콘텐츠 (섹션으로 이동하려면 클릭) :
- 샘플 평균 기호
- 표본 평균은 무엇입니까?
- 표본 평균을 찾는 방법
- 표본 평균의 표본 분포 분산
- 샘플 평균
샘플 평균 기호
샘플 평균 기호는 x̄이며 “x bar”로 발음됩니다.
샘플 평균이란 무엇입니까?
샘플 평균은 샘플에서 찾은 평균값입니다.
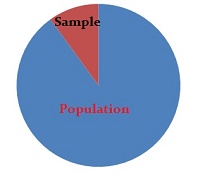
샘플은 전체의 작은 부분에 불과합니다. 예를 들어, 설문 조사 회사에서 일하고 사람들이 1 년에 얼마나 많은 사람들이 식량에 지불하는지 알고 싶다면 3 억 명 이상의 설문 조사를하고 싶지 않을 것입니다. 대신 그 3 억 (아마도 천명 정도)의 일부를 가져갑니다. 그 분수를 표본이라고합니다. 평균은 “평균 .” 따라서이 예에서 표본 평균은 1,000 명의 사람들이 1 년에 음식에 대해 지불하는 평균 금액입니다.
표본 평균은 모든 사람을 조사하지 않고도 전체 인구가 무엇을하고 있는지 추정 할 수 있기 때문에 유용합니다. . 음식 예의 샘플 평균이 연간 $ 2400이라고 가정 해 보겠습니다. 확률은 3 억 명 모두를 조사하면 매우 유사한 수치를 얻을 수 있다는 것입니다. 따라서 표본 평균은 많은 시간과 비용을 절약하는 방법입니다.
표본 평균 공식
표본 평균 공식은 다음과 같습니다.
x̄ = (Σ xi) / n
복잡해 보이면 생각보다 간단합니다 (도움이 필요하면 튜터링 페이지를 확인하세요!). 기본 수학에서 “평균”을 찾는 공식을 기억하십니까? 똑같은 것이고 표기법 (즉, 기호) 만 다를뿐입니다.이를 여러 부분으로 나누겠습니다.
- x̄ just “샘플 평균”을 의미합니다.
- Σ는 “더하기”를 의미하는 합산 표기법입니다.
- xi “모든 x 값”을 의미합니다.
- n은 “샘플의 항목 수”
이제 주어진 숫자를 연결하고 산술을 사용하여 푸는 문제입니다 (대수가 필요하지 않습니다. 기본적으로이를 연결할 수 있습니다. 모든 계산기).
다음 대체 샘플 평균 공식을 볼 수 있습니다.
x̄ = 1 / n * (Σ xi)
설정은 약간 다르지만 대수적으로는 동일한 공식입니다 (공식 1 / n * X를 단순화하면 1 / X가됩니다).
 포뮤를 잊지 않는 색다른 방법 라, 기억하는 데 도움이되는이 멋진 아마존 티셔츠를 확인하세요. 내가 소유하고 있습니다!
포뮤를 잊지 않는 색다른 방법 라, 기억하는 데 도움이되는이 멋진 아마존 티셔츠를 확인하세요. 내가 소유하고 있습니다!
맨 위로 이동
샘플 평균을 찾는 방법
동영상을 보거나 아래 단계를 읽으십시오.
샘플 평균을 찾는 방법 : 개요
합계를 항목 수로 나누어 평균을 구합니다.
표본 평균을 찾는 것은 숫자 집합의 평균을 찾는 것과 다르지 않습니다. 통계에서 아마 익숙한 것과 약간 다른 표기법을 보게 될 것입니다. 그러나 수학은 정확히 동일합니다.
표본 평균을 구하는 공식은 다음과 같습니다.
= (Σ xi) / n.
이 공식이 말하는 것은 데이터 세트의 모든 숫자를 더하는 것입니다 (Σ는 “더하기”를 의미하고 xi는 “모든 숫자를 데이터 세트). 이 기사에서는 손으로 샘플 평균을 찾는 방법에 대해 설명합니다 (이것은 AP 통계 공식 중 하나이기도합니다). 그러나 표본 평균을 찾는 경우 표본 분산 또는 사 분위수 범위와 같은 다른 설명 통계를 찾을 수 있으므로 Excel 또는 기타 기술에서 표본 평균을 찾는 것이 좋습니다. 왜? 평균 계산은 매우 간단하지만 Excel을 사용하는 경우 숫자를 한 번만 입력하면됩니다. 그런 다음 숫자를 사용하여 표본 평균뿐만 아니라 통계를 찾을 수 있습니다.
표본 평균을 찾는 방법 : 단계
1 단계 : 모든 숫자를 더합니다. :
12 + 13 + 14 + 16 + 17 + 40 + 43 + 55 + 56 + 67 + 78 + 78 + 79 + 80 + 81 + 90 + 99 + 101 + 102 + 304 + 306 + 400 + 401 + 403 + 404 + 405 = 3744.
2 단계 : 데이터 세트의 항목 수를 계산합니다. 이 특정 데이터 세트에는 26 개의 항목이 있습니다.
3 단계 : 1 단계에서 찾은 숫자를 2 단계에서 찾은 숫자로 나눕니다. 3744/26 = 144.
그게 다입니다!
팁 : 시험에서 운동하는 모습을 보여 주어야한다면 수식에 두 숫자를 넣으면됩니다. 1 단계는 σ를 제공하고 2 단계는 n :
x = (Σ xi) / n
= 3744/26
= 144
맨 위로 이동
동영상을 보거나 아래 기사를 읽어보세요.
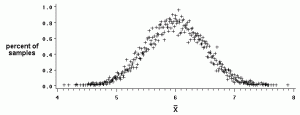
평균이 6 인 샘플링 분포 이미지 : U of Oklahoma
표본 평균의 표본 분포는 모든 표본 평균의 확률 분포입니다. 1,000 명의 사람이 있고 한 번에 5 명의 사람을 샘플링하여 평균 신장을 계산했다고 가정 해 보겠습니다. 샘플을 계속 채취하면 (즉, 샘플링을 천 번 반복) 결국 모든 샘플 평균의 평균은 다음과 같습니다.
- 모집단 평균과 같음, μ
- 정규 분포 곡선.
이 확률 분포의 분산을 통해 데이터가 평균 주위에 얼마나 분산되어 있는지 알 수 있습니다. 표본 크기가 클수록 표본 평균이 모집단 평균을 더 가깝게 나타냅니다. 즉, N이 커질수록 분산이 작아집니다. 이상적으로는 표본 평균이 모집단 평균과 일치 할 때 분산은 0과 같습니다.
평균 표본 분포의 분산을 찾는 공식은 다음과 같습니다.
σ2M = σ2 / N,
여기서 :
σ2M = 표본 평균의 표본 분포 분산.
σ2 = 모집단 분산.
N = 표본 크기
표본 질문 : 크기 19는 표준 편차 α = 20 인 모집단 분포에서 추출한 다음 표본 평균의 표본 분포 분산은 무엇입니까?
1 단계 : 모집단 분산을 파악합니다. 분산은 표준 편차 제곱이므로 다음과 같습니다.
σ2 = 202 = 400.
2 단계 : 분산을 표본의 항목 수로 나눕니다. 이 샘플에는 19 개의 항목이 있으므로 :
400/19 = 21.05.
그렇습니다!
맨 위로 이동
샘플에 대한 표준 오류 계산 의미
동영상을 보거나 아래 기사를 읽으십시오.
샘플에 대한 표준 오류를 계산하는 방법 평균 : 개요
샘플 평균 “s”의 표준 오류입니다.
표본 평균의 표준 오차는 표본의 표준 편차와 같습니다. 표준 오차와 표준 편차의 차이는 표준 편차에서 모집단 데이터 (예 : 매개 변수)를 사용하고 표준 오차를 사용한다는 것입니다. 샘플의 데이터를 사용합니다. 다음 공식을 사용하여 샘플 평균에 대한 표준 오차를 계산할 수 있습니다.
SE = s / √ (n)
SE = 표준 오차, s = 표본의 표준 편차, n은 표본의 항목 수입니다.
샘플 평균에 대한 표준 오차 계산 : 단계
예 : 다음 높이 (cm)에 대한 표준 오차 찾기 : Jim (170.5), John (161), Jack (160) , Freda (170), Tai (150.5).
1 단계 : 데이터 세트의 평균 (평균) 찾기 : (170.5 + 161 + 160 + 170 + 150.5) / 5 = 162.4.
3 단계 : 2 단계에서 계산 한 숫자를 제곱합니다.
-8.1 * -8.1 = 65.61
1.4 * 1.4 = 1.96
2.4 * 2.4 = 5.76
-7.6 * -7.6 = 57.76
11.9 * 11.9 = 141.61
4 단계 : 3 단계에서 계산 한 값을 더합니다.
65.61 + 1.96 + 5.76 + 57.76 + 141.61 = 272.7
5 단계 : 4 단계에서 찾은 숫자를 표본 크기로 나눕니다. – 1. 표본에 5 개의 항목이 있으므로 n-1 = 4 :
272.7 / 4 = 68.175.
6 단계 : 5 단계에서 찾은 숫자의 제곱근을 취합니다. 이것이 표준 편차입니다.
√ (68.175) = 8.257
이것이 표준을 계산하는 방법입니다. 샘플 평균에 대한 오류!
팁 : 샘플에 대한 “표준 오류”를 찾으라는 요청을 받으면 대부분의 경우 공식 SE = s를 사용하여 평균에 대한 샘플 오류를 찾는 것입니다. / √n. 표준 오차에는 여러 유형 (예 : 비율)이 있으므로 올바른 통계를 계산하고 있는지 확인하는 것이 좋습니다.
————- ————————————————– —— ———
숙제 나 시험 문제에 도움이 필요하십니까? Chegg Study를 사용하면 해당 분야의 전문가로부터 질문에 대한 단계별 솔루션을 얻을 수 있습니다. Chegg 튜터와의 첫 30 분은 무료입니다!
