Wprowadzenie do instrukcji MERGE i modyfikacji danych SQL Server
Instrukcja MERGE służy do wprowadzania zmian w jednej tabeli na podstawie wartości dopasowanych z innej. Może być używany do łączenia operacji wstawiania, aktualizowania i usuwania w jednej instrukcji. W tym artykule dowiemy się, jak używać oświadczenia MERGE. Omawiamy sprawdzone metody, ograniczenia i podsumowanie z kilkoma przykładami.
To piąty artykuł z serii artykułów. Możesz rozpocząć od przeczytania Wprowadzenie do instrukcji modyfikacji danych SQL Server.
Wszystkie przykłady w tej lekcji są oparte na programie Microsoft SQL Server Management Studio i bazie danych AdventureWorks2012. Możesz rozpocząć korzystanie z tych bezpłatnych narzędzi, korzystając z mojego Przewodnika Pierwsze kroki Korzystanie z SQL Server
Zanim zaczniemy
Chociaż w tym artykule jako przykłady wykorzystano bazę danych AdventureWorks, zdecydowałem się utworzyć kilka przykładowych tabel do wykorzystania w bazie danych, aby lepiej zilustrować omawiane pojęcia. Tutaj znajdziesz skrypt, który musisz uruchomić. Zauważ, że istnieje specjalna sekcja dotycząca MERGE.
Podstawowa struktura
Instrukcja MERGE łączy operacje INSERT, DELETE i UPDATE w jednej tabeli. Kiedy zrozumiesz, jak to działa, zobaczysz, że upraszcza procedurę, wykorzystując wszystkie trzy instrukcje osobno do synchronizacji danych.
Poniżej znajduje się uogólniony format instrukcji scalania.
MERGE targetTableUsing sourceTableON mergeConditionWHEN MATCHEDTHEN updateStatementWHEN NOT MATCHED BY TARGETTHEN insertStatementWHEN NOT MATCHED BY SOURCETHEN deleteStatement
Instrukcja merge działa przy użyciu dwóch tabel, sourceTable i targetTable. Tabela docelowa to tabela, która ma zostać zmodyfikowana na podstawie danych zawartych w tabeli źródłowej.
Dwie tabele są porównywane przy użyciu warunku mergeCondition . Ten warunek określa, w jaki sposób wiersze z sourceTable są dopasowywane do targetTable. Jeśli znasz INNER JOINS, możesz myśleć o tym jako o warunku łączenia używanym do dopasowywania wierszy.
Zwykle dopasujesz unikalny identyfikator, taki jak klucz podstawowy. Jeśli tabelą źródłową był NewProduct i docelowy ProductMaster, a kluczem podstawowym obu ProductID byłby dobry warunek scalenia:
NewProduct.ProductID = ProductMaster.ProductID
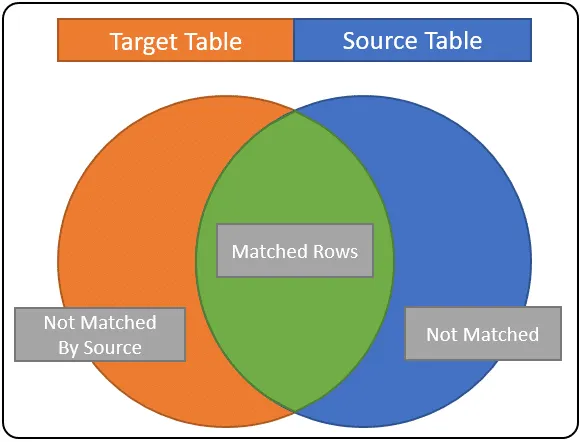
Wynik scalenia w jednym z trzech stanów: DOPASOWANY, NIE DOPASOWANY lub NIE DOPASOWANY WEDŁUG ŹRÓDŁA.
Warunki łączenia
Przyjrzyjmy się, co oznaczają różne warunki:
DOPASOWANY – są to wiersze spełniające warunek dopasowania. Są wspólne dla tabel źródłowych i docelowych. Na naszym diagramie są one pokazane na zielono. Kiedy używasz tego warunku w oświadczeniu o połączeniu, ty; najbardziej przypomina aktualizowanie kolumn wierszy docelowych wartościami kolumn tabeli źródłowej.
NIE DOPASOWANY – jest to również znane jako NIE DOPASOWANE WEDŁUG CELU; są to wiersze z tabeli źródłowej, które nie pasowały do żadnych wierszy w tabeli docelowej. Te rzędy są reprezentowane przez niebieski obszar powyżej. W większości przypadków można to wykorzystać do wywnioskowania, że wiersze źródłowe powinny zostać dodane do tabeli targetTable.
NIEDOPASOWANE WEDŁUG ŹRÓDŁA – są to wiersze w tabeli docelowej, które nigdy nie zostały dopasowane przez rekord źródłowy; to są rzędy w pomarańczowym obszarze. Jeśli Twoim celem jest pełna synchronizacja danych tabeli targetTable ze źródłem, użyjesz tego warunku dopasowania do USUNIĘCIA wierszy.
Jeśli nie możesz zrozumieć, jak to działa, rozważ warunek scalania warunek łączenia. ROWS w zielonej sekcji reprezentują wiersze spełniające warunek scalania, wiersze w niebieskiej sekcji to te wiersze, które znajdują się w tabeli SourceTable, ale nie w miejscu docelowym. Wiersze w pomarańczowej sekcji to te wiersze, które znajdują się tylko w miejscu docelowym.
