- Explique o que é pesquisa quase-experimental e diferencie-a claramente da pesquisa experimental e correlacional.
- Descreva três tipos diferentes de projetos de pesquisa quase-experimental (grupos não equivalentes, pré-teste-pós-teste e séries temporais interrompidas) e identifique exemplos de cada um.
O prefixo quase significa “semelhante”. Assim, a pesquisa quase experimental é uma pesquisa que se assemelha à pesquisa experimental, mas não é uma pesquisa experimental verdadeira. Embora a variável independente seja manipulada, os participantes não são atribuídos aleatoriamente a condições ou ordens de condições (Cook & Campbell, 1979). Como a variável independente é manipulada antes que a variável dependente seja medida, a pesquisa quase experimental elimina o problema de direcionalidade. Mas porque os participantes não são atribuídos aleatoriamente – tornando provável que haja outras diferenças entre as condições – pesquisa quase experimental não elimina o problema de variáveis de confusão. Em termos de validade interna, portanto, quase-experimentos estão geralmente em algum lugar entre estudos correlacionais e experimentos verdadeiros.
Quase-experimentos são mais prováveis de serem conduzidos em ambientes de campo em cuja atribuição aleatória é difícil ou impossível. Muitas vezes são realizados para avaliar a eficácia de um tratamento – pe talvez um tipo de psicoterapia ou uma intervenção educacional. Existem muitos tipos diferentes de quase-experimentos, mas discutiremos apenas alguns dos mais comuns aqui.
Lembre-se de que, quando os participantes de um experimento entre sujeitos são atribuídos aleatoriamente a condições, os grupos resultantes são provavelmente bastante semelhantes. Na verdade, os pesquisadores os consideram equivalentes. Quando os participantes não são atribuídos aleatoriamente às condições, no entanto, os grupos resultantes provavelmente serão diferentes em alguns aspectos. Por isso, os pesquisadores os consideram não equivalentes. Um projeto de grupos não equivalentes, então, é um projeto entre assuntos em que os participantes não foram atribuídos aleatoriamente às condições.
Imagine, por exemplo, um pesquisador que deseja avaliar um novo método de ensino de frações para terceiros niveladores. Uma maneira seria conduzir um estudo com um grupo de tratamento consistindo de uma classe de alunos da terceira série e um grupo de controle consistindo de outra classe de alunos da terceira série. Esse desenho seria um desenho de grupos não equivalente, porque os alunos não são alocados aleatoriamente nas aulas pelo pesquisador, o que significa que pode haver diferenças importantes entre eles. Por exemplo, os pais de alunos com melhor desempenho ou mais motivados podem ter sido mais propensos a solicitar que seus filhos fossem matriculados na classe da Sra. Williams. Ou o diretor pode ter designado os “criadores de problemas” para a classe do Sr. Jones porque ele é um disciplinador mais forte. Claro, os estilos dos professores, e até mesmo o ambiente da sala de aula, podem ser muito diferentes e podem causar diferentes níveis de desempenho ou motivação entre os alunos. Se no final do estudo houvesse uma diferença no conhecimento das frações das duas classes, isso poderia ter sido causado pela diferença entre os métodos de ensino – mas poderia ter sido causado por qualquer uma dessas variáveis de confusão.
Obviamente, os pesquisadores que usam um desenho de grupos não equivalentes podem tomar medidas para garantir que seus grupos sejam tão semelhantes quanto possível. No presente exemplo, o pesquisador poderia tentar selecionar duas turmas na mesma escola, onde os alunos nas duas turmas têm pontuações semelhantes em um teste de matemática padronizado e os professores são do mesmo sexo, têm idade próxima e estilos de ensino semelhantes. Seguir essas etapas aumentaria a validade interna do estudo porque eliminaria algumas das variáveis de confusão mais importantes. Mas sem uma verdadeira atribuição aleatória dos alunos às condições, permanece a possibilidade de outras variáveis importantes de confusão que o pesquisador não foi capaz de controlar.
Design pré-teste-pós-teste
Em um pré-teste -posttest design, a variável dependente é medida uma vez antes de o tratamento ser implementado e uma vez depois de implementado. Imagine, por exemplo, um pesquisador que está interessado na eficácia de um programa de educação antidrogas nas atitudes de alunos do ensino fundamental em relação às drogas ilegais. O pesquisador poderia medir as atitudes dos alunos de uma determinada escola de ensino fundamental durante uma semana, implementar o programa antidrogas na semana seguinte e, por fim, medir suas atitudes novamente na semana seguinte. O desenho pré-pós-teste é muito parecido com um experimento dentro dos sujeitos, no qual cada participante é testado primeiro sob a condição de controle e, em seguida, sob a condição de tratamento.É diferente de um experimento dentro dos sujeitos, no entanto, em que a ordem das condições não é contrabalançada porque normalmente não é possível para um participante ser testado na condição de tratamento primeiro e depois em uma condição de controle “não tratada”.
Se a pontuação média do pós-teste for melhor do que a média do pré-teste, faz sentido concluir que o tratamento pode ser responsável pela melhora. Infelizmente, muitas vezes não é possível concluir isso com um alto grau de certeza, porque pode haver outras explicações para o motivo pelo qual as pontuações do pós-teste são melhores. Uma categoria de explicações alternativas é conhecida como história. Outras coisas podem ter acontecido entre o pré-teste e o pós-teste. Talvez um programa antidrogas transmitido na televisão e muitos dos alunos o assistiram, ou talvez uma celebridade morreu de overdose de drogas e muitos dos alunos ouviram falar sobre isso. Outra categoria de explicações alternativas é chamada de maturação. Os participantes podem mudaram entre o pré-teste e o pós-teste de uma forma que eles iriam de qualquer maneira porque estão crescendo e aprendendo. Se fosse um programa de um ano, os participantes poderiam se tornar menos impulsivos ou melhores raciocinadores e isso poderia ser responsável pela mudança.
Outra explicação alternativa para uma mudança na variável dependente em um projeto pré-pós-teste é a regressão para O significativo. Isso se refere ao fato estatístico de que um indivíduo que pontua extremamente em uma variável em uma ocasião tenderá a pontuar menos extremamente na próxima ocasião. Por exemplo, um arremessador com uma média de longo prazo de 150 que de repente arremessa um 220 quase certamente terá uma pontuação mais baixa no próximo jogo. Sua pontuação “regredirá” em direção à pontuação média de 150. A regressão à média pode ser um problema quando os participantes são selecionados para estudos posteriores por causa de suas pontuações extremas. Imagine, por exemplo, que apenas os alunos que pontuaram especialmente baixo em um teste de as frações recebem um programa de treinamento especial e, em seguida, são testadas novamente. A regressão à média garante que suas pontuações serão mais altas, mesmo que o programa de treinamento não tenha efeito. Um conceito intimamente relacionado – e extremamente importante na pesquisa psicológica – é a remissão espontânea . Esta é a tendência de muitos problemas médicos e psicológicos melhorarem com o tempo, sem qualquer forma de tratamento. O resfriado comum é um bom exemplo. Se alguém medisse a gravidade dos sintomas em 100 pessoas que sofrem de resfriado hoje, dê a eles uma tigela de canja de galinha todos os dias, e depois medir a gravidade dos sintomas novamente em uma semana, eles provavelmente melhorariam muito. Isso não significa que a canja de galinha foi responsável pela melhora, entretanto ver, porque eles teriam melhorado muito sem qualquer tratamento. O mesmo se aplica a muitos problemas psicológicos. Hoje, um grupo de pessoas gravemente deprimidas provavelmente ficará menos deprimido, em média, em 6 meses. Ao revisar os resultados de vários estudos de tratamentos para depressão, os pesquisadores Michael Posternak e Ivan Miller descobriram que os participantes em condições de controle de lista de espera melhoraram em média 10 a 15% antes de receberem qualquer tratamento (Posternak & Miller, 2001). Portanto, deve-se geralmente ser muito cauteloso ao inferir causalidade de designs pré-teste-pós-teste.
Os primeiros estudos sobre a eficácia da psicoterapia costumavam usar designs pré-teste-pós-teste. Em um artigo clássico de 1952, o pesquisador Hans Eysenck resumiu os resultados de 24 desses estudos, mostrando que cerca de dois terços dos pacientes melhoraram entre o pré-teste e o pós-teste (Eysenck, 1952). Mas Eysenck também comparou esses resultados com dados de arquivo de hospitais estaduais e seguros registros da empresa mostram que pacientes semelhantes se recuperaram aproximadamente na mesma taxa sem receber psicoterapia. Esse paralelo sugeriu a Eysenck que a melhora que os pacientes mostraram nos estudos pré-pós-teste pode ser não mais do que remissão espontânea. Observe que Eysenck não concluiu que a psicoterapia era ineficaz. Ele meramente concluiu que não havia nenhuma evidência de que sim, e escreveu sobre “a necessidade de estudos experimentais adequadamente planejados e executados neste importante campo” (p. 323). Você pode ler o artigo completo aqui: Clássicos na História da Psicologia.
Felizmente, muitos outros pesquisadores aceitaram o desafio de Eysenck e, em 1980, centenas de experimentos foram conduzidos nos quais os participantes foram designados aleatoriamente para tratamento e condições de controle, e o os resultados foram resumidos em um livro clássico de Mary Lee Smith, Gene Glass e Thomas Miller (Smith, Glass, & Miller, 1980). Eles descobriram que a psicoterapia geral foi bastante eficaz, com cerca de 80% dos participantes do tratamento melhoram mais do que a média dos participantes do controle. A pesquisa subsequente se concentrou mais nas condições em que diferentes tipos de psicoterapia são mais ou menos eficazes.
Projeto de série temporal interrompida
Uma variante do projeto pré-teste-pós-teste é o projeto de série temporal interrompida. Uma série temporal é um conjunto de medições feitas em intervalos durante um período de tempo. Por exemplo, uma empresa de manufatura pode medir a produtividade de seus trabalhadores a cada semana durante um ano. Em um projeto de série temporal interrompida, uma série temporal como esta é “interrompida” por um tratamento. Em um exemplo clássico, o tratamento era a redução dos turnos de trabalho em uma fábrica de 10 horas para 8 horas (Cook & Campbell, 1979). Como a produtividade aumentou muito rapidamente após o encurtamento dos turnos de trabalho, e por ter permanecido elevada por muitos meses depois, o pesquisador concluiu que o encurtamento dos turnos causou o aumento de produtividade. Observe que o design de série de tempo interrompido é como um design de pré-teste pós-teste, pois inclui medições da variável dependente antes e depois do tratamento. No entanto, é diferente do design de pré-teste e pós-teste por incluir vários pré-testes e medições pós-teste.
