A informação é a chave para resolver qualquer problema do computador, incluindo problemas com ou relacionados ao Linux e o hardware no qual ele é executado. Existem muitas ferramentas disponíveis e incluídas na maioria das distribuições, embora nem todas sejam instaladas por padrão. Essas ferramentas podem ser usadas para obter grandes quantidades de informações.
Este artigo discute algumas das ferramentas de interface de linha de comando interativa (CLI) que são fornecidas ou que podem ser facilmente instaladas em distribuições relacionadas ao Red Hat, incluindo Red Hat Enterprise Linux, Fedora, CentOS e outras distribuições derivadas. Embora existam ferramentas GUI disponíveis e elas ofereçam boas informações, as ferramentas CLI fornecem todas as mesmas informações e são sempre utilizáveis porque muitos servidores não têm uma interface GUI, mas todos os sistemas Linux têm uma interface de linha de comando.
Este artigo concentra-se nas ferramentas que normalmente uso. Se eu não falei sobre sua ferramenta favorita, por favor, me perdoe e diga a todos nós quais ferramentas você usa e por quê na seção de comentários.
Minha visita às ferramentas para determinação de problemas em um ambiente Linux são quase sempre as ferramentas de monitoramento do sistema. Para mim, eles são top, atop, htop e glances.
Todas essas ferramentas monitoram o uso da CPU e da memória, e a maioria delas lista pelo menos informações sobre os processos em execução. Alguns monitoram outros aspectos de um sistema Linux também. Todos fornecem visualizações quase em tempo real da atividade do sistema.
Médias de carga
Antes de continuar a discutir as ferramentas de monitoramento, é importante discutir as médias de carga em mais detalhes.
As médias de carga são um critério importante para medir o uso da CPU, mas o que isso realmente significa quando digo que a média de carga de 1 (ou 5 ou 10) minutos é 4,04, por exemplo? A média de carga pode ser considerada uma medida de demanda para a CPU; é um número que representa o número médio de instruções aguardando o tempo de CPU. Portanto, esta é uma medida verdadeira de desempenho da CPU, ao contrário da “porcentagem da CPU” padrão, que inclui tempos de espera de E / S durante os quais a CPU não está realmente funcionando.
Por exemplo, uma CPU de sistema de processador único totalmente utilizada teria uma carga média de 1. Isso significa que a CPU está acompanhando exatamente a demanda; em outras palavras, tem uma utilização perfeita. Uma média de carga menor que um significa que a CPU está subutilizada e uma média de carga maior que 1 significa que a CPU está superutilizada e que há demanda reprimida e não satisfeita. Por exemplo, uma média de carga de 1,5 em um único sistema de CPU indica que um terço das instruções da CPU são forçadas a esperar para serem executadas até que a anterior seja concluída.
Isso também é verdadeiro para várias processadores. Se um sistema de 4 CPUs tem uma média de carga de 4, ele tem uma utilização perfeita. Se ele tem uma carga média de 3,24, por exemplo, então três de seus processadores estão totalmente utilizados e um é utilizado em cerca de 76%. No exemplo acima, um sistema de 4 CPUs tem uma média de carga de 1 minuto de 4,04, o que significa que não há capacidade restante entre os 4 CPUs e algumas instruções são forçadas a esperar. Um sistema de 4 CPUs perfeitamente utilizado apresentaria uma média de carga de 4,00, de modo que o sistema no exemplo está totalmente carregado, mas não sobrecarregado.
A condição ideal para a média de carga é igual ao número total de CPUs em um sistema. Isso significaria que cada CPU está totalmente utilizada e ainda assim nenhuma instrução deve ser forçada a esperar. As médias de carga de longo prazo fornecem uma indicação da tendência geral de utilização.
O Linux Journal tem um excelente artigo que descreve as médias de carga, a teoria e a matemática por trás delas e como interpretá-las em 1 de dezembro de 2006 problema.