Dzięki tym dopasowanym scenariuszom możesz łatwo włączać działania dodawania, usuwania i aktualizowania do jednej instrukcji, aby zsynchronizować zmiany między dwoma tabele.
Spójrzmy na przykład.
Przykład MERGE
Załóżmy, że naszym celem jest zsynchronizowanie wszelkich zmian wprowadzonych w esqlProductSource z esqlProductTarget. Oto schemat tych dwóch tabel:
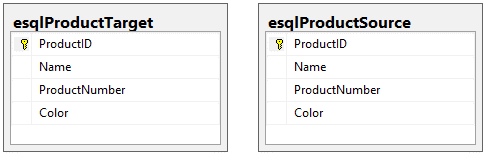
Uwaga: Na potrzeby tego przykładu uruchomiłem skrypty, o których mówiłem we wprowadzeniu do tworzenia i wypełniania dwóch tabel: esqlProductSource i esqlProductTarget.
Zanim skonstruujemy instrukcję MERGE, przyjrzyjmy się, jak zsynchronizowalibyśmy tabelę za pomocą instrukcji UPDATE, INSERT i DELETE w celu zmodyfikowania, dodania i usunąć wiersze w tabeli docelowej.
Myślę, że kiedy zobaczysz, jak robimy to indywidualnie, wtedy zobaczenie połączonych w jedną operację ma większy sens.
Używanie UPDATE do synchronizacji zmian od jednej tabeli do następnej
Aby zaktualizować tabelę docelową zmienionymi wartościami w źródle produktu, możemy użyć instrukcji UPDATE. Biorąc pod uwagę, że ProductID jest kluczem podstawowym obu tabel, stał się on naszym najlepszym wyborem wierszy dopasowania między tabelami.
Gdybyśmy mieli zaktualizować wartości kolumn w tabeli docelowej przy użyciu kolumn źródłowych, moglibyśmy to zrobić za pomocą następującej instrukcji aktualizacji
UPDATE esqlProductTargetSET Name = S.Name, ProductNumber = S.ProductNumber, Color = S.ColorFROM esqlProductTarget T INNER JOIN esqlProductSource S ON S.ProductID = T.ProductID
Ta instrukcja zaktualizuje kolumnę w esqlProductTarget o odpowiednie wartości kolumn znalezione w esqlProductSource w celu dopasowania identyfikatorów produktów.
WSTAW wiersze znalezione w jednej tabeli, ale nie w drugiej
Teraz zobaczmy może zidentyfikować wiersze z tabeli źródłowej, które musimy wstawić do celu produktowego. Aby to zrobić, możemy użyć podzapytania, aby znaleźć wiersze w tabeli źródłowej, które nie znajdują się w miejscu docelowym.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Uwaga: Mogę również użyć sprzężenia zewnętrznego zrobić to samo. Jeśli interesuje Cię dlaczego, przeczytaj ten artykuł.
Ta instrukcja wstawi nowy wiersz do esqlProductTarget ze wszystkich wierszy w esqlProductSource, których nie ma w esqlProductTarget.
Usuwanie Wiersze
Ta ostatnia czynność synchronizacji, którą musimy wykonać, usuwa wszystkie wiersze w tabeli docelowej, których nie ma w źródle SQL. Podobnie jak w przypadku instrukcji insert, użyjemy podzapytania. Ale tym razem zidentyfikujemy wiersze w esqlProductTarget, których nie znaleziono w esqlProductSource. Oto instrukcja DELETE, której możemy użyć:
DELETE esqlProductTargetFROM esqlProductTarget TWHERE NOT EXISTS (SELECT S.ProductID FROM esqlProductSource S WHERE T.ProductID = S.ProductID)
Teraz, kiedy już wiesz, jak wykonać poszczególne operacje, zobaczmy, jak łączą się one w instrukcja merge.
Zauważ, że większość ciężkiego podnoszenia jest wykonywana przez warunek scalenia i jego wyniki. Zamiast wielokrotnie ustawiać dopasowanie, tak jak zrobiliśmy to w instrukcji delete, robi się to raz.
Porównaj ponownie instrukcję Insert z instrukcją merge powyżej.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Biorąc pod uwagę, że instrukcja MERGE określa tabelę źródłową i docelową, a także sposób ich dopasowania, wszystko oznaczone kolorem czerwonym jest zbędne; w związku z tym nie we wstawianej części scalania.
Rejestrowanie zmian MERGE za pomocą OUTPUT
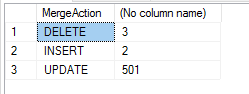
Możesz użyć klauzuli OUTPUT, aby zarejestrować wszelkie zmiany. W tym przypadku do rejestrowania akcji łączenia można użyć specjalnej zmiennej $ action. Ta zmienna przyjmie jedną z trzech wartości: „INSERT”, „UPDATE” lub „DELETE”.
Będziemy nadal używać naszego przykładu, ale tym razem zarejestrujemy zmiany i podsumujemy zmian.
Jeśli powyższe zostanie uruchomione na świeżych danych przykładowych, generowane jest następujące podsumowanie: