Obsah (kliknutím přejdete do sekce):
- Vzorový střední symbol
- Co je průměr vzorku?
- Jak najít průměr vzorku
- Rozptyl distribuce vzorkování průměru vzorku
- Vypočítat standardní chybu pro Vzorový průměr
Symbol vzorového průměru
Symbol vzorového průměru je x̄, vyslovuje se „x bar“.
Co je vzorový průměr?
Průměr vzorku je průměrná hodnota nalezená ve vzorku.
Ukázka je jen malou částí celku. Například pokud pracujete pro volební společnost a chcete vědět, kolik lidí ročně zaplatí za jídlo, nebudete chtít volit více než 300 milionů lidí. Místo toho si vezmete zlomek z těchto 300 milionů (možná tisíc lidí); tato frakce se nazývá vzorek. Průměr je další slovo pro „průměr . “ V tomto příkladu by tedy průměr vzorku byl průměrnou částkou, kterou tisíce lidí zaplatí za jídlo ročně.
Průměr vzorku je užitečný, protože vám umožňuje odhadnout, co dělá celá populace, aniž by se dotazovali každého . Řekněme, že průměrná hodnota vzorku pro příklad jídla byla 2400 $ ročně. Je pravděpodobné, že byste získali velmi podobné číslo, kdybyste provedli průzkum u všech 300 milionů lidí. Vzorový průměr je tedy způsob, jak ušetřit spoustu času a peněz.
Vzorový střední vzorec
Vzorový střední vzorec je:
x̄ = (Σ xi) / n
Pokud to vypadá komplikovaně, je to jednodušší, než si myslíte (i když v případě potřeby navštivte naši doučovací stránku!). Pamatujete si vzorec pro nalezení „průměru“ v základní matematice? Je to přesně to samé, pouze notace (tj. Symboly) se liší. Rozdělme to na části:
- x̄ just znamená „sample mean“
- Σ je součtový zápis, což znamená „sčítat“
- xi „všechny hodnoty x“
- n znamená „počet položek ve vzorku“
Nyní jde pouze o doplnění čísel, která jste dostali, a řešení pomocí aritmetiky (není nutná algebra – toto můžete v zásadě zapojit do jakékoli kalkulačky).
Může se zobrazit následující alternativní vzorový průměr:
x̄ = 1 / n * (Σ xi)
Nastavení je mírně odlišné, ale algebraicky je to stejný vzorec (pokud zjednodušíte vzorec 1 / n * X, dostanete 1 / X).
 Pro nekonvenční způsob, jak nikdy nezapomenout na formu la, podívejte se na toto skvělé tričko na Amazonu, které vám pomůže zapamatovat si ho. Vlastním jeden!
Pro nekonvenční způsob, jak nikdy nezapomenout na formu la, podívejte se na toto skvělé tričko na Amazonu, které vám pomůže zapamatovat si ho. Vlastním jeden!
Zpět nahoru
Jak najít vzorový průměr
Podívejte se na video nebo si přečtěte následující kroky:
Jak najít vzorový průměr: Přehled
Vydělením součtu počtem položek k nalezení střední hodnoty.
Hledání průměrné hodnoty vzorku se nijak neliší od nalezení průměru množiny čísel. Ve statistikách narazíte na mírně odlišný zápis, než na jaký jste pravděpodobně zvyklí, ale matematika je úplně stejná.
Vzorec pro vyhledání průměrné hodnoty vzorku je:
= (Σ xi) / n.
Vše, co tento vzorec říká, je sečíst všechna čísla v datové sadě (Σ znamená „přidat“ a xi znamená „všechna čísla v soubor dat). V tomto článku se dozvíte, jak ručně najít průměr vzorku (toto je také jeden ze vzorců Statistiky AP). Pokud však zjišťujete průměrnou hodnotu vzorku, pravděpodobně budete hledat další popisné statistiky, například rozptyl vzorku nebo mezikvartilní rozsah, takže možná budete chtít zvážit nalezení střední hodnoty v aplikaci Excel nebo jiné technologii. Proč? Ačkoli je výpočet střední hodnoty poměrně jednoduchý, pokud používáte Excel, musíte čísla zadat pouze jednou. Poté můžete pomocí čísel vyhledat libovolnou statistiku: nejen průměrnou hodnotu vzorku.
Jak najít průměrnou hodnotu vzorku: Kroky
Krok 1: Sčítání všech čísel :
12 + 13 + 14 + 16 + 17 + 40 + 43 + 55 + 56 + 67 + 78 + 78 + 79 + 80 + 81 + 90 + 99 + 101 + 102 + 304 + 306 + 400 + 401 + 403 + 404 + 405 = 3744.
Krok 2: Spočítejte počet položek v datové sadě. V této konkrétní sadě dat je 26 položek.
Krok 3: Vydělte číslo, které jste našli v kroku 1, číslem, které jste našli v kroku 2. 3744/26 = 144.
A je to!
Tip: Pokud musíte ukázat vypracování testu, jednoduše vložte dvě čísla do vzorce. Krok 1 vám dává σ a krok 2 vám n:
x = (Σ xi) / n
= 3744/26
= 144
Zpět nahoru
Podívejte se na video nebo si přečtěte následující článek:
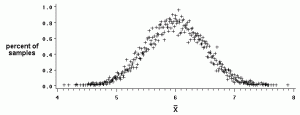
Distribuce vzorků, kde průměr = 6. Obrázek: U Oklahomy
Distribuce vzorkování střední hodnoty vzorku je rozdělení pravděpodobnosti všech průměrných vzorků. Řekněme, že jste měli 1 000 lidí a odebrali jste vzorky 5 lidí najednou a vypočítali jejich průměrnou výšku. Pokud jste stále odebírali vzorky (tj. Opakovali jste vzorkování tisíckrát), nakonec průměr všech vašich vzorků znamená:
- Stejný průměr populace, μ
- Vypadat jako křivka normálního rozdělení.
Rozptyl tohoto rozdělení pravděpodobnosti vám poskytne představu o tom, jak jsou data rozložena kolem průměru. Čím větší je velikost vzorku, tím těsněji bude průměr vzorku představovat průměr populace. Jinými slovy, jak N roste, rozptyl se zmenšuje. V ideálním případě, když se průměr vzorku shoduje s průměrem populace, rozptyl se bude rovnat nule.
Vzorec pro zjištění rozptylu distribuce vzorkování průměru je:
σ2M = σ2 / N,
kde:
σ2M = rozptyl rozdělení vzorkování střední hodnoty vzorku.
σ2 = rozptyl populace.
N = velikost vašeho vzorku.
Otázka vzorku: Pokud je náhodný vzorek velikost 19 je čerpána z distribuce populace se směrodatnou odchylkou α = 20, jaká bude tedy rozptyl distribuce vzorkování ve vzorku? Rozptyl je směrodatná odchylka na druhou, takže:
σ2 = 202 = 400.
Krok 2: Vydělte rozptyl počtem položek ve vzorku. Tato ukázka má 19 položek, takže:
400/19 = 21.05.
To je vše!
Zpět nahoru
Vypočítejte standardní chybu vzorku Průměr
Podívejte se na video nebo si přečtěte článek níže:
Jak vypočítat standardní chybu vzorku Průměr: Přehled
Standardní chyba pro vzorový průměr, „s.“
Standardní chyba průměru vzorku se rovná standardní odchylce pro vzorek. Rozdíl mezi standardní chybou a standardní odchylkou je ten, že se standardními odchylkami použijete data populace (tj. parametry) a se standardními chybami použijete data ze svého vzorku. Standardní chybu pro střední hodnotu vzorku můžete vypočítat pomocí vzorce:
SE = s / √ (n)
SE = standardní chyba, s = standardní odchylka vašeho vzorku an je počet položek ve vašem vzorku.
Vypočítat standardní chybu pro průměr vzorku: Kroky
Příklad: Najděte standardní chybu pro následující výšky (v cm): Jim (170,5), John (161), Jack (160) , Freda (170), Tai (150,5).
Krok 1: Najděte průměr (průměr) souboru dat: (170,5 + 161 + 160 + 170 + 150,5) / 5 = 162,4.
Krok 3: Vynásobte čísla, která jste vypočítali v kroku 2:
-8.1 * -8.1 = 65,61
1,4 * 1,4 = 1,96
2,4 * 2,4 = 5,76
-7,6 * -7,6 = 57,76
11,9 * 11,9 = 141,61
Krok 4: Přidejte hodnoty, které jste vypočítali v kroku 3:
65,61 + 1,96 + 5,76 + 57,76 + 141,61 = 272,7
Krok 5: Vydělte číslo, které jste našli v kroku 4, velikostí vzorku – 1. Ve vzorku je pět položek, takže n-1 = 4:
272,7 / 4 = 68,175.
Krok 6: Vezměte druhou odmocninu čísla, které jste našli v kroku 5. Toto je vaše standardní odchylka.
√ (68,175) = 8,257
Takto vypočítáte standard chyba pro průměrnou hodnotu vzorku!
Tip: Pokud budete požádáni o nalezení „standardní chyby“ pro vzorek, ve většině případů zjistíte chybu vzorku pro střední hodnotu pomocí vzorce SE = s / √n. Existují však různé typy standardní chyby (tj. Proporce), takže se možná budete chtít ujistit, že počítáte správnou statistiku.
————- ————————————————– —— ———
Potřebujete pomoci s domácími úkoly nebo testovací otázkou? S Chegg Study můžete získat podrobné řešení vašich otázek od odborníka v oboru. Prvních 30 minut s lektorem Chegg je zdarma!