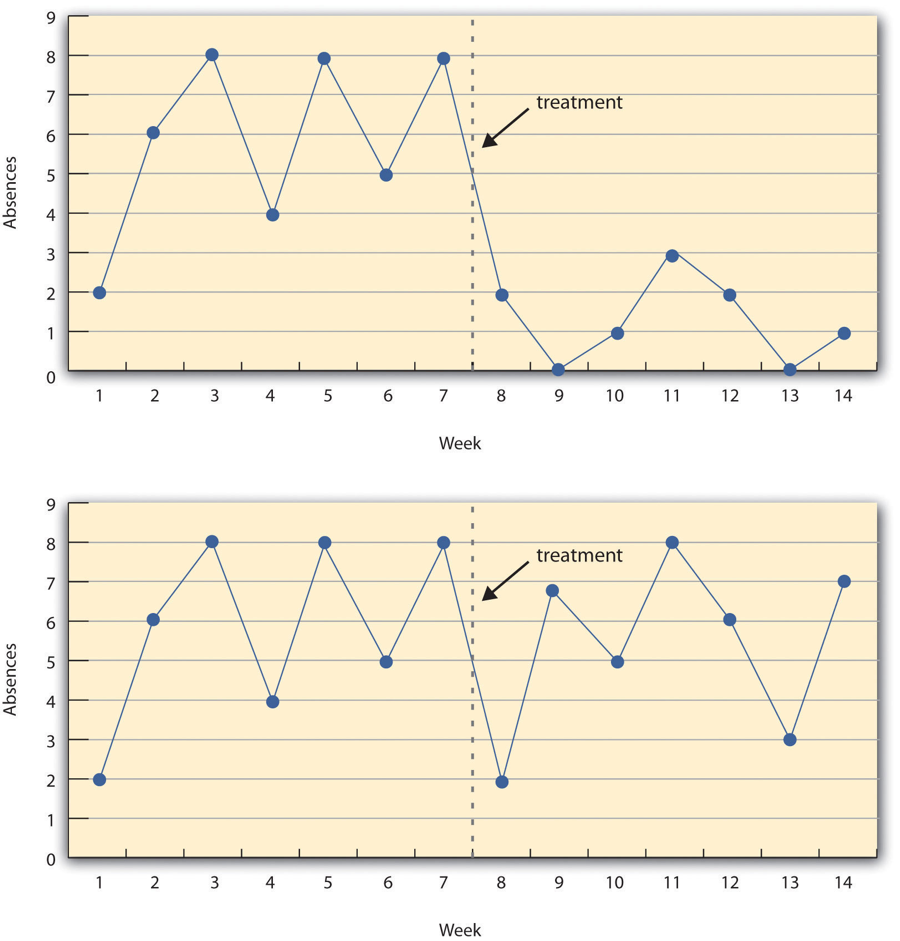
A Figura 7.3 mostra os dados de um estudo hipotético de série temporal interrompida. A variável dependente é o número de faltas do aluno por semana em um curso de métodos de pesquisa. O tratamento é que o O instrutor começa a tomar publicamente a frequência todos os dias para que os alunos saibam que o instrutor está ciente de quem está presente e quem está ausente. O painel superior da Figura 7.3 mostra como os dados ficariam se esse tratamento funcionasse. Há um número consistentemente alto de ausências antes do tratamento e há uma queda imediata e sustentada nas ausências após o tratamento. O painel inferior da Figura 7.3 mostra como os dados ficariam se esse tratamento não funcionasse. Em média, o número de faltas após o tratamento é quase igual ao anterior. Esta figura também ilustra uma vantagem do design de série de tempo interrompido sobre um design de pré-teste e pós-teste mais simples. Se houvesse apenas uma medição de ausências antes do tratamento na semana 7 e uma depois na semana 8, então teria parecido que o tratamento foi o responsável pela redução. As múltiplas medições antes e depois do tratamento sugerem que a redução entre as semanas 7 e 8 nada mais é do que uma variação normal de uma semana.
Projetos de combinação
Um tipo de projeto quase experimental que geralmente é melhor do que o projeto de grupos não equivalentes ou o pré-teste-pós-teste o design é aquele que combina elementos de ambos. Há um grupo de tratamento que faz um pré-teste, recebe um tratamento e, em seguida, faz um pós-teste. Mas, ao mesmo tempo, há um grupo de controle que faz um pré-teste, não recebe o tratamento e, em seguida, faz um pós-teste. A questão, então, não é simplesmente se os participantes que recebem o tratamento melhoram, mas se eles melhoram mais do que os participantes que não recebem o tratamento.