Sinais
Todos os monitores discutidos aqui permitem que você envie sinais para processos em execução. Cada um desses sinais tem uma função específica, embora alguns deles possam ser definidos pelo programa receptor usando manipuladores de sinais.
O comando kill separado também pode ser usado para enviar sinais para processos fora dos monitores. O kill -l pode ser usado para listar todos os sinais possíveis que podem ser enviados. Três desses sinais podem ser usados para matar um processo.
- SIGTERM (15): Sinal 15, SIGTERM é o sinal padrão enviado por top e os outros monitores quando a tecla k é pressionada. Também pode ser o menos eficaz porque o programa deve ter um manipulador de sinal integrado. O manipulador de sinais do programa deve interceptar os sinais de entrada e agir de acordo. Portanto, para scripts, a maioria dos quais não têm manipuladores de sinal, o SIGTERM é ignorado. A ideia por trás do SIGTERM é simplesmente dizer ao programa que você deseja que ele seja encerrado, ele vai tirar vantagem disso e limpar coisas como arquivos abertos e então se encerrar de uma maneira controlada e agradável.
- SIGKILL (9): Sinal 9, SIGKILL fornece um meio de matar até mesmo os programas mais recalcitrantes , incluindo scripts e outros programas que não possuem manipuladores de sinal.Para scripts e outros programas sem manipulador de sinal, no entanto, não apenas mata o script em execução, mas também mata a sessão do shell na qual o script está sendo executado; este pode não ser o comportamento que você deseja. Se você deseja encerrar um processo e não se importa em ser gentil, este é o sinal que você deseja. Este sinal não pode ser interceptado por um manipulador de sinais no código do programa.
- SIGINT (2): O sinal 2, SIGINT pode ser usado quando o SIGTERM não funciona e você deseja que o programa morra um pouco mais bem, por exemplo, sem matar a sessão shell em que está sendo executado. SIGINT envia uma interrupção para a sessão em que o programa está em execução. Isso é equivalente a encerrar um programa em execução, particularmente um script, com a combinação de teclas Ctrl-C.
Para experimentar isso, abra uma sessão de terminal e crie um arquivo em / tmp chamado cpuHog e torná-lo executável com as permissões rwxr_xr_x. Adicione o seguinte conteúdo ao arquivo.
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
Abra outra sessão de terminal em uma janela diferente, posicione-os adjacentes entre si para que você possa ver os resultados e executar o top na nova sessão. Execute o programa cpuHog com o seguinte comando:
Este programa simplesmente conta um e imprime o valor atual de X em STDOUT. E suga os ciclos da CPU. A sessão de terminal na qual o cpuHog está sendo executado deve mostrar um alto uso de CPU no topo. Observe o efeito que isso tem no desempenho do sistema no topo. O uso da CPU deve aumentar imediatamente e as médias de carga também devem começar a aumentar com o tempo. Se desejar, você pode abrir sessões de terminal adicionais e iniciar o programa cpuHog nelas para que tenha várias instâncias em execução.
Determine o PID do programa cpuHog que deseja encerrar. Pressione a tecla k e veja a mensagem sob a linha Trocar na parte inferior da seção de resumo. Top pede o PID do processo que você deseja matar. Insira aquele PID e pressione Enter. Agora o top pede o número do sinal e exibe o padrão de 15. Experimente cada um dos sinais descritos aqui e observe os resultados.
4 ferramentas de código aberto para monitoramento de sistema Linux
Um dos as primeiras ferramentas que utilizo ao realizar a determinação de problemas são as principais. Gosto dele porque existe desde sempre e está sempre disponível enquanto as outras ferramentas podem não estar instaladas.
O programa top é um utilitário muito poderoso que fornece uma grande quantidade de informações sobre o seu sistema em execução. Isso inclui dados sobre o uso de memória, cargas de CPU e uma lista de processos em execução, incluindo a quantidade de tempo de CPU e memória sendo utilizada por cada processo. Top exibe informações do sistema quase em tempo real, atualizando (por padrão) a cada três segundos. Os segundos fracionários são permitidos por top, embora valores muito pequenos possam colocar uma carga significativa no sistema. Ele também é interativo e as colunas de dados a serem exibidas e a coluna de classificação podem ser modificadas.
