Informace jsou klíčem k vyřešení jakéhokoli problému s počítačem, včetně problémů s Linuxem a hardwarem, na kterém běží, nebo s ním souvisí. U většiny distribucí je k dispozici a je zahrnuto mnoho nástrojů, i když ve výchozím nastavení nejsou všechny nainstalovány. Tyto nástroje lze použít k získání obrovského množství informací.
Tento článek pojednává o některých nástrojích rozhraní příkazového řádku (CLI), které jsou k dispozici nebo které lze snadno nainstalovat na distribuce související s Red Hat, včetně Red Hat Enterprise Linux, Fedora, CentOS a další odvozené distribuce. Ačkoli jsou k dispozici nástroje GUI a nabízejí dobré informace, nástroje CLI poskytují všechny stejné informace a jsou vždy použitelné, protože mnoho serverů nemá rozhraní GUI, ale všechny systémy Linux mají rozhraní příkazového řádku.
Tento článek se soustředí na nástroje, které obvykle používám. Pokud jsem nepokryl váš oblíbený nástroj, prosím, odpusťte mi a dejte nám všem vědět, jaké nástroje používáte a proč v sekci komentářů.
Moje nástroje pro určení problému v prostředí Linuxu jsou téměř vždy nástroje pro monitorování systému. Pro mě jsou to top, atop, htop a glances.
Všechny tyto nástroje sledují využití procesoru a paměti a většina z nich obsahuje přinejmenším informace o spuštěných procesech. Některé monitorují i další aspekty systému Linux. Všechny poskytují pohledy na aktivitu systému v reálném čase.
Průměry zatížení
Než začnu diskutovat o monitorovacích nástrojích, je důležité podrobněji diskutovat průměry zatížení.
Průměry zatížení jsou důležitým kritériem pro měření využití CPU, ale co to opravdu znamená, když řeknu, že průměrná zátěž za 1 (nebo 5 nebo 10) minut je například 4,04? Průměr zatížení lze považovat za míru poptávky po CPU; je to číslo, které představuje průměrný počet instrukcí čekajících na čas CPU. Jedná se tedy o skutečnou míru výkonu CPU, na rozdíl od standardního „procenta CPU“, které zahrnuje čekací doby I / O, během nichž CPU ve skutečnosti nefunguje.
Například plně využívaný systém CPU s jedním procesorem by měl průměr zátěže 1. To znamená, že CPU drží krok přesně s poptávkou; jinými slovy má perfektní využití. Průměr zátěže menší než jedna znamená, že CPU je nedostatečně využíván a průměr zátěže větší než 1 znamená, že CPU je nadměrně využíván a že existuje zadržená, neuspokojená poptávka. Například průměr zatížení 1,5 v jednom systému CPU naznačuje, že jedna třetina instrukcí CPU je nucena čekat na provedení, dokud nedojde k dokončení předcházejícího.
To platí také pro více procesory. Pokud má systém se 4 CPU průměrnou zátěž 4, pak má perfektní využití. Pokud má průměr zatížení například 3,24, pak jsou plně využity tři z jeho procesorů a jeden je využíván na zhruba 76%. Ve výše uvedeném příkladu má systém 4 CPU průměr zatížení 1 minutu 4,04, což znamená, že mezi 4 CPU není zbývající kapacita a několik instrukcí je nuceno čekat. Dokonale využitý systém 4 CPU by vykazoval průměr zátěže 4,00, takže systém v příkladu je plně načtený, ale není přetížený.
Optimální podmínkou pro průměr zátěže je, aby se rovnal celkovému počtu CPU v systému. To by znamenalo, že každý CPU je plně využíván, a přesto není nutné nutit žádnou instrukci k čekání. Dlouhodobější průměry zátěže poskytují indikaci celkového trendu využití.
Linux Journal obsahuje vynikající článek popisující průměry zátěže, teorii a matematiku za nimi a jak je interpretovat v prosinci 1, 2006 problém.
Signály
Všechny zde popsané monitory vám umožňují odesílat signály spuštěným procesům. Každý z těchto signálů má specifickou funkci, i když některé z nich může přijímací program definovat pomocí obslužných rutin signálů.
