Information är nyckeln till att lösa alla datorproblem, inklusive problem med eller relaterar till Linux och hårdvaran som den körs på. Det finns många verktyg tillgängliga för och ingår i de flesta distributioner även om de inte alla är installerade som standard. Dessa verktyg kan användas för att få enorma mängder information.
Den här artikeln diskuterar några av de interaktiva kommandoradsgränssnittsverktygen (CLI) som levereras med eller som enkelt kan installeras på Red Hat-relaterade distributioner inklusive Red Hat Enterprise Linux, Fedora, CentOS och andra derivatdistributioner. Även om det finns GUI-verktyg tillgängliga och de erbjuder bra information, ger CLI-verktygen samma information och de är alltid användbara eftersom många servrar inte har ett GUI-gränssnitt men alla Linux-system har ett kommandoradsgränssnitt.
Den här artikeln koncentrerar sig på de verktyg jag brukar använda. Om jag inte täckte över ditt favoritverktyg, förlåt mig och låt oss alla veta vilka verktyg du använder och varför i kommentarfältet.
Min gå till verktyg för problembedömning i en Linux-miljö är nästan alltid verktyg för systemövervakning. För mig är dessa top, atop, htop och blickar.
Alla dessa verktyg övervakar CPU- och minnesanvändning, och de flesta av dem visar åtminstone information om körningsprocesser. Vissa övervakar också andra aspekter av ett Linux-system. Alla ger nästan realtidsvyer av systemaktiviteter.
Belastningsmedelvärden
Innan jag fortsätter att diskutera övervakningsverktygen är det viktigt att diskutera belastningsgenomsnitt mer detaljerat.
Belastningsmedelvärden är ett viktigt kriterium för att mäta CPU-användning, men vad betyder det egentligen när jag säger att 1 (eller 5 eller 10) minuters belastningsmedelvärde till exempel är 4,04? Belastningsgenomsnitt kan betraktas som ett mått på efterfrågan på CPU: n; det är ett tal som representerar det genomsnittliga antalet instruktioner som väntar på CPU-tid. Så detta är ett verkligt mått på CPU-prestanda, till skillnad från den vanliga ”CPU-procentsatsen” som inkluderar I / O-väntetider under vilka CPU inte riktigt fungerar.
Till exempel en fullt utnyttjad CPU med en processor skulle ha ett belastningsmedelvärde på 1. Detta innebär att processorn följer exakt efterfrågan; det har med andra ord perfekt utnyttjande. Ett belastningsmedelvärde på mindre än en innebär att processorn är underutnyttjad och ett belastningsmedelvärde större än 1 betyder att processorn är överutnyttjad och att det finns uppdämt, otillfredsställd efterfrågan. Till exempel indikerar ett belastningsmedelvärde på 1,5 i ett enda CPU-system att en tredjedel av CPU-instruktionerna tvingas vänta på att köras tills den som föregår det har slutförts.
Detta gäller också för flera processorer. Om ett 4 CPU-system har ett belastningsgenomsnitt på 4 så har det perfekt utnyttjande. Om det till exempel har ett belastningsmedelvärde på 3,24, är tre av dess processorer fullt utnyttjade och en används till cirka 76%. I exemplet ovan har ett 4-CPU-system ett belastningsmedelvärde på 1 minut på 4,04 vilket innebär att det inte finns någon återstående kapacitet bland de 4 CPU: erna och några instruktioner tvingas vänta. Ett perfekt utnyttjat 4 CPU-system skulle visa ett belastningsmedelvärde på 4,00 så att systemet i exemplet är fullastat men inte överbelastat.
Det optimala villkoret för belastningsgenomsnitt är att det motsvarar det totala antalet CPU: er i ett system. Det skulle innebära att varje processor är fullt utnyttjad och ändå måste ingen instruktion tvingas vänta. Långsiktiga belastningsmedelvärden ger en indikation på den totala användningsutvecklingen.
Linux Journal har en utmärkt artikel som beskriver belastningsmedelvärden, teorin och matematiken bakom dem och hur man tolkar dem den 1 december 2006 problem.
Signaler
Alla de skärmar som diskuteras här tillåter dig att skicka signaler till pågående processer. Var och en av dessa signaler har en specifik funktion, även om vissa av dem kan definieras av det mottagande programmet med hjälp av signalhanterare.
Det separata dödkommandot kan också användas för att skicka signaler till processer utanför bildskärmarna. Kill -l kan användas för att lista alla möjliga signaler som kan skickas. Tre av dessa signaler kan användas för att döda en process.
- SIGTERM (15): Signal 15, SIGTERM är standardsignalen som skickas av toppen och de andra bildskärmarna när k-knappen trycks in. Det kan också vara det minst effektiva eftersom programmet måste ha en signalhanterare inbyggd i det. Programmets signalhanterare måste fånga inkommande signaler och agera därefter. Så för skript, av vilka de flesta inte har signalhanterare, ignoreras SIGTERM. Tanken bakom SIGTERM är att genom att helt enkelt säga till programmet att du vill att det ska avslutas själv det kommer att dra nytta av det och städa upp saker som öppna filer och sedan avsluta sig på ett kontrollerat och trevligt sätt.
- SIGKILL (9): Signal 9, SIGKILL ger ett sätt att döda även de mest motstridiga programmen , inklusive skript och andra program som inte har några signalhanterare.För skript och andra program utan signalhanterare dödar det inte bara det körande skriptet utan det dödar också shell-sessionen där skriptet körs; det här kanske inte är det beteende du vill ha. Om du vill döda en process och du inte bryr dig om att vara trevlig är det signalen du vill ha. Denna signal kan inte fångas upp av en signalhanterare i programkoden.
- SIGINT (2): Signal 2, SIGINT kan användas när SIGTERM inte fungerar och du vill att programmet ska dö lite snyggare, till exempel utan att döda shell-sessionen där den körs. SIGINT skickar ett avbrott till sessionen där programmet är körning. Det motsvarar att ett pågående program avslutas, särskilt ett skript, med tangentkombinationen Ctrl-C.
För att experimentera med detta, öppna en terminalsession och skapa en fil i / tmp heter cpuHog och gör den körbar med behörigheterna rwxr_xr_x. Lägg till följande innehåll i filen.
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
Öppna en annan terminalsession i ett annat fönster, placera dem intill till varandra så att du kan se resultaten och köra topp i den nya sessionen. Kör programmet cpuHog med följande kommando:
Detta program räknar helt enkelt upp en och skriver ut det aktuella värdet av X till STDOUT. Och det suger upp CPU-cykler. Terminal sessionen där cpuHog körs bör visa en mycket hög CPU-användning i toppen. Observera vilken effekt detta har på systemprestanda i topp. CPU-användning bör omedelbart gå upp och belastningsgenomsnittet bör också börja öka över tiden. Om du vill kan du öppna ytterligare terminalsessioner och starta cpuHog-programmet i dem så att du kör flera instanser.
Bestäm PID för det cpuHog-program du vill döda. Tryck på k-tangenten och titta på meddelandet under bytelinjen längst ner i sammanfattningsavsnittet. Top ber om PID för den process du vill döda. Ange PID och tryck Enter. Nu frågar toppen efter signalnumret och visar standardvärdet 15. Testa var och en av signalerna som beskrivs här och följ resultaten.
4 öppen källkodsverktyg för Linux-systemövervakning
En av de första verktygen jag använder när jag utför problembestämning är topp. Jag gillar det eftersom det har funnits sedan alltid och alltid finns tillgängligt medan de andra verktygen kanske inte är installerade.
Toppprogrammet är ett mycket kraftfullt verktyg som ger mycket information om ditt löpande system. Detta inkluderar data om minnesanvändning, CPU-laddningar och en lista över pågående processer inklusive hur mycket CPU-tid och minne som används av varje process. Top visar systeminformation i nästan realtid och uppdateras (som standard) var tredje sekund. Fraktionerade sekunder är tillåtna av toppen, även om mycket små värden kan placera systemet väsentligt. Det är också interaktivt och datakolumnerna som ska visas och sorteringskolumnen kan modifieras.
Ett exempel på utdata från topprogrammet visas i figur 1 nedan. Utgången uppifrån är uppdelad i två sektioner som kallas ”sammanfattnings” -sektionen, som är den övre delen av utgången, och ”process” -sektionen som är den nedre delen av utgången; Jag kommer att använda denna terminologi för top, atop, htop och blickar av intresse för konsistens.
Toppprogrammet har ett antal användbara interaktiva kommandon som du kan använda för att hantera visning av data och för att manipulera enskilda processer . Använd kommandot h för att visa en kort hjälpsida för de olika interaktiva kommandona. Se till att trycka två gånger på h för att se båda sidorna i hjälpen. Använd kommandot q för att avsluta.
Sammanfattningsavsnitt
Sammanfattningsavsnittet för utgången från toppen är en översikt över systemstatusen. Den första raden visar systemets driftstid och medelvärdet för 1, 5 och 15 minuter. I exemplet nedan är belastningsmedelvärdet 4,04, 4,17 respektive 4,06.
Den andra raden visar antalet processer som är aktiva och status för varje.
Raderna som innehåller CPU-statistik visas därefter. Det kan finnas en enda rad som kombinerar statistiken för alla processorer som finns i systemet, som i exemplet nedan, eller en rad för varje CPU; när det gäller den dator som används i exemplet är detta en enda fyrkärnig CPU. Tryck på 1-tangenten för att växla mellan konsoliderad visning av CPU-användning och visning av enskilda CPU: er. Data i dessa rader visas som procentsatser av den totala tillgängliga CPU-tiden.
Dessa och de andra fälten för CPU-data beskrivs nedan.
- us: userpace – Applications och andra program som körs i användarutrymmet, dvs. inte i kärnan.
- sy: systemanrop – funktioner på kärnnivå. Detta inkluderar inte CPU-tid som kärnan tar, bara kärnsystemet ringer.
- ni: trevligt – Processer som körs på en positiv trevlig nivå.
- id: tomgång – Tomgångstid, dvs. tid som inte används av någon pågående process.
- wa: vänta – CPU-cykler som spenderas på att I / O ska inträffa. Detta är bortkastad CPU-tid.
- hej: hårdvaruavbrott – CPU-cykler som används för att hantera hårdvaruavbrott.
- si: programvaruavbrott – CPU-cykler som används för att hantera programvaruskapade avbrott som system kallar.
- st: stjäla tid – Andelen CPU-cykler som en virtuell CPU väntar på en riktig CPU medan hypervisor servar en annan virtuell processor.
De två sista raderna i sammanfattningen är minnesanvändning. De visar den fysiska minnesanvändningen inklusive både RAM och swap-utrymme.
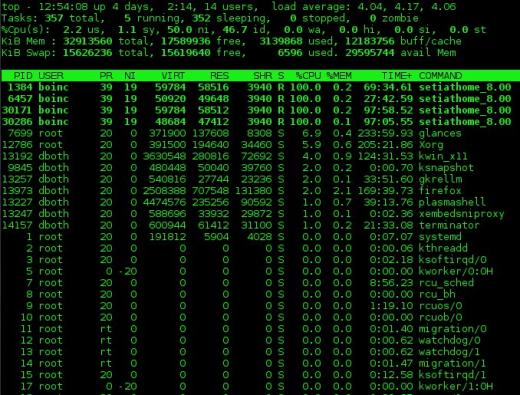
Bild 1: Det översta kommandot som visar en fullt utnyttjad 4-kärnig CPU.
Du kan använda kommandot 1 för att visa CPU-statistik som ett enda globalt nummer som visas i figur 1 ovan eller för en enskild CPU. Kommandot l aktiverar och inaktiverar belastningsmedelvärden. Kommandona t och m roterar process- / CPU- och minneslinjerna i sammanfattningsavsnittet genom av, endast text och ett par typer av stapeldiagramformat.
Processavsnitt
Processdelen av utdata från toppen är en lista över de körprocesser i systemet – åtminstone för antalet processer som det finns plats på terminalskärmen. Standardkolumnerna som visas överst beskrivs nedan. Flera andra kolumner är tillgängliga och var och en kan vanligtvis läggas till med ett enda tangenttryckning. Se den översta man-sidan för mer information.
- PID – Process-ID.
- ANVÄNDARE – Användarnamnet för processägaren.
- PR – Processens prioritet.
- NI – Det trevliga numret på processen.
- VIRT – Den totala mängden virtuellt minne som tilldelats processen.
- RES – Residentstorlek (i kb om inte annat anges) av icke-bytt fysiskt minne som konsumeras av en process.
- SHR – Mängden delat minne i kb som används av processen.
- S – Status för processen. Detta kan vara R för att springa, S för att sova och Z för zombie. Mindre frekvent sett status kan vara T för spåras eller stoppas och D för oavbruten sömn.
- % CPU – Andelen CPU-cykler, eller tid som används av denna process under den senast uppmätta tidsperioden.
- % MEM – Andelen fysiskt systemminne som används av processen.
- TIME + – Total CPU-tid till 100: e sekund som förbrukas av processen sedan processen startades.
- COMMAND – Detta är kommandot som användes för att starta processen.
Använd Page Up och Page Down för att bläddra igenom listan över pågående processer. Kommandona d eller s är utbytbara och kan användas för att ställa in fördröjningsintervallet mellan uppdateringar. Standardvärdet är tre sekunder, men jag föredrar ett intervall på en sekund. Intervallgranularitet kan vara så låg som en tiondel (0,1) av en sekund men detta kommer att förbruka mer av de CPU-cykler som du försöker mäta.
Du kan använda < och > -tangenter för att ordna sorteringskolumnen åt vänster eller höger.
K-kommandot används för att döda en process eller r-kommandot för att förneka det. Du måste känna till process-ID (PID) för den process du vill döda eller förlora och den informationen visas i processavsnittet på den övre skärmen. När du dödar en process, frågar top först om PID och sedan om signalnumret som ska användas för att döda processen. Skriv in dem och tryck på Enter-tangenten efter varje. Börja med signal 15, SIGTERM, och om det inte dödar processen, använd 9, SIGKILL.
Konfiguration
Om du ändrar den övre skärmen kan du använda W (i versal) för att skriva ändringarna i konfigurationsfilen, ~ / .toprc i din hemkatalog.
ovanpå
Jag gillar också ovanpå. Det är en utmärkt skärm att använda när du behöver mer information om den typen av I / O-aktivitet. Standard uppdateringsintervall är 10 sekunder, men detta kan ändras med kommandot intervall i till vad som är lämpligt för det du försöker göra. ovanpå kan inte uppdateras med intervaller på andra sekunder som toppburk.
Använd kommandot h för att visa hjälp. Var noga med att märka att det finns flera sidor med hjälp och du kan använda mellanslagstangenten för att bläddra ner för att se resten.
En trevlig funktion på toppen är att den kan spara råa prestandadata till en fil och spela sedan upp det senare för noggrann inspektion. Det här är praktiskt för att spåra intermittenta problem, särskilt sådana som inträffar när du inte kan övervaka systemet direkt. Atopsar-programmet används för att spela upp data i den sparade filen.
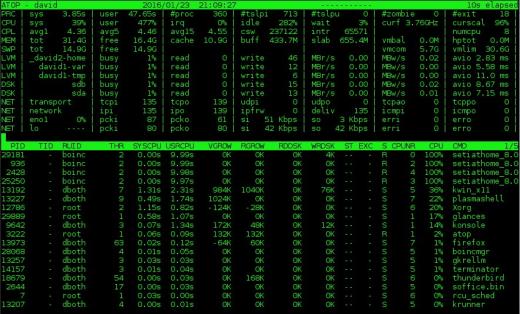 .
.
Bild 2: Systemmonitorn ovanpå ger information om disk och nätverksaktivitet utöver CPU- och processdata.