Um exemplo de saída do programa principal é mostrado na Figura 1 abaixo. A saída do topo é dividida em duas seções que são chamadas de seção “resumo”, que é a seção superior da saída, e a seção “processo” que é a parte inferior da saída; Usarei esta terminologia para top, atop, htop e glances no interesse da consistência.
O programa top tem uma série de comandos interativos úteis que você pode usar para gerenciar a exibição de dados e manipular processos individuais . Use o comando h para visualizar uma breve página de ajuda para os vários comandos interativos. Certifique-se de pressionar h duas vezes para ver as duas páginas da ajuda. Use o comando q para sair.
Seção de resumo
A seção de resumo da saída superior é uma visão geral do status do sistema. A primeira linha mostra o tempo de atividade do sistema e as médias de carga de 1, 5 e 15 minutos. No exemplo abaixo, as médias de carga são 4,04, 4,17 e 4,06 respectivamente.
A segunda linha mostra o número de processos atualmente ativos e o status de cada um.
As linhas que contêm As estatísticas da CPU são mostradas a seguir. Pode haver uma única linha que combina as estatísticas para todas as CPUs presentes no sistema, como no exemplo abaixo, ou uma linha para cada CPU; no caso do computador usado para o exemplo, este é um único CPU quad core. Pressione a tecla 1 para alternar entre a exibição consolidada do uso da CPU e a exibição das CPUs individuais. Os dados nessas linhas são exibidos como porcentagens do tempo total de CPU disponível.
Esses e os outros campos para dados de CPU são descritos abaixo.
- us: userspace – Applications e outros programas em execução no espaço do usuário, ou seja, não no kernel.
- sy: chamadas de sistema – funções de nível de kernel. Isso não inclui o tempo de CPU gasto pelo próprio kernel, apenas as chamadas do sistema do kernel.
- ni: nice – Processos que estão rodando em um nível positivo positivo.
- id: idle – Tempo ocioso, ou seja, tempo não utilizado por nenhum processo em execução.
- wa: wait – Ciclos de CPU que são gastos esperando a ocorrência de E / S. Isso é tempo de CPU desperdiçado.
- hi: interrupções de hardware – ciclos de CPU que são gastos lidando com interrupções de hardware.
- si: interrupções de software – ciclos de CPU gastos lidando com interrupções criadas por software, tais como chamadas de sistema.
- st: steal time – A porcentagem de ciclos de CPU que uma CPU virtual espera por uma CPU real enquanto o hipervisor está atendendo a outro processador virtual.
As duas últimas linhas na seção de resumo são o uso de memória. Eles mostram o uso da memória física, incluindo RAM e espaço de troca.
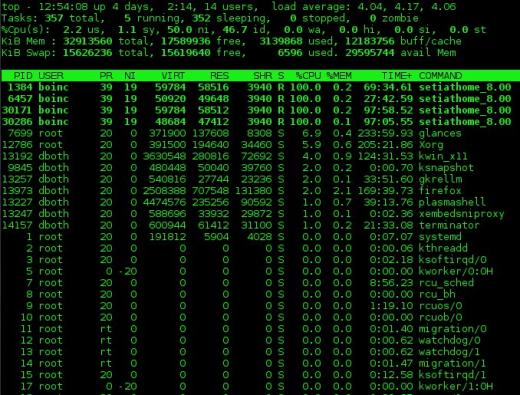
Figura 1: O comando superior mostra uma CPU de 4 núcleos totalmente utilizada.