Samostatný příkaz kill lze také použít k odesílání signálů do procesů mimo monitory. Kill -l lze použít k vypsání všech možných signálů, které lze odeslat. Tři z těchto signálů lze použít k ukončení procesu.
- SIGTERM (15): Signál 15, SIGTERM je výchozí signál odeslaný shora a ostatní monitory po stisknutí klávesy k. Může to být také nejméně efektivní, protože program musí mít zabudovaný obslužný program signálu. Obsluha signálu programu musí zachytit příchozí signály a podle toho jednat. U skriptů, z nichž většina nemá obsluhy signálů, je SIGTERM ignorován. Myšlenkou SIGTERMu je, že jednoduše řeknete programu, že chcete, aby se sám ukončil, využije toho a uklidí věci, jako jsou otevřené soubory, a poté se kontrolovaným a příjemným způsobem ukončí.
- SIGKILL (9): Signál 9, SIGKILL poskytuje prostředky k zabíjení i těch nejodpornějších programů , včetně skriptů a dalších programů, které nemají žádné obslužné rutiny signálu.U skriptů a jiných programů bez obslužné rutiny signálu však nezabije pouze spuštěný skript, ale také zabije relaci prostředí, ve kterém je skript spuštěn; toto nemusí být chování, které chcete. Pokud chcete zabít proces a nestaráte se o to, abyste byli milí, je to signál, který chcete. Tento signál nemůže být zachycen obsluhou signálu v kódu programu.
- SIGINT (2): Signál 2, SIGINT lze použít, když SIGTERM nefunguje a chcete, aby program umřel o něco hezčí, například bez zabití relace prostředí, ve které běží. SIGINT odešle přerušení relaci, ve které je program To je ekvivalentní ukončení běžícího programu, zejména skriptu, pomocí kombinace kláves Ctrl-C.
Chcete-li s tím experimentovat, otevřete relaci terminálu a vytvořte soubor v / tmp pojmenovaný cpuHog a zpřístupnit jej s oprávněními rwxr_xr_x. Přidejte do souboru následující obsah.
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
Otevřete další relaci terminálu v jiném okně a umístěte je vedle sebe navzájem, abyste mohli sledovat výsledky a běžet nahoře v nové relaci. Spusťte program cpuHog pomocí následujícího příkazu:
Tento program jednoduše spočítá o jednu a vytiskne aktuální hodnotu X na STDOUT. A nasává cykly CPU. Terminálová relace, ve které běží cpuHog, by měla nahoře vykazovat velmi vysoké využití CPU. Nejlépe sledujte vliv, který to má na výkon systému. Využití CPU by mělo okamžitě jít nahoru a průměrné zatížení by se také mělo časem začít zvyšovat. Pokud chcete, můžete otevřít další relace terminálu a spustit v nich program cpuHog, aby bylo spuštěno více instancí.
Určete PID programu cpuHog, který chcete zabít. Stiskněte klávesu k a podívejte se na zprávu pod řádkem Zaměnit ve spodní části souhrnné části. Top žádá o PID procesu, který chcete zabít. Zadejte tento PID a stiskněte klávesu Enter. Nyní se horní část zeptá na číslo signálu a zobrazí výchozí hodnotu 15. Vyzkoušejte každý ze zde popsaných signálů a sledujte výsledky.
4 nástroje open source pro monitorování systému Linux
Jeden z první nástroje, které používám při stanovení problému, jsou nejlepší. Líbí se mi, protože je tu odjakživa a je vždy k dispozici, zatímco ostatní nástroje nemusí být nainstalovány.
Špičkový program je velmi výkonný nástroj, který poskytuje velké množství informací o vašem běžícím systému. To zahrnuje data o využití paměti, zatížení CPU a seznam spuštěných procesů, včetně množství času CPU a paměti využívané jednotlivými procesy. Nahoře zobrazuje informace o systému téměř v reálném čase a aktualizuje se (ve výchozím nastavení) každé tři sekundy. Zlomkové sekundy jsou povoleny nahoře, i když velmi malé hodnoty mohou systém značně zatížit. Je také interaktivní a lze zobrazit sloupce dat, které se mají zobrazit, a sloupec řazení.