Imagine, por exemplo, que os alunos de uma escola recebem um pré-teste sobre suas atitudes em relação às drogas, então são expostos a um programa antidrogas e, finalmente, recebem um pós-teste. Os alunos de uma escola semelhante recebem o pré-teste, não são expostos a um programa antidrogas e, finalmente, recebem um pós-teste. Novamente, se os alunos na condição de tratamento se tornarem mais negativos em relação aos medicamentos, essa mudança de atitude pode ser um efeito do tratamento, mas também pode ser uma questão de história ou maturação. Se for realmente um efeito do tratamento, os alunos na condição de tratamento devem se tornar mais negativos do que os alunos na condição de controle. Mas se for uma questão de história (por exemplo, notícias de overdose de uma celebridade) ou maturação (por exemplo, raciocínio aprimorado), então os alunos nas duas condições provavelmente apresentarão quantidades semelhantes de mudança. Esse tipo de projeto não elimina completamente a possibilidade de variáveis confusas. Algo poderia ocorrer em uma das escolas, mas não na outra (por exemplo, uma overdose de drogas em um aluno), então os alunos da primeira escola seriam afetados por isso, enquanto os alunos da outra escola não.
Finalmente, se os participantes desse tipo de projeto são atribuídos aleatoriamente a condições, torna-se um verdadeiro experimento, em vez de um quase experimento. Na verdade, é o tipo de experimento que Eysenck solicitou – e que já foi realizado muitas vezes – para demonstrar a eficácia da psicoterapia.
- Pesquisa quase experimental envolve a manipulação de uma variável independente sem a atribuição aleatória de participantes a condições ou ordens de condições.Entre os tipos importantes estão projetos de grupos não equivalentes, pré-teste-pós-teste e projetos de séries temporais interrompidas.
- A pesquisa quase experimental elimina o problema de direcionalidade porque envolve a manipulação da variável independente. Não elimina o problema de confundir variáveis, entretanto, porque não envolve atribuição aleatória a condições. Por essas razões, a pesquisa quase experimental é geralmente superior em validade interna do que estudos correlacionais, mas inferior a experimentos verdadeiros.
- Prática: Imagine que dois professores decidam testar o efeito da aplicação de questionários diários sobre o desempenho dos alunos em um curso de estatística. Eles decidem que o professor A dará questionários, mas o professor B não. Eles irão então comparar o desempenho dos alunos em suas duas seções em um exame final comum. Liste cinco outras variáveis que podem diferir entre as duas seções que podem afetar os resultados.
- Discussão: Imagine que um grupo de crianças obesas é recrutado para um estudo em que seu peso é medido, então eles participam de 3 meses em um programa que os incentiva a ser mais ativos e, finalmente, seu peso é medido novamente. Explique como cada um dos seguintes pode afetar os resultados:
- regressão à média
- remissão espontânea
- história
- maturação
Descrições da imagem
Figura 7.3 descrição da imagem: dois gráficos de linha que representam o número de faltas por semana durante 14 semanas . As primeiras 7 semanas são sem tratamento e as últimas 7 semanas são com tratamento. No primeiro gráfico de linha, ocorrem entre 4 a 8 faltas por semana. Após o tratamento, as faltas caem para 0 a 3 por semana, o que sugere que o tratamento funcionou. No gráfico de segunda linha, não há mudança perceptível no número de faltas por semana após o tratamento, o que sugere que o tratamento não funcionou.
Um design entre assuntos em que os participantes não foram atribuídos aleatoriamente às condições.
A variável dependente é medida uma vez antes o tratamento é implementado e depois de implementado.
Uma categoria de explicações alternativas para diferenças entre pontuações, como eventos que aconteceram entre o pré-teste e o pós-teste, não relacionados ao estudo.
Uma explicação alternativa que se refere a como os participantes podem ter mudado entre o pré-teste e o pós-teste de uma forma que eles iriam fazer de qualquer maneira porque estão crescendo e aprendendo.
O fato estatístico de que um indivíduo que pontua extremamente em uma variável em uma ocasião tende a pontuar menos extremamente na próxima ocasião.
A tendência de muitos problemas médicos e psicológicos melhorarem ao longo do tempo sem qualquer forma de tratamento.
Um conjunto de medições feitas em intervalos durante um período de tempo que são interrompidos por um tratamento.