Você pode usar o comando 1 para exibir as estatísticas da CPU como um único número global, conforme mostrado na Figura 1, acima, ou por CPU individual. O comando l ativa e desativa as médias de carga. Os comandos t e m giram as linhas de processo / CPU e memória da seção de resumo, respectivamente, por meio de off, somente texto e alguns tipos de formatos de gráfico de barras.
Seção de processo
A seção de processo da saída de cima é uma lista dos processos em execução no sistema – pelo menos para o número de processos para os quais há espaço na tela do terminal. As colunas padrão exibidas pela parte superior são descritas abaixo. Várias outras colunas estão disponíveis e cada uma geralmente pode ser adicionada com um único toque de tecla. Consulte a página principal do manual para detalhes.
- PID – O ID do processo.
- USUÁRIO – O nome de usuário do proprietário do processo.
- PR – A prioridade do processo.
- NI – O bom número do processo.
- VIRT – A quantidade total de memória virtual alocada para o processo.
- RES – Tamanho residente (em kb, salvo indicação em contrário) da memória física não trocada consumida por um processo.
- SHR – A quantidade de memória compartilhada em kb usada pelo processo.
- S – O status do processo. Pode ser R para correr, S para dormir e Z para zumbi. Os status vistos com menos frequência podem ser T para rastreado ou interrompido e D para hibernação ininterrupta.
- % CPU – A porcentagem de ciclos de CPU ou tempo usado por este processo durante o último período de tempo medido.
- % MEM – A porcentagem de memória física do sistema usada pelo processo.
- TIME + – Tempo total de CPU até centésimos de segundo consumido pelo processo desde que ele foi iniciado.
- COMANDO – Este é o comando que foi usado para iniciar o processo.
Use as teclas Page Up e Page Down para percorrer a lista de processos em execução. Os comandos d ou s são intercambiáveis e podem ser usados para definir o intervalo de atraso entre as atualizações. O padrão é três segundos, mas prefiro um intervalo de um segundo. A granularidade do intervalo pode ser tão baixa quanto um décimo (0,1) de segundo, mas isso consumirá mais dos ciclos da CPU que você está tentando medir.
Você pode usar o < e > as chaves para sequenciar a coluna de classificação para a esquerda ou direita.
O comando k é usado para matar um processo ou o comando r para renice. Você deve saber o ID do processo (PID) do processo que deseja eliminar ou renice e essa informação é exibida na seção de processo da tela superior. Ao encerrar um processo, o top pergunta primeiro pelo PID e depois pelo número do sinal a ser usado para encerrar o processo. Digite-os e pressione a tecla Enter após cada um. Comece com o sinal 15, SIGTERM, e se isso não interromper o processo, use 9, SIGKILL.
Configuração
Se você alterar a exibição superior, pode usar o W (em maiúsculas) para gravar as mudanças no arquivo de configuração, ~ / .toprc em seu diretório pessoal.
em cima
Eu também gosto de em cima. É um excelente monitor para usar quando você precisar de mais detalhes sobre esse tipo de atividade de E / S. O intervalo de atualização padrão é de 10 segundos, mas isso pode ser alterado usando o comando interval i para o que for apropriado para o que você está tentando fazer. no topo não pode ser atualizado em intervalos de menos de um segundo como o topo pode.
Use o comando h para exibir a ajuda. Certifique-se de observar que existem várias páginas de ajuda e você pode usar a barra de espaço para rolar para baixo e ver o resto.
Um bom recurso do atop é que ele pode salvar dados brutos de desempenho em um arquivo e em seguida, reproduza mais tarde para uma inspeção detalhada. Isso é útil para rastrear problemas internmittent, especialmente aqueles que ocorrem durante momentos em que você não pode monitorar diretamente o sistema. O programa atopsar é usado para reproduzir os dados no arquivo salvo.
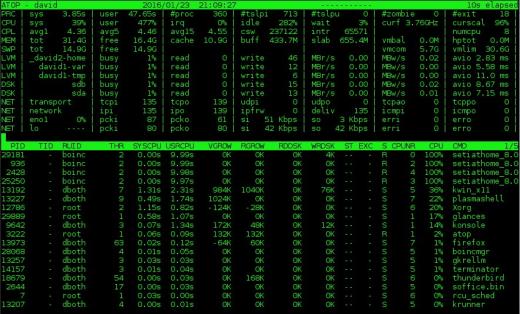 .
.
Figura 2: O monitor do sistema atop fornece informações sobre o disco e atividade de rede além de CPU e dados de processo.
Seção de resumo
em cima contém muitas das mesmas informações que em cima, mas também exibe informações sobre rede, disco bruto e atividade de volume lógico. A Figura 2, acima, mostra esses dados adicionais nas colunas na parte superior da tela.Observe que se você tiver o estado real da tela horizontal para oferecer suporte a uma exibição mais ampla, colunas adicionais serão exibidas. Por outro lado, se você tiver menos largura horizontal, menos colunas serão exibidas. Também gosto de exibir a frequência atual da CPU e o fator de escala – algo que não vi em nenhum outro desses monitores – na segunda linha nas duas colunas mais à direita na Figura 2.
Seção do processo
A exibição do processo no topo inclui algumas das mesmas colunas que a do topo, mas também inclui informações de E / S de disco e contagem de threads para cada processo, bem como estatísticas de crescimento de memória virtual e real para cada processo. Assim como na seção de resumo, colunas adicionais serão exibidas se houver espaço suficiente na tela horizontal. Por exemplo, na Figura 2, o RUID (Real User ID) do proprietário do processo é exibido. Expandir a exibição também mostrará o EUID (ID de usuário efetivo), que pode ser importante quando os programas executam SUID (Definir ID de usuário).
no topo também pode fornecer informações detalhadas sobre disco, memória, rede e informações de programação para cada processo. Basta pressionar as teclas d, m, n ou s respectivamente para visualizar os dados. A tecla g retorna a exibição para a exibição do processo genérico.
A classificação pode ser realizada facilmente usando C para classificar por uso de CPU, M para uso de memória, D para uso de disco, N para uso de rede e A para classificação automática. A classificação automática geralmente classifica os processos pelo recurso mais ocupado. O uso da rede só pode ser classificado se o módulo do kernel netatop estiver instalado e carregado.
Você pode usar a tecla k para encerrar um processo, mas não há opção para reniciar um processo.
Por padrão, os dispositivos de rede e disco para os quais nenhuma atividade ocorre durante um determinado intervalo de tempo não são exibidos. Isso pode levar a suposições equivocadas sobre a configuração de hardware do host. O comando f pode ser usado para forçar o atop a exibir os recursos ociosos.
Configuração
A página do manual atop refere-se a arquivos de configuração globais e de nível de usuário, mas nenhum pode ser encontrado em meu próprias instalações do Fedora ou CentOS. Também não há comando para salvar uma configuração modificada e um salvamento não ocorre automaticamente quando o programa é encerrado. Portanto, agora parece haver uma maneira de tornar as alterações de configuração permanentes.
htop
O programa htop é muito parecido com o top, mas com esteróides. Ele se parece muito com o top, mas também oferece alguns recursos que o top não tem. Diferentemente do topo, no entanto, ele não fornece nenhum disco, rede ou informações de E / S de qualquer tipo.
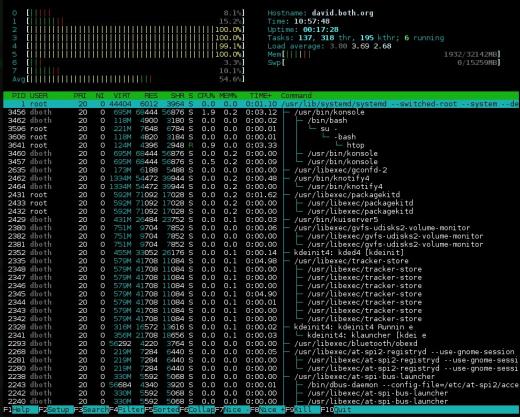
Figura 3: htop tem bons gráficos de barras para indicar o uso de recursos e pode mostrar a árvore do processo.
