Řazení bublin je jednoduchý algoritmus, který se používá k třídění dané sady n prvky poskytované ve formě pole s n počtem prvků. Bubble Sort porovnává všechny prvky jeden po druhém a třídí je na základě jejich hodnot.
Pokud má být dané pole seřazeno vzestupně, potom bublinové třídění začne porovnáním prvního prvku pole s druhý prvek, pokud je první prvek větší než druhý prvek, vymění oba prvky a poté přejde k porovnání druhého a třetího prvku atd.
Pokud máme celkem n prvků, pak musíme tento proces opakovat n-1 krát.
Je známý jako bublinové třídění, protože s každou úplnou iterací největší prvek v daném poli bubliny nahoru na poslední místo nebo nejvyšší index, stejně jako vodní bublina stoupá až k vodní hladině.
Třídění probíhá procházením všech prvky jeden po druhém a porovnat je se sousedním prvkem a podle potřeby je vyměnit.
POZNÁMKA: Pokud nejste obeznámeni s tříděním v datové struktuře, měli byste fi Nejprve se naučte, co je třídění, abyste věděli o základech třídění.
Implementace algoritmu třídění bublin
Následuje postup při třídění bublin (pro třídění daného pole ve vzestupném pořadí):
- Počínaje prvním prvkem (index = 0) porovnejte aktuální prvek s dalším prvkem pole.
- Pokud je aktuální prvek větší než další prvek pole, vyměňte je.
- Pokud je aktuální prvek menší než následující prvek, přejděte na další prvek. Opakujte krok 1.
Pojďme zvážit pole s hodnotami {5, 1, 6, 2, 4, 3}
Níže máme obrazová reprezentace toho, jak bude třídění bublin třídit dané pole.
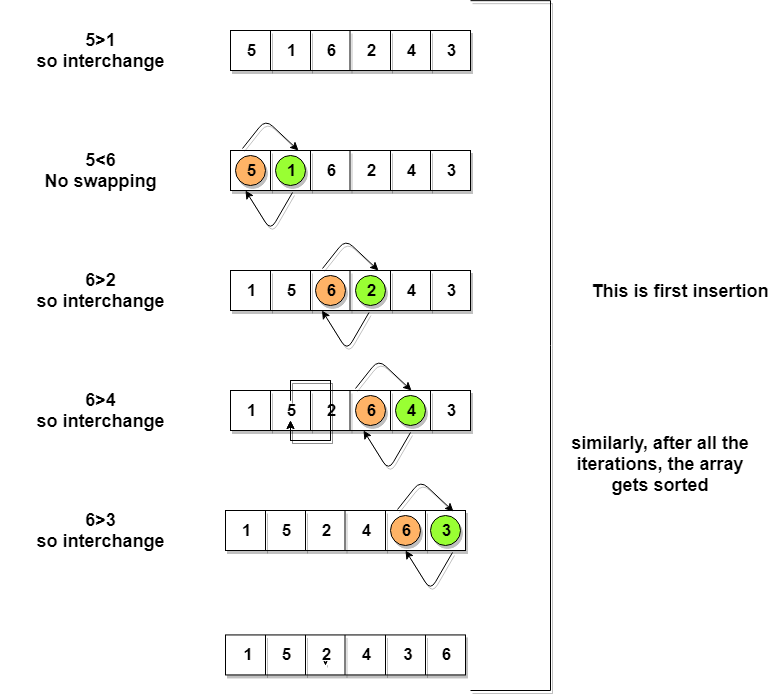
Jak tedy vidíme na vyobrazení výše, po první iterace, 6 se umístí na poslední index, který je pro ni správnou pozicí.
Podobně po druhé iteraci se 5 bude na druhém posledním indexu atd.
Čas na napsání kódu pro třídění bublin:
Ačkoli výše uvedená logika roztřídí netříděné pole, výše uvedený algoritmus není efektivní, protože podle výše uvedené logiky je vnější for bude pokračovat v provádění 6 iterací, i když se pole po druhé iteraci roztřídí.
Takže můžeme jasně optimalizovat náš algoritmus.
Optimalizovaný algoritmus třídění bublin
Optimalizovat naši bublinu Díky algoritmu třídění můžeme zavést flag ke sledování, zda se prvky vyměňují uvnitř vnitřní for smyčky.
Proto ve vnitřní for smyčce vždy kontrolujeme, zda dochází k záměně prvků.
Pokud pro konkrétní iteraci žádné záměny nebývají místo, to znamená, že pole bylo tříděno a my můžeme vyskočit ze smyčky for místo provádění všech iterací.
Pojďme uvažovat o poli s hodnotami {11, 17, 18, 26, 23}
Níže máme obrázkové znázornění toho, jak bude optimalizované třídění bublin třídit dané pole.

Jak vidíme, v první iteraci proběhla výměna, proto jsme aktualizovali naši flag hodnotu na 1 ve výsledku spuštění znovu vstoupí do smyčky for. Ale ve druhé iteraci nedojde k žádné výměně, proto hodnota flag zůstane 0 a provedení se vymyká smyčce.
Ve výše uvedeném kódu ve funkci bubbleSort, pokud pro jediný kompletní cyklus j iterace (vnitřní for smyčka), nedojde k žádné výměně, pak flag zůstane 0 a poté se vymaníme ze smyček for, protože pole již bylo tříděno.
Analýza složitosti třídění podle bublin
V třídění podle bublin bude n-1 srovnání provedeno v 1. průchodu, n-2 ve 2. průchodu, n-3 ve 3. průchodu atd. Celkový počet srovnání tedy bude,
(n-1) + (n-2) + (n-3) + ….. + 3 + 2 + 1 Sum = n (n- 1) /2i.e O (n2)
Proto je časová složitost Bubble Sort O (n2).
Hlavní výhodou Bubble Sort je jednoduchost algoritmu.
Složitost prostoru pro Bubble Sort je O (1), protože je vyžadován pouze jeden další paměťový prostor, tj. pro proměnnou temp.
Nejlepší časová složitost bude také O (n), tedy když je seznam již seřazen.
Následují časová a prostorová složitost algoritmu Bubble Sort.
Nyní, když jsme se naučili algoritmus třídění bublin, můžete vyzkoušet i tyto třídicí algoritmy a jejich aplikace:
- Třídění podle vložení
- Výběr podle řazení
- Rychlé řazení
- sloučit řazení
- Hromadné řazení
- Počítání řazení
