La información es la clave para resolver cualquier problema informático, incluidos los problemas relacionados con Linux y el hardware en el que se ejecuta. Hay muchas herramientas disponibles e incluidas con la mayoría de las distribuciones, aunque no todas están instaladas de forma predeterminada. Estas herramientas se pueden utilizar para obtener grandes cantidades de información.
Este artículo analiza algunas de las herramientas de interfaz de línea de comandos interactivas (CLI) que se proporcionan o que se pueden instalar fácilmente en distribuciones relacionadas con Red Hat, incluida Red Hat Enterprise Linux, Fedora, CentOS y otras distribuciones derivadas. Aunque hay herramientas GUI disponibles y ofrecen buena información, las herramientas CLI brindan la misma información y siempre se pueden utilizar porque muchos servidores no tienen una interfaz GUI pero todos los sistemas Linux tienen una interfaz de línea de comandos.
Este artículo se concentra en las herramientas que normalmente uso. Si no cubrí su herramienta favorita, perdóneme y háganos saber qué herramientas usa y por qué en la sección de comentarios.
Mis herramientas para la determinación de problemas en un entorno Linux son casi siempre las herramientas de monitoreo del sistema. Para mí, estos son arriba, arriba, htop y miradas.
Todas estas herramientas monitorean el uso de CPU y memoria, y la mayoría de ellas enumeran información sobre los procesos en ejecución como mínimo. Algunos monitorean también otros aspectos de un sistema Linux. Todos brindan vistas casi en tiempo real de la actividad del sistema.
Promedios de carga
Antes de continuar con las herramientas de monitoreo, es importante discutir los promedios de carga con más detalle.
Los promedios de carga son un criterio importante para medir el uso de la CPU, pero ¿qué significa esto realmente cuando digo que el promedio de carga de 1 (o 5 o 10) minuto es 4.04, por ejemplo? El promedio de carga puede considerarse una medida de la demanda de la CPU; es un número que representa el número medio de instrucciones que esperan el tiempo de la CPU. Por lo tanto, esta es una verdadera medida del rendimiento de la CPU, a diferencia del «porcentaje de CPU» estándar, que incluye tiempos de espera de E / S durante los cuales la CPU no funciona realmente.
Por ejemplo, una CPU de sistema de procesador único completamente utilizada tendría un promedio de carga de 1. Esto significa que la CPU se mantiene exactamente al día con la demanda; en otras palabras, tiene una utilización perfecta. Un promedio de carga de menos de uno significa que la CPU está subutilizada y un promedio de carga de más de 1 significa que la CPU está sobreutilizada y que hay una demanda reprimida e insatisfecha. Por ejemplo, un promedio de carga de 1,5 en un solo sistema de CPU indica que un tercio de las instrucciones de la CPU se ven obligadas a esperar para ejecutarse hasta que se complete la anterior.
Esto también es cierto para múltiples procesadores. Si un sistema de 4 CPU tiene un promedio de carga de 4, entonces tiene una utilización perfecta. Si tiene un promedio de carga de 3,24, por ejemplo, tres de sus procesadores se utilizan por completo y uno se utiliza aproximadamente al 76%. En el ejemplo anterior, un sistema de 4 CPU tiene un promedio de carga de 1 minuto de 4.04, lo que significa que no hay capacidad restante entre las 4 CPU y algunas instrucciones se ven obligadas a esperar. Un sistema de 4 CPU perfectamente utilizado mostraría un promedio de carga de 4,00 para que el sistema del ejemplo esté completamente cargado pero no sobrecargado.
La condición óptima para el promedio de carga es que sea igual al número total de CPU en un sistema. Eso significaría que cada CPU se utiliza por completo y, sin embargo, no se debe forzar a ninguna instrucción a esperar. Los promedios de carga a largo plazo proporcionan una indicación de la tendencia general de utilización.
Linux Journal tiene un excelente artículo que describe los promedios de carga, la teoría y las matemáticas detrás de ellos, y cómo interpretarlos en el 1 de diciembre de 2006 problema.
Señales
Todos los monitores discutidos aquí le permiten enviar señales a procesos en ejecución. Cada una de estas señales tiene una función específica aunque algunas de ellas pueden ser definidas por el programa receptor usando manejadores de señales.
El comando kill separado también se puede usar para enviar señales a procesos fuera de los monitores. El kill -l se puede usar para listar todas las señales posibles que se pueden enviar. Tres de estas señales se pueden utilizar para matar un proceso.
- SIGTERM (15): Señal 15, SIGTERM es la señal predeterminada enviada por top y los otros monitores cuando se presiona la tecla k. También puede ser el menos efectivo porque el programa debe tener un manejador de señales integrado. El manejador de señales del programa debe interceptar las señales entrantes y actuar en consecuencia. Por lo tanto, para los scripts, la mayoría de los cuales no tienen manejadores de señales, SIGTERM se ignora. La idea detrás de SIGTERM es que simplemente diciéndole al programa que desea que se termine solo, se aprovechará de eso y limpiará cosas como archivos abiertos y luego se terminará de una manera controlada y agradable.
- SIGKILL (9): Señal 9, SIGKILL proporciona un medio para matar incluso los programas más recalcitrantes , incluidos scripts y otros programas que no tienen manejadores de señales.Sin embargo, para scripts y otros programas sin manejador de señales, no solo mata el script en ejecución, sino que también mata la sesión de shell en la que se ejecuta el script; puede que este no sea el comportamiento que desea. Si desea matar un proceso y no le importa ser amable, esta es la señal que desea. Esta señal no puede ser interceptada por un manejador de señales en el código del programa.
- SIGINT (2): La señal 2, SIGINT se puede usar cuando SIGTERM no funciona y desea que el programa muera un poco mejor, por ejemplo, sin matar la sesión de shell en la que se está ejecutando. SIGINT envía una interrupción a la sesión en la que el programa está Esto es equivalente a terminar un programa en ejecución, particularmente un script, con la combinación de teclas Ctrl-C.
Para experimentar con esto, abra una sesión de terminal y cree un archivo en / tmp llamado cpuHog y hacerlo ejecutable con los permisos rwxr_xr_x. Agregue el siguiente contenido al archivo.
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
Abra otra sesión de terminal en una ventana diferente, colóquelos adyacentes entre sí para que puedan ver los resultados y ejecutar la parte superior en la nueva sesión. Ejecute el programa cpuHog con el siguiente comando:
Este programa simplemente cuenta de uno en uno e imprime el valor actual de X en STDOUT. Y absorbe los ciclos de la CPU. La sesión de terminal en la que se ejecuta cpuHog debería mostrar un uso de CPU muy alto en la parte superior. Observe el efecto que esto tiene en el rendimiento del sistema en la parte superior. El uso de la CPU debería aumentar de inmediato y los promedios de carga también deberían comenzar a aumentar con el tiempo. Si lo desea, puede abrir sesiones de terminal adicionales e iniciar el programa cpuHog en ellas para que tenga varias instancias en ejecución.
Determine el PID del programa cpuHog que desea eliminar. Presione la tecla k y observe el mensaje debajo de la línea Swap en la parte inferior de la sección de resumen. Top solicita el PID del proceso que desea matar. Ingrese ese PID y presione Enter. Ahora top solicita el número de señal y muestra el valor predeterminado de 15. Pruebe cada una de las señales descritas aquí y observe los resultados.
4 herramientas de código abierto para la supervisión del sistema Linux
Una de Las primeras herramientas que utilizo al realizar la determinación de problemas son las mejores. Me gusta porque ha existido desde siempre y siempre está disponible, mientras que las otras herramientas pueden no estar instaladas.
El programa superior es una utilidad muy poderosa que proporciona una gran cantidad de información sobre su sistema en ejecución. Esto incluye datos sobre el uso de la memoria, las cargas de la CPU y una lista de los procesos en ejecución, incluida la cantidad de tiempo de la CPU y la memoria que utiliza cada proceso. Top muestra la información del sistema casi en tiempo real y se actualiza (de forma predeterminada) cada tres segundos. Los segundos fraccionarios están permitidos por top, aunque valores muy pequeños pueden colocar una carga significativa en el sistema. También es interactivo y las columnas de datos que se mostrarán y la columna de clasificación se pueden modificar.
En la Figura 1 a continuación se muestra un resultado de muestra del programa superior. La salida de la parte superior se divide en dos secciones que se denominan sección «resumen», que es la sección superior de la salida, y la sección «proceso», que es la parte inferior de la salida; Usaré esta terminología para top, atop, htop y miradas en aras de la coherencia.
El programa top tiene una serie de comandos interactivos útiles que puede usar para administrar la visualización de datos y manipular procesos individuales . Utilice el comando h para ver una breve página de ayuda para los distintos comandos interactivos. Asegúrese de presionar h dos veces para ver ambas páginas de la ayuda. Use el comando q para salir.
Sección de resumen
La sección de resumen de la salida desde arriba es una descripción general del estado del sistema. La primera línea muestra el tiempo de actividad del sistema y los promedios de carga de 1, 5 y 15 minutos. En el siguiente ejemplo, los promedios de carga son 4.04, 4.17 y 4.06 respectivamente.
La segunda línea muestra el número de procesos actualmente activos y el estado de cada uno.
Las líneas que contienen Las estadísticas de la CPU se muestran a continuación. Puede haber una sola línea que combine las estadísticas de todas las CPU presentes en el sistema, como en el ejemplo siguiente, o una línea para cada CPU; en el caso de la computadora utilizada para el ejemplo, se trata de una CPU de cuatro núcleos. Presione la tecla 1 para alternar entre la visualización consolidada del uso de la CPU y la visualización de las CPU individuales. Los datos en estas líneas se muestran como porcentajes del tiempo total de CPU disponible.
Estos y otros campos para datos de CPU se describen a continuación.
- us: espacio de usuario – Aplicaciones y otros programas que se ejecutan en el espacio del usuario, es decir, no en el kernel.
- sy: llamadas al sistema: funciones a nivel del kernel. Esto no incluye el tiempo de CPU que toma el propio kernel, solo las llamadas al sistema del kernel.
- ni: nice – Procesos que se están ejecutando a un nivel agradable positivo.
- id: idle – Tiempo de inactividad, es decir, tiempo que no utiliza ningún proceso en ejecución.
- wa: wait: ciclos de CPU que se gastan esperando que ocurra la E / S. Esto es tiempo de CPU desperdiciado.
- hi: interrupciones de hardware – ciclos de CPU que se gastan tratando con interrupciones de hardware.
- si: interrupciones de software – ciclos de CPU dedicados a tratar con interrupciones creadas por software tales como llamadas del sistema.
- st: robar tiempo: el porcentaje de ciclos de CPU que una CPU virtual espera para una CPU real mientras el hipervisor está dando servicio a otro procesador virtual.
Las dos últimas líneas de la sección de resumen son el uso de memoria. Muestran el uso de memoria física, incluyendo RAM y espacio de intercambio.
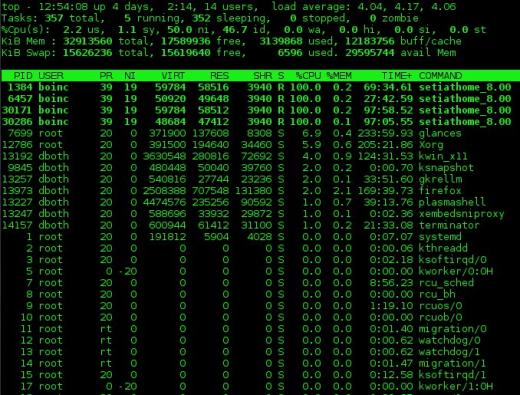
Figura 1: El comando superior que muestra una CPU de 4 núcleos totalmente utilizada.
Puede usar el comando 1 para mostrar las estadísticas de la CPU como un número global único como se muestra en la Figura 1, arriba, o por CPU individual. El comando l activa y desactiva los promedios de carga. Los comandos t y m rotan el proceso / CPU y las líneas de memoria de la sección de resumen, respectivamente, a través de apagado, solo texto y un par de tipos de formatos de gráfico de barras.
Sección de proceso
La sección de procesos de la salida de arriba es una lista de los procesos en ejecución en el sistema, al menos para el número de procesos para los que hay espacio en la pantalla del terminal. Las columnas predeterminadas que se muestran en la parte superior se describen a continuación. Hay varias otras columnas disponibles y cada una se puede agregar normalmente con una sola pulsación de tecla. Consulte la página de manual superior para obtener más detalles.
- PID: el ID del proceso.
- USER: el nombre de usuario del propietario del proceso.
- PR: La prioridad del proceso.
- NI – El buen número del proceso.
- VIRT – La cantidad total de memoria virtual asignada al proceso.
- RES – Tamaño residente (en kb, a menos que se indique lo contrario) de la memoria física no intercambiada consumida por un proceso.
- SHR – La cantidad de memoria compartida en kb utilizada por el proceso.
- S – El estado del proceso. Puede ser R para correr, S para dormir y Z para zombie. Los estados que se ven con menos frecuencia pueden ser T para rastreado o detenido, y D para suspensión ininterrumpida.
- % CPU: el porcentaje de ciclos de CPU o el tiempo utilizado por este proceso durante el último período de tiempo medido.
- % MEM: el porcentaje de memoria física del sistema utilizada por el proceso.
- TIEMPO +: tiempo total de CPU a centésimas de segundo consumido por el proceso desde que se inició.
- COMMAND – Este es el comando que se usó para iniciar el proceso.
Use las teclas Page Up y Page Down para desplazarse por la lista de procesos en ejecución. Los comandos d o s son intercambiables y se pueden utilizar para establecer el intervalo de retraso entre actualizaciones. El valor predeterminado es de tres segundos, pero prefiero un intervalo de un segundo. La granularidad del intervalo puede ser tan baja como una décima (0.1) de segundo, pero esto consumirá más ciclos de CPU que está tratando de medir.
Puede usar el < y > para secuenciar la columna de clasificación hacia la izquierda o hacia la derecha.
El comando k se usa para matar un proceso o el comando r para renice. Debe conocer el ID de proceso (PID) del proceso que desea matar o renice y esa información se muestra en la sección de proceso de la pantalla superior. Al matar un proceso, top pregunta primero por el PID y luego por el número de señal que se utilizará para matar el proceso. Escríbalos y presione la tecla Intro después de cada uno. Comience con la señal 15, SIGTERM, y si eso no mata el proceso, use 9, SIGKILL.
Configuración
Si modifica la pantalla superior, puede usar W (en mayúsculas) para escribir los cambios en el archivo de configuración, ~ / .toprc en su directorio de inicio.
encima
También me gusta encima. Es un monitor excelente para usar cuando necesite más detalles sobre ese tipo de actividad de E / S. El intervalo de actualización predeterminado es de 10 segundos, pero esto se puede cambiar usando el comando interval i a lo que sea apropiado para lo que está tratando de hacer. atop no se puede actualizar a intervalos de menos de un segundo como puede hacerlo top.
Utilice el comando h para mostrar la ayuda. Asegúrese de notar que hay varias páginas de ayuda y puede usar la barra espaciadora para desplazarse hacia abajo y ver el resto.
Una característica interesante de atop es que puede guardar datos de rendimiento sin procesar en un archivo y luego reprodúzcalo más tarde para una inspección más cercana. Esto es útil para rastrear problemas intermitentes, especialmente los que ocurren durante momentos en los que no puede monitorear directamente el sistema. El programa atopsar se usa para reproducir los datos en el archivo guardado.
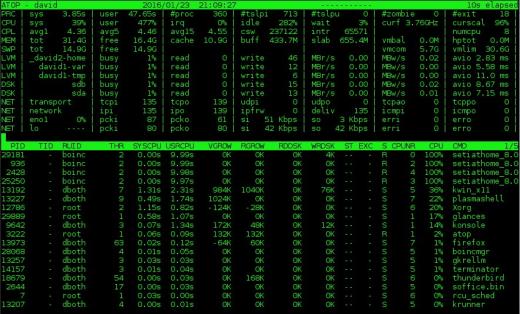 .
.
Figura 2: El monitor del sistema en la parte superior proporciona información sobre el disco y actividad de la red además de la CPU y los datos de proceso.
La sección de resumen
en la parte superior contiene gran parte de la misma información que en la parte superior, pero también muestra información sobre la red, el disco sin procesar y la actividad del volumen lógico. La Figura 2, arriba, muestra estos datos adicionales en las columnas en la parte superior de la pantalla.Tenga en cuenta que si tiene el espacio de la pantalla horizontal para admitir una pantalla más amplia, se mostrarán columnas adicionales. Por el contrario, si tiene menos ancho horizontal, se muestran menos columnas. También me gusta que en la parte superior se muestre la frecuencia actual de la CPU y el factor de escala, algo que no he visto en ningún otro de estos monitores, en la segunda línea de las dos columnas más a la derecha en la Figura 2.
Sección de proceso
La pantalla de proceso en la parte superior incluye algunas de las mismas columnas que la de la parte superior, pero también incluye información de E / S de disco y recuento de subprocesos para cada proceso, así como estadísticas de crecimiento de memoria virtual y real para cada proceso. Al igual que con la sección de resumen, se mostrarán columnas adicionales si hay suficiente espacio en la pantalla horizontal. Por ejemplo, en la Figura 2, se muestra el RUID (ID de usuario real) del propietario del proceso. Al expandir la pantalla, también se mostrará el EUID (ID de usuario efectivo) que puede ser importante cuando los programas ejecutan SUID (Establecer ID de usuario).
en la parte superior también puede proporcionar información detallada sobre el disco, la memoria, la red y la información de programación para cada proceso. Simplemente presione las teclas d, m, n o s respectivamente para ver esos datos. La tecla g devuelve la pantalla a la pantalla del proceso genérico.
La clasificación se puede lograr fácilmente usando C para clasificar por uso de CPU, M para uso de memoria, D para uso de disco, N para uso de red y A para clasificación automática. La clasificación automática generalmente clasifica los procesos por el recurso más ocupado. El uso de la red solo se puede ordenar si el módulo del kernel de netatop está instalado y cargado.
Puede usar la tecla k para matar un proceso, pero no hay opción para renunciar a un proceso.
De forma predeterminada, no se muestran los dispositivos de red y de disco para los que no se produce actividad durante un intervalo de tiempo determinado. Esto puede llevar a suposiciones erróneas sobre la configuración de hardware del host. El comando f se puede usar para forzar a arriba para mostrar los recursos inactivos.
Configuración
La página de manual de arriba se refiere a archivos de configuración de nivel global y de usuario, pero no se puede encontrar ninguno en mi propias instalaciones de Fedora o CentOS. Tampoco hay un comando para guardar una configuración modificada y no se guarda automáticamente cuando se termina el programa. Entonces, parece haber una manera de hacer que los cambios de configuración sean permanentes.
htop
El programa htop es muy parecido a top pero con esteroides. Se parece mucho a top, pero también proporciona algunas capacidades que top no tiene. Sin embargo, a diferencia de lo que ocurre en la parte superior, no proporciona información de E / S, red o disco de ningún tipo.
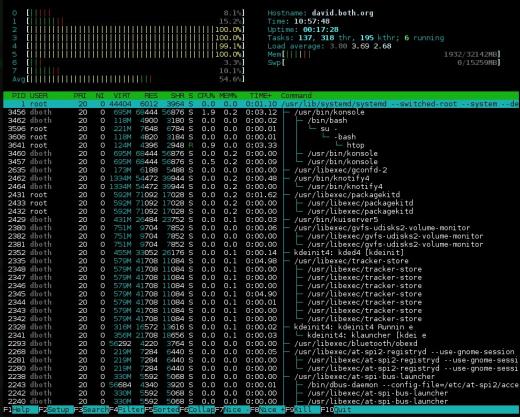
Figura 3: htop tiene buenos gráficos de barras para indicar el uso de recursos y puede mostrar el árbol de procesos.
Sección de resumen
La sección de resumen de htop se muestra en dos columnas. Es muy flexible y se puede configurar con varios tipos diferentes de información en prácticamente cualquier orden que desee. Aunque las secciones de uso de CPU de top y atop se pueden alternar entre una pantalla combinada y una pantalla que muestra un gráfico de barras para cada CPU, htop no puede. Por lo tanto, tiene varias opciones diferentes para la visualización de la CPU, incluida una sola barra combinada, una barra para cada CPU y varias combinaciones en las que las CPU específicas se pueden agrupar en una sola barra.
Creo esta es una pantalla de resumen más limpia que algunos de los otros monitores del sistema y es más fácil de leer. El inconveniente de esta sección de resumen es que cierta información no está disponible en htop que está disponible en los otros monitores, como los porcentajes de CPU por usuario, inactivo y tiempo del sistema.
La tecla F2 (Configuración) es utilizado para configurar la sección de resumen de htop. Se muestra una lista de las pantallas de datos disponibles y puede usar las teclas de función para agregarlas a la columna izquierda o derecha y moverlas hacia arriba y hacia abajo dentro de la columna seleccionada.
Sección de proceso
La sección de proceso de htop es muy similar a la de top. Al igual que con los otros monitores, los procesos se pueden clasificar según varios factores, incluido el uso de CPU o memoria, el usuario o el PID. Tenga en cuenta que la clasificación no es posible cuando se selecciona la vista de árbol.
La tecla F6 le permite seleccionar la columna de clasificación; muestra una lista de las columnas disponibles para ordenar y usted selecciona la columna que desea y presione la tecla Enter.
Puede usar las teclas de flecha hacia arriba y hacia abajo para seleccionar un proceso. Para matar un proceso, use las teclas de flecha hacia arriba y hacia abajo para seleccionar el proceso de destino y presione la tecla k. Se muestra una lista de señales para enviar el proceso con 15, SIGTERM, seleccionado. Puede especificar la señal a utilizar, si es diferente de SIGTERM. También puede usar las teclas F7 y F8 para cambiar el proceso seleccionado.
Un comando que me gusta especialmente es F5, que muestra los procesos en ejecución en un formato de árbol, lo que facilita la determinación de las relaciones padre / hijo de la ejecución. procesos.
Configuración
Cada usuario tiene su propio archivo de configuración, ~ / .config / htop / htoprc y los cambios a la configuración de htop se almacenan allí automáticamente.No hay un archivo de configuración global para htop.
glances
Recientemente aprendí acerca de glances, que pueden mostrar más información sobre su computadora que cualquiera de los otros monitores que conozco actualmente con. Esto incluye E / S de red y disco, lecturas térmicas que pueden mostrar la CPU y otras temperaturas de hardware, así como las velocidades de los ventiladores, y el uso del disco por dispositivo de hardware y volumen lógico.
El inconveniente de tener toda esta información Es que Glances usa una cantidad significativa de CPU resurge. En mis sistemas, encuentro que puede usar entre el 10% y el 18% de los ciclos de CPU. Eso es mucho, por lo que debe considerar ese impacto cuando elija su monitor.
Sección de resumen
La sección de resumen de miradas contiene la mayor parte de la información que las secciones de resumen de las otras monitores. Si tiene suficiente espacio en la pantalla horizontal, puede mostrar el uso de la CPU con un gráfico de barras y un indicador numérico; de lo contrario, solo mostrará el número.
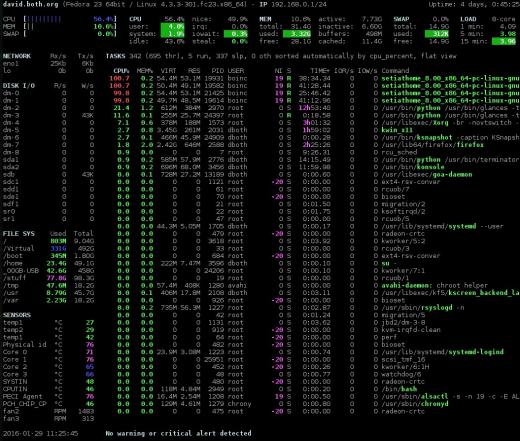
Figura 4: La interfaz de miradas con la red, el disco, el sistema de archivos y la información del sensor.
Me gusta más esta sección de resumen que las de los otros monitores; Creo que proporciona la información correcta en un formato fácilmente comprensible. Al igual que con arriba y arriba, puede presionar la tecla 1 para alternar entre una visualización de los núcleos de CPU individuales o una global con todos los núcleos de CPU como un promedio único, como se muestra en la Figura 4, arriba.
Sección de proceso
La sección de proceso muestra la información estándar sobre cada uno de los procesos en ejecución. Los procesos se pueden clasificar automáticamente a, o por CPU c, memoria m, nombre p, usuario u, tasa de E / S i, o tiempo t. Cuando se ordenan automáticamente, los procesos se ordenan primero por el recurso más utilizado.
Glances también muestra advertencias y alertas críticas en la parte inferior de la pantalla, incluida la hora y la duración del evento. Esto puede ser útil cuando se intenta diagnosticar problemas cuando no puede mirar la pantalla durante horas. Estos registros de alerta se pueden activar o desactivar con el comando l, las advertencias se pueden borrar con el comando w mientras que las alertas y las advertencias se pueden borrar con x.
Es interesante que miradas es el único de estos monitores que no se pueden utilizar para matar o renice un proceso. Está pensado estrictamente como monitor. Puede usar los comandos externos kill y renice para manipular procesos.
Sidebar
Glances tiene una barra lateral muy agradable que muestra información que no está disponible en top o htop. Encima muestra algunos de estos datos, pero miradas es el único monitor que muestra los datos de los sensores. A veces es bueno ver las temperaturas dentro de su computadora. Los módulos individuales, el disco, el sistema de archivos, la red y los sensores se pueden activar y desactivar mediante los comandos d, f, nys, respectivamente. La barra lateral completa se puede alternar usando 2.
Las estadísticas de Docker se pueden mostrar con D.
Configuración
Glances no requiere un archivo de configuración para funcionar correctamente. Si elige tener uno, la instancia de todo el sistema del archivo de configuración se ubicaría en /etc/glances/glances.conf. Los usuarios individuales pueden tener una instancia local en ~ / .config / glances / glances.conf que anulará la configuración global. El propósito principal de estos archivos de configuración es establecer umbrales para advertencias y alertas críticas. No hay forma de que pueda hacer otros cambios de configuración, como los módulos de la barra lateral o las pantallas de la CPU, permanentes. Parece que debe reconfigurar esos elementos cada vez que comienza a mirar.
Hay un documento, /usr/share/doc/glances/glances-doc.html, que proporciona una gran cantidad de información sobre el uso miradas, y declara explícitamente que puede usar el archivo de configuración para configurar qué módulos se muestran. Sin embargo, ni la información proporcionada ni los ejemplos describen cómo hacerlo.
Conclusión
Asegúrese de leer las páginas de manual de cada uno de estos monitores porque hay una gran cantidad de información sobre cómo configurarlos e interactuar con ellos. También use la tecla h para obtener ayuda en el modo interactivo. Esta ayuda puede proporcionarle información sobre cómo seleccionar y ordenar las columnas de datos, establecer el intervalo de actualización y mucho más.
Estos programas pueden decirle mucho cuando esté buscando la causa de un problema. Pueden decirle cuándo un proceso, y cuál, está consumiendo tiempo de CPU, si hay suficiente memoria libre, si los procesos están detenidos mientras esperan que se complete la E / S, como el acceso al disco o la red, y mucho más.
Le recomiendo encarecidamente que dedique tiempo a ver estos programas de supervisión mientras se ejecutan en un sistema que funciona normalmente para que pueda diferenciar aquellas cosas que pueden ser anormales mientras busca la causa de un problema.
También debe tener en cuenta que el hecho de utilizar estas herramientas de supervisión altera el uso de recursos del sistema, incluida la memoria y el tiempo de CPU.superior y la mayoría de estos monitores usan quizás el 2% o el 3% del tiempo de CPU de un sistema. Las miradas tienen mucho más impacto que los demás y pueden usar entre el 10% y el 20% del tiempo de CPU. Asegúrese de considerar esto al elegir su
Originalmente tenía la intención de incluir SAR (System Activity Reporter) en este artículo, pero a medida que este artículo se hizo más extenso, también me quedó claro que SAR es significativamente diferente de estas herramientas de monitoreo y merece tener un artículo separado. Con eso en mente, planeo escribir un artículo sobre SAR y el sistema de archivos / proc, y un tercer artículo sobre cómo usar todas estas herramientas para localizar y resolver problemas.
