Introduzione all’istruzione MERGE e alla modifica dei dati di SQL Server
L’istruzione MERGE viene utilizzata per apportare modifiche in una tabella in base a valori corrispondenti a un’altra. Può essere utilizzato per combinare operazioni di inserimento, aggiornamento ed eliminazione in un’unica istruzione. In questo articolo, esploreremo come utilizzare l’istruzione MERGE. Discutiamo alcune best practice, limitazioni e conclusioni con diversi esempi.
Questo è il quinto articolo di una serie di articoli. Puoi iniziare dall’inizio leggendo Introduzione alle istruzioni di modifica dei dati di SQL Server.
Tutti gli esempi di questa lezione si basano su Microsoft SQL Server Management Studio e sul database AdventureWorks2012. Puoi iniziare a utilizzare questi strumenti gratuiti utilizzando la mia Guida Introduzione all’uso di SQL Server
Prima di iniziare
Sebbene questo articolo utilizzi il database AdventureWorks per i suoi esempi, ho deciso di creare diverse tabelle di esempio da utilizzare all’interno del database per illustrare meglio i concetti trattati. Puoi trovare lo script che dovrai eseguire qui. Notare che esiste una sezione speciale relativa a MERGE.
Struttura di base
L’istruzione MERGE combina le operazioni INSERT, DELETE e UPDATE in una tabella. Una volta capito come funziona, vedrai che semplifica la procedura utilizzando tutte e tre le istruzioni separatamente per sincronizzare i dati.
Di seguito è riportato un formato generalizzato per l’istruzione merge.
MERGE targetTableUsing sourceTableON mergeConditionWHEN MATCHEDTHEN updateStatementWHEN NOT MATCHED BY TARGETTHEN insertStatementWHEN NOT MATCHED BY SOURCETHEN deleteStatement
L’istruzione merge funziona utilizzando due tabelle, sourceTable e targetTable. TargetTable è la tabella da modificare in base ai dati contenuti all’interno di sourceTable.
Le due tabelle vengono confrontate utilizzando una mergeCondition . Questa condizione specifica in che modo le righe di sourceTable vengono abbinate a targetTable. Se hai familiarità con INNER JOINS, puoi pensare a questa come alla condizione di join utilizzata per abbinare le righe.
In genere, faresti corrispondere un identificatore univoco, come una chiave primaria. Se la tabella di origine fosse NewProduct e ProductMaster di destinazione e la chiave primaria per entrambi ProductID, una buona condizione di unione da utilizzare sarebbe:
NewProduct.ProductID = ProductMaster.ProductID
Ne risulta una condizione di unione in uno dei tre stati: MATCHED, NOT MATCHED o NOT MATCHED BY SOURCE.
Condizioni di unione
Esaminiamo il significato delle varie condizioni:
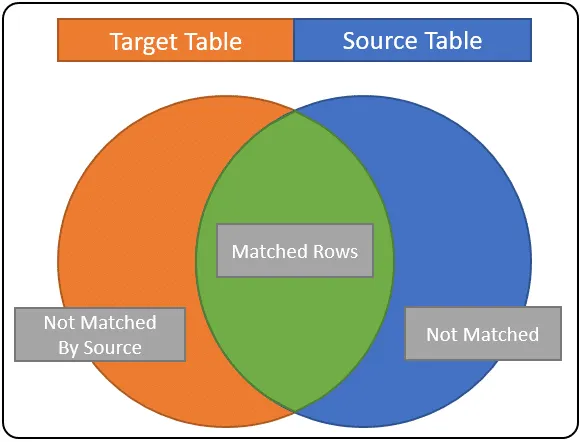
MATCHED – queste sono righe che soddisfano la condizione di corrispondenza. Sono comuni sia alla tabella di origine che a quella di destinazione. Nel nostro diagramma, sono mostrati in verde. Quando utilizzi questa condizione in una dichiarazione di fusione, tu; più come aggiornare le colonne delle righe di destinazione con i valori delle colonne sourceTable.
NOT MATCHED – Questo è noto anche come NOT MATCHED BY TARGET; si tratta di righe della tabella di origine che non corrispondevano ad alcuna riga nella tabella di destinazione. Queste righe sono rappresentate dall’area blu sopra. Nella maggior parte dei casi può essere utilizzato per dedurre che le righe di origine devono essere aggiunte a targetTable.
NON MATCHED BY SOURCE – si tratta di righe nella tabella di destinazione che non sono mai state trovate da un record di origine; queste sono le righe nell’area arancione. Se il tuo scopo è sincronizzare completamente i dati targetTable con l’origine, utilizzerai questa condizione di corrispondenza per CANCELLARE le righe.
Se hai problemi a capire come funziona, considera che la condizione di unione è come una condizione di join. ROWS nella sezione verde rappresentano le righe che corrispondono alla condizione di unione, le righe nella sezione blu sono quelle righe trovate nella SourceTable, ma non nella destinazione. Le righe nella sezione arancione sono quelle che si trovano solo nella destinazione.
Fornisci questi scenari di corrispondenza, sei in grado di incorporare facilmente le attività di aggiunta, rimozione e aggiornamento in una singola istruzione per sincronizzare le modifiche tra due tabelle.
Diamo un’occhiata a un esempio.
Esempio MERGE
Supponiamo che il nostro obiettivo sia sincronizzare tutte le modifiche apportate a esqlProductSource con esqlProductTarget. Ecco un diagramma di queste due tabelle:
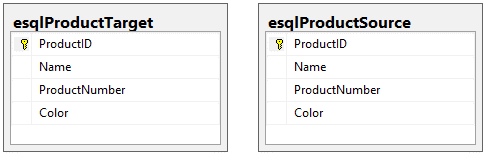
Nota: per il bene di questo esempio ho eseguito gli script di cui ho parlato nell’introduzione per creare e popolare due tabelle: esqlProductSource ed esqlProductTarget.
Prima di costruire l’istruzione MERGE, diamo un’occhiata a come sincronizzeremo la tabella utilizzando l’istruzione UPDATE, INSERT e DELETE per modificare, aggiungere e rimuovere le righe nella tabella di destinazione.
Penso che una volta visto come lo facciamo individualmente, vedere combinati in un’unica operazione abbia più senso.
Usare UPDATE per sincronizzare le modifiche da una tabella a quella successiva
Per aggiornare la tabella di destinazione con i valori modificati nell’origine del prodotto, è possibile utilizzare un’istruzione UPDATE. Dato che ProductID è la chiave primaria di entrambe le tabelle, diventa la nostra scelta migliore per le righe di corrispondenza tra le tabelle.
Se dovessimo aggiornare i valori delle colonne nella tabella di destinazione utilizzando la colonna di origine, potremmo farlo utilizzando la seguente istruzione di aggiornamento
UPDATE esqlProductTargetSET Name = S.Name, ProductNumber = S.ProductNumber, Color = S.ColorFROM esqlProductTarget T INNER JOIN esqlProductSource S ON S.ProductID = T.ProductID
Questa istruzione aggiornerà la colonna in esqlProductTarget con i valori di colonna corrispondenti trovati in esqlProductSource per la corrispondenza dell’ID del prodotto.
INSERT Righe trovate in una tabella ma non nell’altra
Ora vediamo come può identificare le righe dalla tabella di origine che dobbiamo inserire nella destinazione del prodotto. Per fare ciò possiamo utilizzare la subquery per trovare righe nella tabella di origine che non sono nella destinazione.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Nota: potrei anche usare un join esterno fare lo stesso. Se sei interessato al motivo, consulta questo articolo.
Questa istruzione inserirà una nuova riga in esqlProductTarget da tutte le righe in esqlProductSource che non si trovano in esqlProductTarget.
Rimozione Righe
L’ultima attività di sincronizzazione che dobbiamo eseguire, rimuove tutte le righe nella tabella di destinazione che non si trovano in SQL Source. Come abbiamo fatto con l’istruzione insert, useremo una sottoquery. Ma questa volta identificheremo le righe in esqlProductTarget non trovate in esqlProductSource. Ecco l’istruzione DELETE che possiamo usare:
DELETE esqlProductTargetFROM esqlProductTarget TWHERE NOT EXISTS (SELECT S.ProductID FROM esqlProductSource S WHERE T.ProductID = S.ProductID)
Ora che hai visto come eseguire le varie operazioni individualmente, vediamo come si uniscono nella dichiarazione di unione.
Notare che la maggior parte del lavoro pesante è svolto dalla condizione di unione e dai suoi risultati. Invece di dover impostare ripetutamente la corrispondenza, come abbiamo fatto nell’istruzione delete, viene eseguita una volta.
Confronta di nuovo l’istruzione Insert con l’istruzione merge sopra.
INSERT INTO esqlProductTarget (ProductID, Name, ProductNumber, Color)SELECT S.ProductID, S.Name, S.ProductNumber, S.ColorFROM esqlProductSource SWHERE NOT EXISTS (SELECT T.ProductID FROM esqlProductTarget T WHERE T.ProductID = S.ProductID)
Dato che l’istruzione MERGE stabilisce la tabella di origine e di destinazione, nonché il modo in cui corrispondono, tutto il codice colore in rosso è ridondante; quindi, non nella parte di inserimento della fusione.
Registrazione delle modifiche MERGE utilizzando OUTPUT
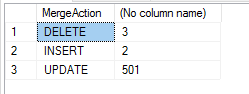
È possibile utilizzare la clausola OUTPUT per registrare le modifiche. In questo caso la variabile speciale $ action può essere utilizzata per registrare l’azione di unione. Questa variabile assumerà uno dei tre valori: “INSERT”, “UPDATE” o “DELETE”.
Continueremo a utilizzare il nostro esempio, ma questa volta registreremo le modifiche e riepilogheremo modifiche.
Se quanto sopra viene eseguito su nuovi dati campione, viene generato il seguente riepilogo: