můžete si to představit jako podmínku spojení použitou ke shodě řádků.
Obvykle byste odpovídali jedinečnému identifikátoru, například primárnímu klíči. Pokud byla zdrojová tabulka NewProduct a cílová ProductMaster a primární klíč pro oba ID produktu, pak by dobrá slučovací podmínka byla:
NewProduct.ProductID = ProductMaster.ProductID
Výsledky podmínky sloučení v jednom ze tří stavů: MATCHED, NOT MATCHED, or NOT MATCHED BY SOURCE.
Sloučit podmínky
Pojďme si představit, co znamenají různé podmínky:
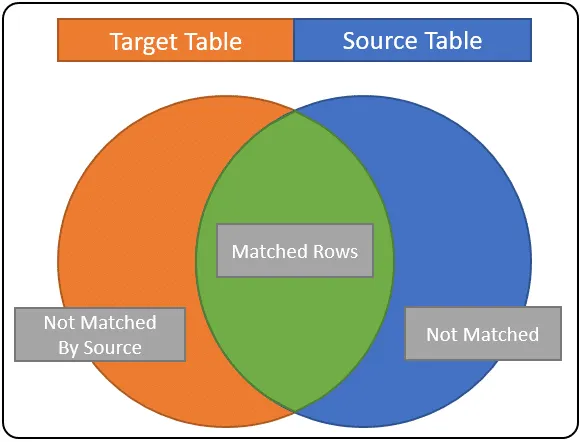
MATCHED – to jsou řádky splňující podmínku shody. Jsou společné pro zdrojovou i cílovou tabulku. V našem diagramu jsou zobrazeny zeleně. Když použijete tuto podmínku v prohlášení o fúzi, vy; nejraději aktualizujete sloupce cílového řádku hodnotami sloupců sourceTable.
NENÍ SOUVISEJÍCÍ – Toto se také označuje jako NENÍ SROVNÁVÁNO CÍLEM; jedná se o řádky ze zdrojové tabulky, které neodpovídají žádným řádkům v cílové tabulce. Tyto řádky jsou reprezentovány modrou oblastí nahoře. Ve většině případů lze použít k odvození toho, že zdrojové řádky by měly být přidány do tabulky targetTable.
NENÍ SOUVISEJÍCÍ ZDROJ – jedná se o řádky v cílové tabulce, které se zdrojovým záznamem nikdy neshodují; to jsou řádky v oranžové oblasti. Pokud je vaším cílem úplná synchronizace dat targetTable se zdrojem, použijete tuto podmínku shody k VYMAZÁNÍ řádků.
Pokud máte potíže s porozuměním, jak to funguje, zvažte, zda je podmínka sloučení podobná podmínka spojení. ŘÁDKY v zelené části představují řádky, které odpovídají podmínce sloučení, řádky v modré části jsou řádky nalezené v SourceTable, ale ne v cíli. Řádky v oranžové části jsou řádky, které se nacházejí pouze v cíli.
Když dáte tyto odpovídající scénáře, budete moci snadno začlenit aktivity přidání, odebrání a aktualizace do jednoho příkazu, abyste synchronizovali změny mezi dvěma tabulky.
Podívejme se na příklad.
Sloučit příklad
Předpokládejme, že naším cílem je synchronizovat všechny změny provedené v esqlProductSource s esqlProductTarget. Zde je schéma těchto dvou tabulek:
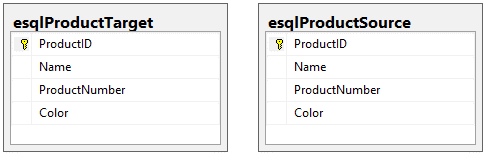
Poznámka: Kvůli tomuto příkladu jsem spustil skripty, o kterých jsem mluvil v úvodu k vytvoření a naplnění dvou tabulek: esqlProductSource a esqlProductTarget.
Než vytvoříme příkaz SLOUČENÍ, podívejme se, jak bychom synchronizovali tabulku pomocí příkazu UPDATE, INSERT a DELETE, který chcete upravit, přidat , a odeberte řádky v cílové tabulce.
Myslím, že jakmile uvidíte, jak to děláme jednotlivě, pak dává větší smysl vidět sloučení do jedné operace.
Použití UPDATE k synchronizaci změn od jedné tabulky k další
K aktualizaci cílové tabulky se změněnými hodnotami ve zdroji produktu můžeme použít příkaz UPDATE. Vzhledem k tomu, že ProductID je primárním klíčem obou tabulek, stal se naší nejlepší volbou shody řádků mezi tabulkami.
Pokud bychom se chystali aktualizovat hodnoty sloupců v cílové tabulce pomocí zdrojového sloupce, mohli bychom to udělat pomocí následujícího aktualizačního prohlášení
UPDATE esqlProductTargetSET Name = S.Name, ProductNumber = S.ProductNumber, Color = S.ColorFROM esqlProductTarget T INNER JOIN esqlProductSource S ON S.ProductID = T.ProductID
Toto prohlášení aktualizuje sloupec v esqlProductTarget odpovídajícími hodnotami sloupců nalezenými v esqlProductSource pro shodu productID.
INSERT Rows Found in one Table but Not the Other
Podívejme se, jak jsme může identifikovat řádky ze zdrojové tabulky, které musíme vložit do cíle produktu. K tomu můžeme použít poddotaz k vyhledání řádků ve zdrojové tabulce, které nejsou v cíli.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Poznámka: Mohl bych také použít vnější spojení udělat totéž. Pokud vás zajímá proč, podívejte se na tento článek.
Toto prohlášení vloží nový řádek do esqlProductTarget ze všech řádků v esqlProductSource, které se nenacházejí v esqlProductTarget.
Odebrání Řádky
Tato poslední synchronizační aktivita, kterou musíme udělat, odstraní všechny řádky v cílové tabulce, které nejsou ve zdroji SQL. Stejně jako v případě příkazu insert použijeme poddotaz. Tentokrát ale v esqlProductTarget nenajdeme řádky idenfity v esqlProductSource. Tady je příkaz DELETE, který můžeme použít:
DELETE esqlProductTargetFROM esqlProductTarget TWHERE NOT EXISTS (SELECT S.ProductID FROM esqlProductSource S WHERE T.ProductID = S.ProductID)
Nyní, když jste viděli, jak provádět různé operace jednotlivě, se podívejme, jak se spojí v prohlášení o sloučení.
Všimněte si, že většina těžkého zvedání se provádí podmínkou sloučení a jejími výsledky. Spíše než opakované nastavování shody, jak jsme to udělali v příkazu mazání, provádí se to jednou.
Porovnejte znovu příkaz Vložit s výše uvedeným příkazem sloučení.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Vzhledem k tomu, že příkaz SLOUČENÍ stanoví zdrojovou a cílovou tabulku a také způsob, jakým se shodují, je vše červeně barevně kódované; proto ne ve vložené části sloučení.
Protokolování SLOUČENÝCH změn pomocí VÝSTUPU
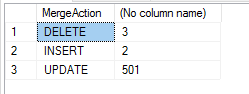
Pomocí klauzule OUTPUT můžete protokolovat jakékoli změny. V tomto případě lze použít speciální proměnnou $ action k přihlášení akce sloučení. Tato proměnná bude mít jednu ze tří hodnot: „VLOŽIT“, „AKTUALIZOVAT“ nebo „ODSTRANIT“.
Náš příklad budeme používat i nadále, ale tentokrát provedeme protokolování změn a shrnutí změny.
Pokud je výše uvedené spuštěno na čerstvých ukázkových datech, vygeneruje se následující souhrn: