情報は、Linuxとそれが実行されているハードウェアに関する問題や関連する問題など、コンピューターの問題を解決するための鍵です。デフォルトですべてがインストールされているわけではありませんが、ほとんどのディストリビューションで利用可能で含まれているツールはたくさんあります。これらのツールを使用して、大量の情報を取得できます。
この記事では、Redを含むRed Hat関連のディストリビューションに付属または簡単にインストールできるインタラクティブなコマンドラインインターフェイス(CLI)ツールのいくつかについて説明します。 Hat Enterprise Linux、Fedora、CentOS、およびその他の派生ディストリビューション。利用可能なGUIツールがあり、それらは優れた情報を提供しますが、CLIツールはすべて同じ情報を提供し、多くのサーバーにはGUIインターフェイスがありませんが、すべてのLinuxシステムにはコマンドラインインターフェイスがあるため、常に使用できます。
この記事では、私が通常使用するツールに焦点を当てています。お気に入りのツールについて説明しなかった場合は、ご容赦ください。使用しているツールとその理由をコメントセクションでお知らせください。
Linux環境で問題を特定するためのツールにアクセスするのは、ほとんどの場合、システム監視ツール。私にとって、これらはtop、top、htop、glanceです。
これらのツールはすべてCPUとメモリの使用量を監視し、ほとんどのツールは少なくとも実行中のプロセスに関する情報を一覧表示します。 Linuxシステムの他の側面も監視するものもあります。すべてがシステムアクティビティのほぼリアルタイムのビューを提供します。
負荷平均
監視ツールについて説明する前に、負荷平均について詳しく説明することが重要です。
負荷平均はCPU使用率を測定するための重要な基準ですが、たとえば1分(または5または10)分の負荷平均が4.04であると言った場合、これは実際にはどういう意味ですか?負荷平均は、CPUの需要の尺度と見なすことができます。これは、CPU時間を待機している命令の平均数を表す数値です。したがって、これはCPUパフォーマンスの真の尺度です。CPUが実際に機能していない間のI / O待機時間を含む標準の「CPUパーセンテージ」とは異なります。
たとえば、完全に使用されたシングルプロセッサシステムCPU負荷平均は1になります。これは、CPUが需要に正確に対応していることを意味します。言い換えれば、それは完璧な利用率を持っています。負荷平均が1未満の場合は、CPUが十分に活用されていないことを意味し、負荷平均が1より大きい場合は、CPUが過剰に使用されており、需要が不足していることを意味します。たとえば、単一のCPUシステムの平均負荷が1.5の場合、CPU命令の3分の1は、前の命令が完了するまで実行を待機する必要があることを示しています。
これは複数の場合にも当てはまります。プロセッサ。 4 CPUシステムの負荷平均が4の場合、完全に使用されます。たとえば、負荷平均が3.24の場合、3つのプロセッサが完全に使用され、1つが約76%で使用されます。上記の例では、4 CPUシステムの1分間の負荷平均は4.04です。これは、4 CPUの間に容量が残っておらず、いくつかの命令が強制的に待機されることを意味します。完全に使用された4CPUシステムは、4.00の負荷平均を示し、この例のシステムは完全にロードされていますが、過負荷ではありません。
負荷平均の最適条件は、CPUの総数と等しくなることです。システム内。つまり、すべてのCPUが完全に使用されているにもかかわらず、命令を強制的に待機させる必要はありません。長期的な負荷平均は、全体的な使用率の傾向を示します。
Linux Journalには、負荷平均、その背後にある理論と数学、および2006年12月1日のそれらの解釈方法を説明する優れた記事があります。問題。