Sammanfattningsavsnitt
ovanpå innehåller mycket av samma information som top men visar också information om nätverk, rå disk och logisk volymaktivitet. Figur 2 ovan visar dessa ytterligare data i kolumnerna högst upp på skärmen.Observera att om du har den horisontella skärmen för att stödja en bredare skärm, kommer ytterligare kolumner att visas. Omvänt, om du har mindre horisontell bredd, visas färre kolumner. Jag gillar också att ovanpå visar den aktuella CPU-frekvensen och skalningsfaktorn – något jag inte har sett på någon annan av dessa skärmar – på andra raden i de två högsta kolumnerna i figur 2.
Processavsnitt
Skärmen ovanpå processen innehåller några av samma kolumner som för toppen, men den inkluderar också disk I / O-information och trådantal för varje process samt virtuell och verklig minnestillväxtstatistik för varje process. Som med sammanfattningsavsnittet kommer ytterligare kolumner att visas om det finns tillräckligt med horisontell skärmfastighet. Till exempel visas i figur 2 RUID (Real User ID) för processägaren. Expandering av skärmen visar också EUID (Effektiv användar-ID) som kan vara viktigt när program kör SUID (Set User ID).
ovanpå kan också ge detaljerad information om disk-, minne-, nätverks- och schemaläggningsinformation för varje process. Tryck bara på d-, m-, n- eller s-tangenterna för att visa data. G-tangenten returnerar skärmen till den generiska processvisningen.
Sortering kan göras enkelt genom att använda C för att sortera efter CPU-användning, M för minnesanvändning, D för diskanvändning, N för nätverksanvändning och A för automatisk sortering. Automatisk sortering sorterar vanligtvis processer efter den mest upptagna resursen. Nätverksanvändningen kan bara sorteras om netatop-kärnmodulen är installerad och laddad.
Du kan använda k-tangenten för att döda en process men det finns inget alternativ att avstå från en process.
Som standard visas inte nätverks- och skivenheter för vilka ingen aktivitet sker under ett visst tidsintervall. Detta kan leda till felaktiga antaganden om värdens hårdvarukonfiguration. Kommandot f kan användas för att tvinga ovanpå att visa lediga resurser.
Konfiguration
Atop man-sidan hänvisar till globala konfigurationsfiler och användarnivå, men ingen finns i min egna Fedora- eller CentOS-installationer. Det finns inte heller något kommando för att spara en modifierad konfiguration och ett sparande sker inte automatiskt när programmet avslutas. Så det verkar finnas nu sätt att göra konfigurationsändringar permanenta.
htop
Htop-programmet är ungefär som topp men på steroider. Det ser mycket ut som topp, men det ger också vissa funktioner som toppen inte gör. Till skillnad från ovanpå ger den dock ingen disk-, nätverks- eller I / O-information av någon typ.
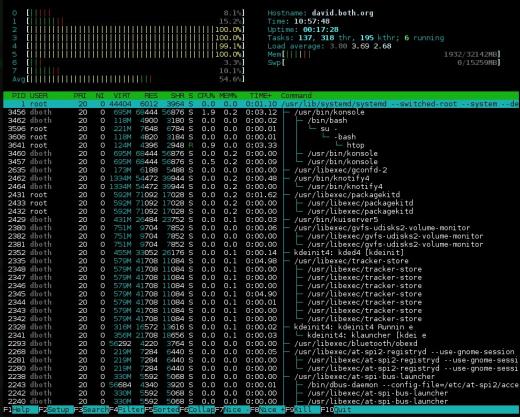
Figur 3: htop har fina stapeldiagram för att indikera resursanvändning och det kan visa processträdet.
Sammanfattningsavsnitt
Sammanfattningsavsnittet för htop visas i två kolumner. Den är mycket flexibel och kan konfigureras med flera olika typer av information i stort sett vilken beställning du vill. Även om CPU-användningsdelarna överst och ovanpå kan växlas mellan en kombinerad skärm och en skärm som visar ett stapeldiagram för varje CPU, kan htop inte. Så det har ett antal olika alternativ för CPU-skärmen, inklusive ett enda kombinerat fält, ett fält för varje CPU och olika kombinationer där specifika processorer kan grupperas i en enda stapel.
Jag tror detta är en renare sammanfattningsskärm än några av de andra systemmonitorerna och det är lättare att läsa. Nackdelen med det här sammanfattningsavsnittet är att viss information inte finns tillgänglig på htop som är tillgänglig i de andra bildskärmarna, till exempel CPU-procentandelar efter användare, tomgång och systemtid.
F2 (Setup) -tangenten är används för att konfigurera sammanfattningen av htop. En lista över tillgängliga datavisningar visas och du kan använda funktionstangenterna för att lägga till dem till vänster eller höger kolumn och för att flytta dem upp och ner i den valda kolumnen.
Processavsnitt
Processdelen på htop liknar väldigt högt. Som med de andra bildskärmarna kan processer sorteras på olika faktorer, inklusive CPU- eller minnesanvändning, användare eller PID. Observera att det inte går att sortera när trädvyn är vald.
F6-tangenten låter dig välja sorteringskolumn; den visar en lista över de kolumner som är tillgängliga för sortering och du väljer den kolumn du vill ha och trycker på Enter-tangenten.
Du kan använda upp- och nedpilen för att välja en process. För att döda en process, använd uppåt- och nedåtpilen för att välja målprocessen och tryck på k-tangenten. En lista med signaler för att skicka processen visas med 15, SIGTERM, vald. Du kan ange vilken signal som ska användas, om den skiljer sig från SIGTERM. Du kan också använda tangenterna F7 och F8 för att avstå från den valda processen.
Ett kommando som jag gillar särskilt är F5 som visar körprocesserna i ett trädformat vilket gör det enkelt att bestämma föräldrar / barnförhållanden för att köra processer.
Konfiguration
Varje användare har sin egen konfigurationsfil, ~ / .config / htop / htoprc och ändringar i htop-konfigurationen lagras där automatiskt.Det finns ingen global konfigurationsfil för htop.
blickar
Jag har nyligen lärt mig blickar, som kan visa mer information om din dator än någon annan bildskärm som jag känner för närvarande med. Detta inkluderar disk- och nätverks-I / O, termiska avläsningar som kan visa CPU- och andra hårdvarutemperaturer samt fläkthastigheter och diskanvändning per hårdvaruenhet och logisk volym.
Nackdelen med att ha all denna information är att blickar använder en betydande mängd CPU-resurces själv. På mina system hittar jag att den kan använda från cirka 10% till 18% av CPU-cyklerna. Det är mycket så du bör tänka på den effekten när du väljer din bildskärm.
Sammanfattningsavsnitt
Sammanfattningsavsnittet med blickar innehåller mest av samma information som sammanfattningsavsnitten för de andra bildskärmar. Om du har tillräckligt med horisontell skärmfastighet kan den visa CPU-användning med både ett stapeldiagram och en numerisk indikator, annars visar det bara numret.
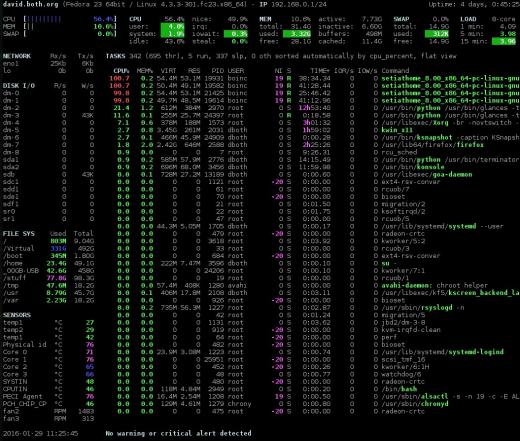
Bild 4: Blickar gränssnittet med nätverks-, disk-, filsystem- och sensorinformation.
Jag gillar det här sammanfattningsavsnittet bättre än de andra skärmarna. Jag tror att det ger rätt information i ett lättförståeligt format. Som med atop och htop kan du trycka på 1-tangenten för att växla mellan en visning av de enskilda CPU-kärnorna eller en global en med alla CPU-kärnorna som ett enda genomsnitt som visas i figur 4 ovan.
Processavsnitt
Processavsnittet visar standardinformation om var och en av de pågående processerna. Processer kan sorteras automatiskt a, eller efter CPU c, minne m, namn p, användare u, I / O-hastighet i eller tid t. När automatiskt sorteras sorteras processerna först efter den mest använda resursen.
Blickar visar också varningar och kritiska varningar längst ner på skärmen, inklusive tid och varaktighet för händelsen. Detta kan vara till hjälp när du försöker diagnostisera problem när du inte kan stirra på skärmen i timmar i taget. Dessa varningsloggar kan slås på eller av med l-kommandot, varningar kan rensas med w-kommandot medan varningar och varningar alla kan rensas med x.
Det är intressant att blickar är den enda av dessa skärmar som inte kan användas för att döda eller avstå från en process. Den är strikt avsedd som en bildskärm. Du kan använda kommandona för extern dödning och förnyelse för att manipulera processer.
Sidofält
Blickar har en mycket trevlig sidofält som visar information som inte är tillgänglig i topp eller htop. Atop visar viss del av denna data, men blickar är den enda bildskärmen som visar sensordata. Ibland är det trevligt att se temperaturerna i din dator. De enskilda modulerna, skivan, filsystemet, nätverket och sensorerna kan växlas till och från med kommandona d, f, n och s. Hela sidofältet kan växlas med hjälp av 2.
Dockerstatistik kan visas med D.
Konfiguration
Blickar kräver inte att en konfigurationsfil fungerar korrekt. Om du väljer att ha en, kommer den systemomfattande instansen av konfigurationsfilen att finnas i /etc/glances/glances.conf. Enskilda användare kan ha en lokal instans på ~ / .config / glances / glances.conf som åsidosätter den globala konfigurationen. Det primära syftet med dessa konfigurationsfiler är att ställa in trösklar för varningar och kritiska varningar. Det finns inget sätt jag kan göra för att göra andra konfigurationsändringar – som sidofältsmoduler eller CPU-skärmar – permanenta. Det verkar som att du måste konfigurera om dessa objekt varje gång du startar blickar.
Det finns ett dokument, /usr/share/doc/glances/glances-doc.html, som ger mycket information om hur du använder blickar, och det står uttryckligen att du kan använda konfigurationsfilen för att konfigurera vilka moduler som visas. Varken informationen eller exemplen beskriver dock hur man gör det.
Slutsats
Var noga med att läsa mansidorna för var och en av dessa bildskärmar eftersom det finns en stor mängd information om att konfigurera och interagera med dem. Använd också h-knappen för hjälp i interaktivt läge. Denna hjälp kan ge dig information om att välja och sortera datakolumnerna, ställa in uppdateringsintervallet och mycket mer.
Dessa program kan berätta mycket när du letar efter orsaken till ett problem. De kan berätta när en process, och vilken, suger upp CPU-tid, om det finns tillräckligt med ledigt minne, om processer är stoppade medan du väntar på att I / O, till exempel disk- eller nätverksåtkomst, och mycket mer.
Jag rekommenderar starkt att du spenderar tid på att titta på dessa övervakningsprogram medan de körs i ett system som fungerar normalt så att du kan skilja på de saker som kan vara onormala medan du letar efter orsaken till ett problem.
Du bör också vara medveten om att användningen av dessa övervakningsverktyg förändrar systemets resursanvändning inklusive minne och CPU-tid.topp och de flesta av dessa skärmar använder kanske 2% eller 3% av systemets CPU-tid. blickar har mycket större inverkan än de andra och kan använda mellan 10% och 20% av CPU-tiden. Var noga med att överväga detta när du väljer din verktyg.
Jag hade ursprungligen tänkt att inkludera SAR (System Activity Reporter) i den här artikeln men eftersom den här artikeln blev längre blev det också klart för mig att SAR skiljer sig avsevärt från dessa övervakningsverktyg och förtjänar att ha en separat artikel. Så med det i åtanke planerar jag att skriva en artikel om SAR och / proc-filsystemet och en tredje artikel om hur man använder alla dessa verktyg för att hitta och lösa problem.