Ukázkový výstup z nejvyššího programu je uveden na obrázku 1 níže. Výstup shora je rozdělen na dvě části, které se nazývají část „souhrn“, což je horní část výstupu, a část „proces“, která je spodní částí výstupu; Tuto terminologii použiji pro top, atop, htop a pohledy v zájmu konzistence.
Špičkový program má řadu užitečných interaktivních příkazů, které můžete použít ke správě zobrazení dat a manipulaci s jednotlivými procesy. . Pomocí příkazu h můžete zobrazit krátkou stránku nápovědy pro různé interaktivní příkazy. Nezapomeňte dvakrát stisknout h, aby se zobrazily obě stránky nápovědy. Ukončete příkaz q.
Souhrnná část
Souhrnná část výstupu shora je přehledem stavu systému. První řádek zobrazuje dobu provozuschopnosti systému a průměrné zatížení 1, 5 a 15 minut. V níže uvedeném příkladu jsou průměrné hodnoty zatížení 4,04, 4,17 a 4,06.
Druhý řádek zobrazuje počet aktuálně aktivních procesů a stav každého z nich.
Řádky obsahující Statistiky CPU jsou zobrazeny dále. Může existovat jeden řádek, který kombinuje statistiky pro všechny CPU přítomné v systému, jako v příkladu níže, nebo jeden řádek pro každý CPU; v případě počítače použitého v tomto příkladu se jedná o jednojádrový CPU. Stisknutím klávesy 1 můžete přepínat mezi konsolidovaným zobrazením využití CPU a zobrazením jednotlivých CPU. Data v těchto řádcích se zobrazují jako procenta z celkového dostupného času CPU.
Tato a další pole pro data CPU jsou popsána níže.
- us: userspace – Applications a další programy spuštěné v uživatelském prostoru, tj. nikoli v jádře.
- sy: systémová volání – funkce na úrovni jádra. Nezahrnuje to čas CPU, který zabere samotné jádro, pouze volání systému jádra.
- ni: nice – procesy, které běží na kladné úrovni.
- id: idle – Doba nečinnosti, tj. Čas nevyužitý žádným spuštěným procesem.
- wa: wait – cykly CPU, které se utrácejí čekáním na vstup / výstup. Tímto se promrhá čas CPU.
- ahoj: hardwarová přerušení – cykly CPU, které se vynakládají na přerušení hardwaru.
- si: softwarové přerušení – cykly CPU strávené řešením softwarově vytvořených přerušení, například jako volání systému.
- st: steal time – Procento cyklů CPU, které virtuální CPU čeká na skutečné CPU, zatímco hypervisor obsluhuje jiný virtuální procesor.
Poslední dva řádky v souhrnné části jsou využití paměti. Ukazují využití fyzické paměti včetně paměti RAM i odkládacího prostoru.
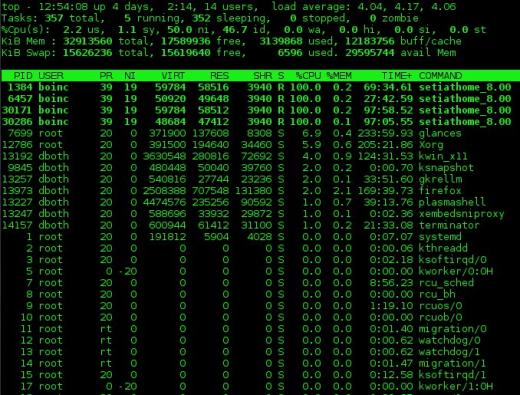
Obrázek 1: Horní příkaz zobrazující plně využitý čtyřjádrový procesor.
Příkaz 1 můžete použít k zobrazení statistik CPU jako jediné globální číslo, jak je znázorněno na obrázku 1 výše, nebo podle jednotlivých CPU. Příkaz l zapíná a vypíná průměry zátěže. Příkazy t a m otáčejí řádky procesu / CPU a paměti souhrnné sekce, v pořadí, vypnuto, pouze text a několik typů formátů sloupcového grafu.
Procesní část
Sekce procesu výstupu shora je seznam běžících procesů v systému – alespoň pro počet procesů, pro které je na displeji terminálu místo. Výchozí sloupce zobrazené nahoře jsou popsány níže. K dispozici je několik dalších sloupců a každý lze obvykle přidat jediným stiskem klávesy. Podrobnosti najdete na stránce top man.
- PID – ID procesu.
- USER – uživatelské jméno vlastníka procesu.
- PR – Priorita procesu.
- NI – pěkné číslo procesu.
- VIRT – celkové množství virtuální paměti přidělené procesu.
- RES – Rezidentní velikost (v kB, pokud není uvedeno jinak) nevyměněné fyzické paměti spotřebované procesem.
- SHR – množství sdílené paměti v kb použité procesem.
- S – Stav procesu. Může to být R pro běh, S pro spánek a Z pro zombie. Méně často viditelné stavy mohou být T pro vysledování nebo zastavení a D pro nepřerušitelný spánek.
- % CPU – Procento cyklů CPU nebo čas použitý tímto procesem během posledního měřeného časového období.
- % MEM – procento fyzické systémové paměti použité procesem.
- TIME + – celkový čas procesoru na 100 s sekundy spotřebovaný procesem od spuštění procesu.
- COMMAND – Toto je příkaz, který byl použit ke spuštění procesu.
Pomocí kláves Page Up a Page Down procházejte seznam spuštěných procesů. Příkazy d nebo s jsou zaměnitelné a lze je použít k nastavení intervalu zpoždění mezi aktualizacemi. Výchozí nastavení jsou tři sekundy, ale dávám přednost intervalu jedné sekundy. Granularita intervalu může být až jedna desetina (0,1) sekundy, ale to spotřebuje více cyklů CPU, které se pokoušíte měřit.
Můžete použít < a > klávesy pro řazení sloupce řazení doleva nebo doprava.
Příkaz k se používá k zabití procesu nebo příkaz r k renice to. Musíte znát ID procesu (PID) procesu, který chcete zabít nebo renice, a tyto informace se zobrazí v části procesu na horním displeji. Při zabíjení procesu se top nejprve zeptá na PID a poté na číslo signálu, které se použije při zabití procesu. Napište je a po každém stiskněte klávesu Enter. Začněte signálem 15, SIGTERM, a pokud to proces nezabije, použijte 9, SIGKILL.
Konfigurace
Pokud změníte horní displej, můžete použít W (v Příkaz pro psaní změn do konfiguračního souboru ~ / .toprc ve vašem domovském adresáři.
nahoře
Také se mi líbí nahoře. Je to vynikající monitor, který můžete použít, když potřebujete další podrobnosti o tomto typu I / O aktivity. Výchozí interval aktualizace je 10 sekund, ale lze jej změnit pomocí příkazu interval i na to, co je vhodné pro to, co se snažíte udělat. atop se nemůže obnovovat v sekundových intervalech jako horní.
K zobrazení nápovědy použijte příkaz h. Nezapomeňte si všimnout, že existuje několik stránek nápovědy a můžete použít mezerník k posouvání dolů, abyste viděli zbytek.
Jednou z příjemných funkcí atopu je, že může uložit surová data o výkonu do souboru a poté jej přehrajte později pro bližší kontrolu To je užitečné pro sledování občasných problémů, zejména těch, které se vyskytnou v době, kdy nemůžete přímo monitorovat systém. Program atopsar slouží k přehrávání dat v uloženém souboru.
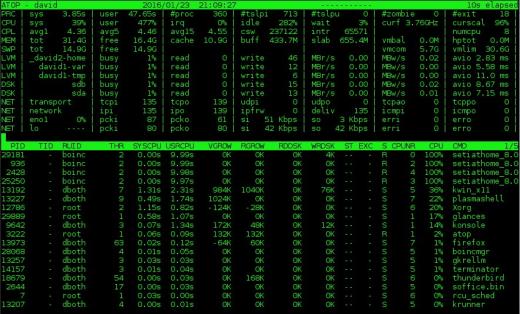 .
.
Obrázek 2: Monitor systému nahoře poskytuje informace o disku a kromě údajů o procesoru a procesech také síťová aktivita.
Souhrnná část
atop obsahuje mnoho stejných informací jako horní, ale také zobrazuje informace o činnosti sítě, nezpracovaného disku a logického svazku. Obrázek 2 výše ukazuje tato další data ve sloupcích v horní části displeje.Všimněte si, že pokud máte nemovitost na vodorovné obrazovce, která podporuje širší zobrazení, zobrazí se další sloupce. Naopak, pokud máte menší horizontální šířku, zobrazí se méně sloupců. Také se mi líbí, že na vrcholu zobrazuje aktuální frekvenci CPU a měřítko – něco, co jsem na žádném z těchto monitorů neviděl – na druhém řádku ve dvou sloupcích zcela vpravo na obrázku 2.
Procesní sekce
Displej nahoře procesu zahrnuje některé stejné sloupce jako sloupce nahoře, ale zahrnuje také informace o vstupech a výstupech disku a počet vláken pro každý proces a také statistiky růstu virtuální a skutečné paměti pro každý proces. Stejně jako v části se souhrnem se zobrazí další sloupce, pokud je k dispozici dostatek nemovitostí na vodorovné obrazovce. Například na obrázku 2 je zobrazen RUID (Real User ID) vlastníka procesu. Rozbalením displeje se také zobrazí EUID (Effective User ID), které může být důležité, když programy spouští SUID (Set User ID).
atop může také poskytovat podrobné informace o disku, paměti, síti a plánovacích informacích pro každý proces. Pro zobrazení těchto dat stačí stisknout klávesy d, m, n nebo s. Klávesa g vrátí zobrazení na zobrazení obecného procesu.
Třídění lze snadno provést pomocí C pro třídění podle využití CPU, M pro využití paměti, D pro využití disku, N pro použití v síti a A pro automatické třídění. Automatické třídění obvykle třídí procesy podle nejrušnějšího zdroje. Využití sítě lze třídit pouze v případě, že je nainstalován a načten modul jádra netatop.
Pomocí klávesy k můžete proces zabít, ale není možné proces renikovat.
Ve výchozím nastavení se nezobrazí síťová a disková zařízení, u nichž během daného časového intervalu nedochází k žádné aktivitě. To může vést k mylným předpokladům o hardwarové konfiguraci hostitele. Příkaz f lze použít k vynucení zobrazení nečinných zdrojů na vrcholu.
Konfigurace
Manuální stránka nahoře odkazuje na konfigurační soubory na globální a uživatelské úrovni, ale žádný z nich v mém vlastní instalace Fedory nebo CentOS. Neexistuje také žádný příkaz k uložení upravené konfigurace a uložení neproběhne automaticky po ukončení programu. Zdá se tedy, že nyní existuje způsob, jak provést změny konfigurace natrvalo.
htop
Program htop je hodně podobný topu, ale na steroidech. Vypadá hodně jako top, ale také poskytuje některé funkce, které top ne. Na rozdíl od vrcholu však neposkytuje žádné informace o disku, síti ani I / O jakéhokoli typu.
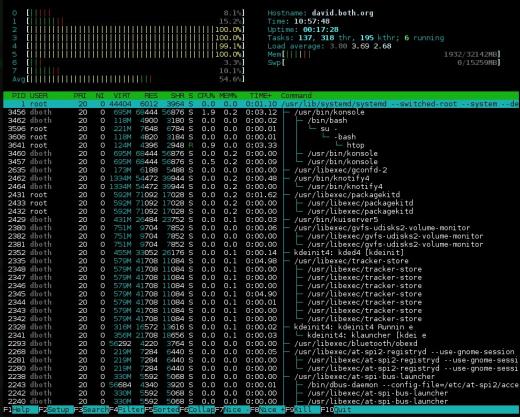
Obrázek 3: htop má pěkné pruhové grafy, které označují využití zdrojů, a může zobrazit strom procesu.
Souhrnná část
Souhrnná část htop je zobrazena ve dvou sloupcích. Je velmi flexibilní a lze jej konfigurovat s několika různými typy informací v téměř jakémkoli pořadí, které se vám líbí. Přestože sekce využití CPU nahoře a nahoře lze přepínat mezi kombinovaným displejem a displejem, který zobrazuje jeden sloupcový graf pro každý CPU, htop nikoli. Má tedy řadu různých možností zobrazení CPU, včetně jednoho kombinovaného pruhu, pruhu pro každý CPU a různých kombinací, ve kterých lze konkrétní CPU seskupit do jednoho pruhu.
Myslím, že toto je čistší souhrnné zobrazení než u některých ostatních monitorů systému a je snadněji čitelné. Nevýhodou této souhrnné části je, že některé informace nejsou k dispozici na htopu, který je k dispozici na ostatních monitorech, například procenta CPU podle uživatele, nečinnosti a systémového času.
Klávesa F2 (Setup) je slouží ke konfiguraci souhrnné sekce htop. Zobrazí se seznam dostupných datových zobrazení a pomocí funkčních kláves je můžete přidat do levého nebo pravého sloupce a přesunout je nahoru a dolů ve vybraném sloupci.
Sekce procesu
Procesní část htop je velmi podobná sekci top. Stejně jako u ostatních monitorů lze procesy řadit podle několika faktorů, včetně využití procesoru nebo paměti, uživatele nebo PID. Pamatujte, že třídění není možné, když je vybráno stromové zobrazení.
Klávesa F6 umožňuje vybrat sloupec řazení; zobrazí seznam sloupců dostupných k řazení, vyberete požadovaný sloupec a stisknete klávesu Enter.
Pomocí kláves se šipkami nahoru a dolů můžete vybrat proces. Chcete-li proces zabít, pomocí kláves se šipkami nahoru a dolů vyberte cílový proces a stiskněte klávesu k. Zobrazí se seznam signálů k odeslání procesu, přičemž je vybráno 15, SIGTERM. Můžete určit signál, který se má použít, pokud se liší od SIGTERM. Můžete také použít klávesy F7 a F8 k renice vybraného procesu.
Jeden příkaz, který se mi obzvláště líbí, je F5, který zobrazuje běžící procesy ve formátu stromu, což usnadňuje určení vztahů rodič / dítě běžícího procesy.
Konfigurace
Každý uživatel má svůj vlastní konfigurační soubor ~ / .config / htop / htoprc a změny konfigurace htop jsou tam ukládány automaticky.Pro htop neexistuje žádný globální konfigurační soubor.
pohledy
Nedávno jsem se dozvěděl o pohledech, které dokážou zobrazit více informací o vašem počítači než kterýkoli jiný monitor, který momentálně znám s. To zahrnuje diskové a síťové I / O, teplotní odečty, které mohou zobrazovat teploty CPU a dalšího hardwaru i rychlosti ventilátorů, a využití disku hardwarovým zařízením a logickým svazkem.
Nevýhodou všech těchto informací je to, že pohledy využívají značné množství CPU se samo obnoví. Na mých systémech jsem zjistil, že může používat přibližně 10% až 18% cyklů CPU. To je hodně, takže byste měli při výběru monitoru vzít v úvahu tento dopad.
Souhrnná část
Souhrnná část pohledů obsahuje většinu stejných informací jako souhrnné části druhé monitory. Pokud máte dostatek nemovitostí na vodorovné obrazovce, může zobrazit využití procesoru pomocí sloupcového grafu i číselného indikátoru, jinak zobrazí pouze číslo.
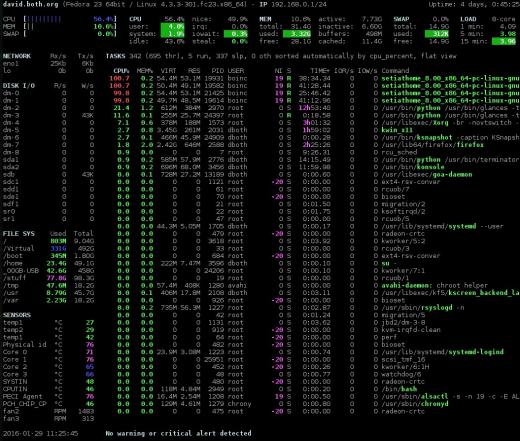
Obrázek 4: Rozhraní pohledů s informacemi o síti, disku, souborovém systému a senzorech.
Mám rád tuto souhrnnou část lépe než u ostatních monitorů; Myslím, že poskytuje správné informace ve snadno srozumitelném formátu. Stejně jako u atop a htop můžete stisknutím klávesy 1 přepínat mezi zobrazením jednotlivých jader CPU nebo globálním zobrazením se všemi jádry CPU jako jediný průměr, jak je znázorněno na obrázku 4 výše.
Sekce procesu
Sekce procesu zobrazuje standardní informace o každém spuštěném procesu. Procesy lze třídit automaticky a, nebo podle CPU c, paměti m, jména p, uživatele u, rychlosti I / O i nebo času t. Při automatickém třídění jsou procesy nejprve tříděny podle nejpoužívanějšího zdroje.
Pohledy také zobrazují varování a kritická upozornění v dolní části obrazovky, včetně času a doby trvání události. To může být užitečné při pokusu o diagnostiku problémů, kdy nemůžete zírat na obrazovku celé hodiny. Tyto výstražné protokoly lze zapínat a vypínat pomocí příkazu l, varování lze vymazat pomocí příkazu w, zatímco výstrahy a varování lze vymazat pomocí x.
Je zajímavé, že pohledy jsou jediné z tyto monitory, které nelze použít k ukončení nebo renice procesu. Je určen výhradně jako monitor. K manipulaci s procesy můžete použít externí příkazy kill a renice.
Postranní panel
Glances má velmi pěkný postranní panel, který zobrazuje informace, které nejsou k dispozici nahoře nebo nahoře. Atop některé z těchto dat zobrazuje, ale pohledy jsou jediným monitorem, který zobrazuje data ze senzorů. Někdy je příjemné sledovat teploty uvnitř počítače. Jednotlivé moduly, disk, souborový systém, síť a senzory lze zapínat a vypínat pomocí příkazů d, f, n a s. Celý postranní panel lze přepnout pomocí 2.
Statistiky Dockeru lze zobrazit pomocí D.
Konfigurace
Glances nevyžaduje pro správnou funkci konfigurační soubor. Pokud se rozhodnete mít jeden, instance celého systému konfiguračního souboru by byla umístěna v /etc/glances/glances.conf. Jednotliví uživatelé mohou mít místní instanci na ~ / .config / glances / glances.conf, která přepíše globální konfiguraci. Primárním účelem těchto konfiguračních souborů je nastavit prahové hodnoty pro varování a kritická upozornění. Nelze najít způsob, jak provést další změny konfigurace – například moduly postranního panelu nebo displeje CPU – trvalé. Zdá se, že tyto položky musíte překonfigurovat pokaždé, když se podíváte.
Existuje dokument /usr/share/doc/glances/glances-doc.html, který poskytuje velké množství informací o používání pohledy a výslovně uvádí, že pomocí konfiguračního souboru můžete nakonfigurovat, které moduly se zobrazí. Ani uvedené informace, ani příklady však nepopisují, jak to udělat.
Závěr
Nezapomeňte si přečíst manuálové stránky pro každý z těchto monitorů, protože existuje velké množství informace o konfiguraci a interakci s nimi. Klávesu h použijte také pro pomoc v interaktivním režimu. Tato nápověda vám může poskytnout informace o výběru a třídění sloupců dat, nastavení intervalu aktualizace a mnoho dalšího.
Tyto programy vám mohou hodně pomoci při hledání příčiny problému. Mohou vám říci, kdy proces a který z nich vysává čas procesoru, zda je dostatek volné paměti, zda jsou procesy pozastaveny během čekání na dokončení I / O, jako je přístup na disk nebo do sítě, a mnoho dalšího.
Důrazně doporučuji, abyste strávili čas sledováním těchto monitorovacích programů, zatímco běží na systému, který funguje normálně, takže budete moci rozlišovat ty věci, které mohou být neobvyklé, když hledáte příčinu problému.
Měli byste si také uvědomit, že používání těchto monitorovacích nástrojů mění systém, který využívá zdroje, včetně paměti a času CPU.horní část a většina z těchto monitorů využívá možná 2% nebo 3% času procesoru systému. Pohledy mají mnohem větší dopad než ostatní a mohou využít 10% až 20% času procesoru. Při výběru svého nástroje.
Původně jsem měl v úmyslu do tohoto článku zahrnout SAR (System Activity Reporter), ale jak se tento článek prodlužoval, bylo mi také jasné, že SAR se od těchto monitorovacích nástrojů výrazně liší a zaslouží si mít samostatný článek. Takže s ohledem na to plánuji napsat článek o SAR a souborovém systému / proc a třetí článek o tom, jak použít všechny tyto nástroje k vyhledání a řešení problémů.