信号
ここで説明するすべてのモニターを使用すると、実行中のプロセスに信号を送信できます。これらの各シグナルには特定の機能がありますが、シグナルハンドラーを使用して受信プログラムで定義できるものもあります。
個別のkillコマンドを使用して、モニター外のプロセスにシグナルを送信することもできます。 kill -lを使用して、送信可能なすべてのシグナルを一覧表示できます。これらのシグナルのうち3つを使用して、プロセスを強制終了できます。
- SIGTERM(15):シグナル15、SIGTERMは、kキーが押されたときにtopおよび他のモニターによって送信されるデフォルトのシグナルです。また、プログラムにシグナルハンドラーを組み込む必要があるため、効果が最も低い場合があります。プログラムのシグナルハンドラは、着信シグナルをインターセプトし、それに応じて動作する必要があります。したがって、ほとんどのスクリプトにシグナルハンドラがないスクリプトの場合、SIGTERMは無視されます。SIGTERMの背後にある考え方は、プログラムにそれ自体を終了するように指示するだけです。それを利用して、開いているファイルなどをクリーンアップし、制御された適切な方法で終了します。
- SIGKILL(9):シグナル9、SIGKILLは、最も扱いにくいプログラムでさえも殺す手段を提供します。 、シグナルハンドラを持たないスクリプトやその他のプログラムを含みます。ただし、シグナルハンドラのないスクリプトやその他のプログラムの場合は、実行中のスクリプトを強制終了するだけでなく、スクリプトが実行されているシェルセッションも強制終了します。これはあなたが望む振る舞いではないかもしれません。プロセスを強制終了したいが、問題がない場合は、これが必要なシグナルです。このシグナルは、プログラムコードのシグナルハンドラーによってインターセプトできません。
- SIGINT(2):シグナル2、SIGINTは、SIGTERMが機能せず、プログラムが実行されているシェルセッションを強制終了せずに、プログラムをもう少しうまく終了させたい場合に使用できます。SIGINTは、プログラムが実行されているセッションに割り込みを送信します。実行中。これは、実行中のプログラム、特にスクリプトをCtrl-Cキーの組み合わせで終了することと同じです。
これを試すには、ターミナルセッションを開き、/ tmpにファイルを作成します。 cpuHogという名前を付け、アクセス許可rwxr_xr_xで実行可能にします。次のコンテンツをファイルに追加します。
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
別のウィンドウで別のターミナルセッションを開き、隣接して配置します。結果を確認し、新しいセッションでトップを実行できるように、相互に接続します。次のコマンドを使用してcpuHogプログラムを実行します。
このプログラムは、単純に1ずつカウントアップし、Xの現在の値をSTDOUTに出力します。そしてそれはCPUサイクルを吸い上げます。 cpuHogが実行されているターミナルセッションでは、CPU使用率が非常に高くなっているはずです。これがシステムパフォーマンスに与える影響を観察してください。 CPU使用率はすぐに上昇し、負荷平均も時間の経過とともに増加し始めるはずです。必要に応じて、追加のターミナルセッションを開き、そのセッションでcpuHogプログラムを開始して、複数のインスタンスを実行することができます。
強制終了するcpuHogプログラムのPIDを決定します。 kキーを押して、要約セクションの下部にあるスワップ行の下のメッセージを確認します。 Topは、強制終了するプロセスのPIDを要求します。そのPIDを入力し、Enterキーを押します。ここで、topは信号番号を要求し、デフォルトの15を表示します。ここで説明する各信号を試して結果を観察してください。
Linuxシステム監視用の4つのオープンソースツール
1つ問題判別を実行するときに最初に使用するツールはトップです。ずっと前から存在していて、他のツールがインストールされていない間はいつでも利用できるので、私はそれが好きです。
トッププログラムは、実行中のシステムに関する多くの情報を提供する非常に強力なユーティリティです。これには、メモリ使用量、CPU負荷、および各プロセスで使用されているCPU時間とメモリの量を含む実行中のプロセスのリストに関するデータが含まれます。 Topは、システム情報をほぼリアルタイムで表示し、(デフォルトでは)3秒ごとに更新します。非常に小さい値はシステムに大きな負荷をかける可能性がありますが、小数秒はtopによって許可されます。また、インタラクティブで、表示するデータ列と並べ替え列を変更できます。
トッププログラムからの出力例を下の図1に示します。上からの出力は、出力の上部である「要約」セクションと、出力の下部である「プロセス」セクションと呼ばれる2つのセクションに分割されます。一貫性を保つために、この用語をtop、top、htop、glanceに使用します。
topプログラムには、データの表示を管理したり、個々のプロセスを操作したりするために使用できる便利なインタラクティブコマンドが多数あります。 。 hコマンドを使用して、さまざまな対話型コマンドの簡単なヘルプページを表示します。ヘルプの両方のページを表示するには、必ずhを2回押してください。 qコマンドを使用して終了します。
概要セクション
上からの出力の概要セクションは、システムステータスの概要です。最初の行は、システムの稼働時間と1分、5分、および15分の負荷平均を示しています。以下の例では、負荷の平均はそれぞれ4.04、4.17、4.06です。
2行目は、現在アクティブなプロセスの数とそれぞれのステータスを示しています。
次にCPU統計を示します。以下の例のように、システムに存在するすべてのCPUの統計を組み合わせた単一の行、または各CPUに1つの行があります。例で使用されているコンピューターの場合、これはシングルクアッドコアCPUです。 1キーを押して、CPU使用率の統合表示と個々のCPUの表示を切り替えます。これらの行のデータは、使用可能な合計CPU時間のパーセンテージとして表示されます。
CPUデータのこれらのフィールドとその他のフィールドについては以下で説明します。
- us:userspace –アプリケーションおよびユーザースペースで実行されている他のプログラム、つまりカーネルでは実行されていません。
- sy:システムコール–カーネルレベルの関数。これには、カーネル自体にかかるCPU時間は含まれず、カーネルシステムコールのみが含まれます。
- ni:nice –正のniceレベルで実行されているプロセス。
- id:idle –アイドル時間、つまり、実行中のプロセスによって使用されていない時間。
- wa:wait – I / Oの発生を待機するために費やされるCPUサイクル。これは無駄なCPU時間です。
- hi:ハードウェア割り込み–ハードウェア割り込みの処理に費やされるCPUサイクル。
- si:ソフトウェア割り込み–ソフトウェアによって作成された割り込みの処理に費やされるCPUサイクルシステム呼び出しとして。
- st:スチール時間–ハイパーバイザーが別の仮想プロセッサにサービスを提供している間に仮想CPUが実際のCPUを待機するCPUサイクルの割合。
概要セクションの最後の2行は、メモリ使用量です。これらは、RAMとスワップスペースの両方を含む物理メモリ使用量を示しています。
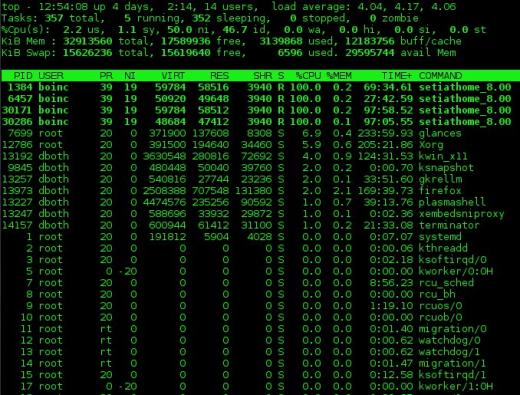
図1:完全に使用された4コアCPUを示す一番上のコマンド。
1コマンドを使用して、上記の図1に示すように、CPU統計を単一のグローバル番号として、または個々のCPUごとに表示できます。 lコマンドは、負荷平均のオンとオフを切り替えます。 tコマンドとmコマンドは、要約セクションのプロセス/ CPUとメモリの行を、それぞれオフ、テキストのみ、およびいくつかのタイプの棒グラフ形式でローテーションします。
プロセスセクション
上からの出力のプロセスセクションは、システムで実行中のプロセスのリストです。少なくとも、ターミナルディスプレイに空きがあるプロセスの数については。上に表示されるデフォルトの列を以下に説明します。他のいくつかの列が利用可能であり、通常、それぞれを1回のキーストロークで追加できます。詳細については、トップのマニュアルページを参照してください。
- PID –プロセスID。
- USER –プロセス所有者のユーザー名。
- PR –プロセスの優先度。
- NI –プロセスの適切な数。
- VIRT –プロセスに割り当てられた仮想メモリの合計量。
- RES –プロセスによって消費されるスワップされていない物理メモリの常駐サイズ(特に明記されていない限りkb)。
- SHR –プロセスによって使用される共有メモリの量(kb)。
- S –プロセスのステータス。これは、ランニングの場合はR、スリープの場合はS、ゾンビの場合はZになります。あまり頻繁に表示されないステータスは、トレースまたは停止の場合はT、中断できないスリープの場合はDです。
- %CPU – CPUサイクルの割合、または最後に測定された期間中にこのプロセスで使用された時間。
- %MEM –プロセスによって使用された物理システムメモリのパーセンテージ。
- TIME + –プロセスが開始されてからプロセスによって消費された100分の1秒までの合計CPU時間。
- コマンド–これはプロセスを起動するために使用されたコマンドです。
PageUpキーとPageDownキーを使用して、実行中のプロセスのリストをスクロールします。 dまたはsコマンドは交換可能であり、更新間の遅延間隔を設定するために使用できます。デフォルトは3秒ですが、私は1秒間隔を好みます。間隔の粒度は10分の1秒まで低くすることができますが、これにより、測定しようとしているCPUサイクルがより多く消費されます。
<キーと>キーを使用して、並べ替え列を左または右に並べ替えます。
kコマンドは、プロセスを強制終了するために使用されます。それを放棄します。強制終了または削除するプロセスのプロセスID(PID)を知っている必要があり、その情報は上部ディスプレイのプロセスセクションに表示されます。プロセスを強制終了する場合、topは最初にPIDを要求し、次にプロセスの強制終了に使用するシグナル番号を要求します。それらを入力し、それぞれの後にEnterキーを押します。シグナル15、SIGTERMから開始し、それでもプロセスが強制終了されない場合は、9、SIGKILLを使用します。
構成
上部の表示を変更する場合は、W(構成ファイルへの変更を書き込むための大文字)コマンド、ホームディレクトリの〜/ .toprc。
atop
私もatopが好きです。これは、そのタイプのI / Oアクティビティに関する詳細が必要な場合に使用する優れたモニターです。デフォルトの更新間隔は10秒ですが、これは、interval iコマンドを使用して、実行しようとしている内容に適したものに変更できます。 atopは、topのように1秒未満の間隔で更新することはできません。
hコマンドを使用してヘルプを表示します。ヘルプのページが複数あり、スペースバーを使用して下にスクロールして残りのページを表示できることに注意してください。
トップの優れた機能の1つは、生のパフォーマンスデータをファイルに保存してその後、詳細に調べるために再生します。これは、断続的な問題、特にシステムを直接監視できないときに発生する問題を追跡するのに便利です。 atopsarプログラムは、保存されたファイルのデータを再生するために使用されます。
 。
。
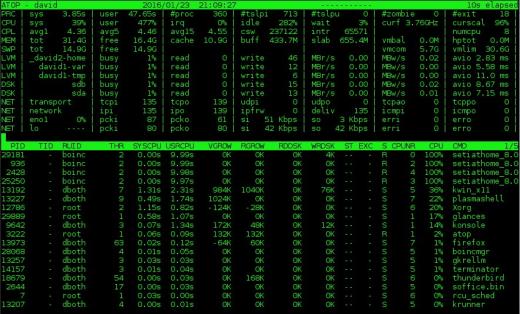
図2:上部のシステムモニターは、ディスクとCPUおよびプロセスデータに加えて、ネットワークアクティビティ。
概要セクション
topには、topと同じ情報の多くが含まれていますが、ネットワーク、rawディスク、および論理ボリュームアクティビティに関する情報も表示されます。上の図2は、これらの追加データをディスプレイ上部の列に示しています。より広い表示をサポートする水平画面領域がある場合は、追加の列が表示されることに注意してください。逆に、水平方向の幅が狭い場合は、表示される列が少なくなります。また、図2の右端の2列の2行目に、現在のCPU周波数と倍率(これらのモニターでは見られなかったもの)が表示されているのも気に入っています。
プロセスセクション
topプロセスの表示には、topと同じ列がいくつか含まれていますが、各プロセスのディスクI / O情報とスレッド数、および各プロセスの仮想メモリと実メモリの増加統計も含まれています。要約セクションと同様に、十分な水平画面領域がある場合は、追加の列が表示されます。たとえば、図2では、プロセス所有者のRUID(実ユーザーID)が表示されています。表示を展開すると、プログラムがSUID(ユーザーIDの設定)を実行するときに重要になる可能性のあるEUID(有効なユーザーID)も表示されます。
上部には、ディスク、メモリ、ネットワーク、およびスケジュール情報に関する詳細情報も表示されます。プロセスごとに。 d、m、n、またはsキーをそれぞれ押すだけで、そのデータが表示されます。 gキーを押すと、表示が汎用プロセス表示に戻ります。
Cを使用してCPU使用率、Mをメモリ使用量、Dをディスク使用量、Nをネットワーク使用量、Aを使用して簡単に並べ替えることができます。自動ソート。自動ソートは通常、最もビジーなリソースでプロセスをソートします。ネットワークの使用状況は、netatopカーネルモジュールがインストールおよびロードされている場合にのみ並べ替えることができます。
kキーを使用してプロセスを強制終了できますが、プロセスを再起動するオプションはありません。
デフォルトでは、特定の時間間隔中にアクティビティが発生しないネットワークおよびディスクデバイスは表示されません。これにより、ホストのハードウェア構成に関する誤った想定につながる可能性があります。 fコマンドを使用して、topにアイドル状態のリソースを表示させることができます。
構成
atopのマニュアルページはグローバルおよびユーザーレベルの構成ファイルを参照していますが、独自のFedoraまたはCentOSインストール。変更された構成を保存するコマンドもありません。また、プログラムの終了時に保存は自動的に行われません。そのため、構成の変更を永続的にする方法があるようです。
htop
htopプログラムはtopによく似ていますが、ステロイドを使用しています。 topによく似ていますが、topにはない機能もいくつか提供します。ただし、topとは異なり、ディスク、ネットワーク、またはI / O情報を提供するものはありません。
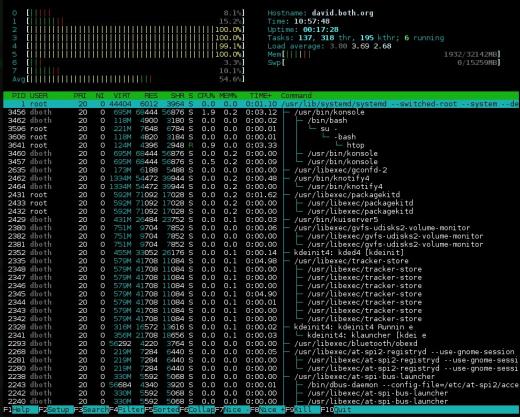
図3:htopには、リソースの使用状況を示すための優れた棒グラフがあり、プロセスツリーを表示できます。
概要セクション
htopの概要セクションは2列で表示されます。非常に柔軟性があり、さまざまな種類の情報をほぼ任意の順序で構成できます。 topとtopのCPU使用率セクションは、組み合わせた表示とCPUごとに1つの棒グラフを表示する表示の間で切り替えることができますが、htopはできません。そのため、CPUディスプレイには、単一の結合バー、各CPUのバー、特定のCPUを1つのバーにグループ化できるさまざまな組み合わせなど、さまざまなオプションがあります。
これは、他のいくつかのシステムモニターよりもすっきりとした要約表示であり、読みやすくなっています。この要約セクションの欠点は、ユーザー別のCPUパーセンテージ、アイドル状態、システム時間など、他のモニターで利用できるhtopでは利用できない情報があることです。
F2(セットアップ)キーはhtopの要約セクションを構成するために使用されます。使用可能なデータ表示のリストが表示され、ファンクションキーを使用してそれらを左または右の列に追加したり、選択した列内で上下に移動したりできます。
プロセスセクション
htopのプロセスセクションは、topのプロセスセクションと非常によく似ています。他のモニターと同様に、プロセスは、CPUまたはメモリの使用量、ユーザー、PIDなど、いくつかの要因のいずれかで並べ替えることができます。ツリービューが選択されている場合、並べ替えはできないことに注意してください。
F6キーを使用すると、並べ替え列を選択できます。並べ替えに使用できる列のリストが表示され、目的の列を選択してEnterキーを押します。
上下の矢印キーを使用してプロセスを選択できます。プロセスを強制終了するには、上下の矢印キーを使用してターゲットプロセスを選択し、kキーを押します。プロセスを送信するシグナルのリストが表示され、15、SIGTERMが選択されています。 SIGTERMと異なる場合は、使用するシグナルを指定できます。 F7キーとF8キーを使用して、選択したプロセスを解放することもできます。
特に気に入っているコマンドの1つは、実行中のプロセスをツリー形式で表示して、実行中の親子関係を簡単に判別できるF5です。プロセス。
構成
各ユーザーには独自の構成ファイル〜/ .config / htop / htoprcがあり、htop構成への変更はそこに自動的に保存されます。htopのグローバル構成ファイルはありません。
glances
最近、glanceについて学びました。これにより、現在使い慣れている他のどのモニターよりも多くの情報をコンピューターに表示できます。と。これには、ディスクとネットワークのI / O、CPUやその他のハードウェアの温度、ファンの速度を表示できる熱読み取り、ハードウェアデバイスと論理ボリュームごとのディスク使用量が含まれます。
これらすべての情報を持つことの欠点glanceは、それ自体がかなりの量のCPUリソースを使用しているということです。私のシステムでは、CPUサイクルの約10%から18%を使用できることがわかりました。モニターを選択するときは、その影響を考慮する必要があります。
概要セクション
一目でわかる概要セクションには、他の概要セクションとほとんど同じ情報が含まれています。モニター。十分な水平画面領域がある場合は、棒グラフと数値インジケーターの両方でCPU使用率を表示できます。それ以外の場合は、数値のみが表示されます。
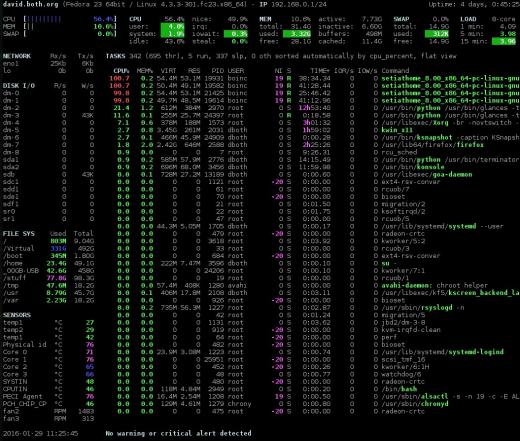
図4:ネットワーク、ディスク、ファイルシステム、およびセンサー情報とのglanceインターフェイス。
この要約セクションは他のモニターよりも気に入っています。わかりやすい形式で正しい情報を提供していると思います。 atopおよびhtopと同様に、1キーを押すと、上記の図4に示すように、個々のCPUコアの表示と、すべてのCPUコアを単一の平均として表示するグローバル表示を切り替えることができます。
プロセスセクション
プロセスセクションには、実行中の各プロセスに関する標準情報が表示されます。プロセスは、自動的にa、またはCPU c、メモリm、名前p、ユーザーu、I / Oレートi、または時間tによってソートできます。自動的に並べ替えられると、プロセスは最初に最も使用されたリソースによって並べ替えられます。
画面の一番下に、イベントの時間と期間などの警告と重大なアラートも表示されます。これは、一度に何時間も画面を見つめることができないときに問題を診断しようとするときに役立ちます。これらのアラートログはlコマンドでオンまたはオフに切り替えることができ、警告はwコマンドでクリアでき、アラートと警告はすべてxでクリアできます。
一瞥だけがこれらのモニターは、プロセスを強制終了または再実行するために使用することはできません。厳密にはモニターとして意図されています。外部のkillコマンドとreniceコマンドを使用して、プロセスを操作できます。
サイドバー
Glanceには、topまたはhtopでは利用できない情報を表示する非常に優れたサイドバーがあります。 Atopはこのデータの一部を表示しますが、センサーデータを表示するモニターはglanceだけです。コンピュータ内部の温度を確認すると便利な場合があります。個々のモジュール、ディスク、ファイルシステム、ネットワーク、およびセンサーは、それぞれd、f、n、およびsコマンドを使用してオンとオフを切り替えることができます。サイドバー全体は、2を使用して切り替えることができます。
Docker統計はDで表示できます。
構成
Glanceは正しく機能するために構成ファイルを必要としません。 1つを選択した場合、構成ファイルのシステム全体のインスタンスは/etc/glances/glances.confにあります。個々のユーザーは、〜/ .config / glances / glances.confにローカルインスタンスを持つことができ、グローバル構成をオーバーライドします。これらの構成ファイルの主な目的は、警告と重大なアラートのしきい値を設定することです。サイドバーモジュールやCPUディスプレイなど、他の構成変更を永続的に行う方法はありません。 glanceを開始するたびに、これらのアイテムを再構成する必要があるようです。
使用に関する多くの情報を提供するドキュメント/usr/share/doc/glances/glances-doc.htmlがあります。一見すると、構成ファイルを使用して表示するモジュールを構成できることが明示的に示されています。ただし、記載されている情報も例も、その方法を説明していません。
結論
大量のモニターがあるため、これらの各モニターのマニュアルページを必ずお読みください。それらの構成と相互作用に関する情報。また、インタラクティブモードでヘルプを表示するにはhキーを使用します。このヘルプは、データの列の選択と並べ替え、更新間隔の設定などに関する情報を提供します。
これらのプログラムは、問題の原因を探しているときに多くのことを教えてくれます。プロセスがいつCPU時間を消費しているか、十分な空きメモリがあるかどうか、ディスクやネットワークアクセスなどのI / Oが完了するのを待っている間にプロセスが停止しているかどうかなど、さまざまな情報を得ることができます。
問題の原因を探しているときに異常である可能性のあるものを区別できるように、これらの監視プログラムが正常に機能しているシステムで実行されている間、時間をかけて監視することを強くお勧めします。
これらの監視ツールを使用すると、システムのメモリやCPU時間などのリソースの使用が変わることにも注意してください。これらのモニターの上位およびほとんどは、システムのCPU時間のおそらく2%または3%を使用します。一瞥は他のモニターよりもはるかに大きな影響を及ぼし、CPU時間の10%から20%を使用できます。 ツール。
当初はこの記事にSAR(System Activity Reporter)を含めるつもりでしたが、この記事が長くなるにつれて、SARはこれらの監視ツールとは大幅に異なり、 別の記事です。そのことを念頭に置いて、SARと/ procファイルシステムに関する記事と、これらすべてのツールを使用して問題を特定して解決する方法に関する3番目の記事を作成する予定です。