Seção de resumo
A seção de resumo do htop é exibida em duas colunas. É muito flexível e pode ser configurado com vários tipos diferentes de informações em praticamente qualquer ordem que você desejar. Embora as seções de uso da CPU do topo e do topo possam ser alternadas entre uma exibição combinada e uma exibição que mostra um gráfico de barras para cada CPU, o htop não pode. Portanto, ele tem várias opções diferentes para a exibição da CPU, incluindo uma única barra combinada, uma barra para cada CPU e várias combinações nas quais CPUs específicas podem ser agrupadas em uma única barra.
Eu acho esta é uma exibição de resumo mais limpa do que alguns dos outros monitores do sistema e é mais fácil de ler. A desvantagem desta seção de resumo é que algumas informações não estão disponíveis no htop que está disponível em outros monitores, como porcentagens de CPU por usuário, ocioso e tempo do sistema.
A tecla F2 (configuração) é usado para configurar a seção de resumo do htop. Uma lista de exibições de dados disponíveis é mostrada e você pode usar as teclas de função para adicioná-los à coluna esquerda ou direita e movê-los para cima e para baixo na coluna selecionada.
Seção do processo
A seção de processo do htop é muito semelhante à do top. Como com os outros monitores, os processos podem ser classificados por qualquer um de vários fatores, incluindo CPU ou uso de memória, usuário ou PID. Observe que a classificação não é possível quando a exibição em árvore é selecionada.
A tecla F6 permite que você selecione a coluna de classificação; ele exibe uma lista das colunas disponíveis para classificação e você seleciona a coluna desejada e pressiona a tecla Enter.
Você pode usar as teclas de seta para cima e para baixo para selecionar um processo. Para encerrar um processo, use as teclas de seta para cima e para baixo para selecionar o processo de destino e pressione a tecla k. Uma lista de sinais para enviar o processo é exibida com 15, SIGTERM, selecionado. Você pode especificar o sinal a ser usado, se for diferente de SIGTERM. Você também pode usar as teclas F7 e F8 para reniciar o processo selecionado.
Um comando de que gosto especialmente é o F5, que exibe os processos em execução em um formato de árvore, tornando fácil determinar as relações pai / filho da execução processos.
Configuração
Cada usuário tem seu próprio arquivo de configuração, ~ / .config / htop / htoprc e as alterações na configuração do htop são armazenadas lá automaticamente.Não existe um arquivo de configuração global para htop.
relances
Recentemente, aprendi sobre relances, que podem exibir mais informações sobre o seu computador do que qualquer um dos outros monitores que conheço atualmente com. Isso inclui E / S de disco e rede, leituras térmicas que podem exibir CPU e outras temperaturas de hardware, bem como velocidades de ventilador, e uso de disco por dispositivo de hardware e volume lógico.
A desvantagem de ter todas essas informações é que o relances usa uma quantidade significativa de recursos da CPU. Em meus sistemas, acho que ele pode usar cerca de 10% a 18% dos ciclos da CPU. Isso é muito, então você deve considerar esse impacto ao escolher seu monitor.
Seção de resumo
A seção de resumo de olhares contém a maioria das mesmas informações que as seções de resumo das outras monitores. Se você tiver espaço suficiente na tela horizontal, ele pode mostrar o uso da CPU com um gráfico de barras e um indicador numérico, caso contrário, ele mostrará apenas o número.
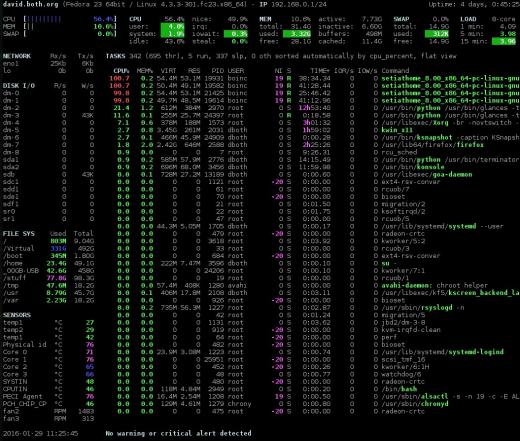
Figura 4: A interface de relance com informações de rede, disco, sistema de arquivos e sensor.
Gosto mais desta seção de resumo do que dos outros monitores; Acho que fornece as informações corretas em um formato de fácil compreensão. Tal como acontece com atop e htop, você pode pressionar a tecla 1 para alternar entre uma exibição de núcleos de CPU individuais ou global com todos os núcleos de CPU como uma média única, conforme mostrado na Figura 4, acima.
Seção do processo
A seção do processo exibe as informações padrão sobre cada um dos processos em execução. Os processos podem ser classificados automaticamente a ou por CPU c, memória m, nome p, usuário u, taxa de E / S i ou tempo t. Quando classificados automaticamente, os processos são classificados primeiro pelo recurso mais usado.
O Glances também mostra avisos e alertas críticos na parte inferior da tela, incluindo a hora e a duração do evento. Isso pode ser útil ao tentar diagnosticar problemas quando você não consegue olhar para a tela por horas seguidas. Esses logs de alerta podem ser ativados ou desativados com o comando l, os avisos podem ser limpos com o comando w enquanto os alertas e avisos podem ser todos limpos com x.
É interessante que os olhares sejam os únicos esses monitores que não podem ser usados para matar ou reniciar um processo. É estritamente um monitor. Você pode usar os comandos kill e renice externos para manipular processos.
Barra lateral
O Glances tem uma barra lateral muito boa que exibe informações que não estão disponíveis no top ou htop. O Atop exibe alguns desses dados, mas o glances é o único monitor que exibe os dados dos sensores. Às vezes é bom ver as temperaturas dentro do seu computador. Os módulos individuais, disco, sistema de arquivos, rede e sensores podem ser ativados e desativados usando os comandos d, f, n e s, respectivamente. A barra lateral inteira pode ser alternada usando 2.
As estatísticas do Docker podem ser exibidas com D.
Configuração
O olhar rápido não requer um arquivo de configuração para funcionar corretamente. Se você optar por ter um, a instância do arquivo de configuração de todo o sistema estará localizada em /etc/glances/glances.conf. Usuários individuais podem ter uma instância local em ~ / .config / glances / glances.conf que sobrescreverá a configuração global. O objetivo principal desses arquivos de configuração é definir limites para avisos e alertas críticos. Não consigo encontrar nenhuma maneira de fazer outras alterações de configuração – como módulos da barra lateral ou monitores da CPU – permanentes. Parece que você deve reconfigurar esses itens toda vez que iniciar os olhares.
Existe um documento, /usr/share/doc/glances/glances-doc.html, que fornece muitas informações sobre o uso olha, e afirma explicitamente que você pode usar o arquivo de configuração para configurar quais módulos são exibidos. No entanto, nem as informações fornecidas nem os exemplos descrevem exatamente como fazer isso.
Conclusão
Certifique-se de ler as páginas de manual de cada um desses monitores, pois há uma grande quantidade de informações sobre como configurar e interagir com eles. Use também a tecla h para obter ajuda no modo interativo. Esta ajuda pode fornecer informações sobre como selecionar e classificar as colunas de dados, definir o intervalo de atualização e muito mais.
Esses programas podem dizer muito quando você está procurando a causa de um problema. Eles podem dizer quando um processo, e qual deles, está consumindo tempo de CPU, se há memória livre suficiente, se os processos estão paralisados enquanto aguardam a conclusão de E / S, como disco ou acesso à rede, e muito mais.
Eu recomendo fortemente que você gaste algum tempo assistindo a esses programas de monitoramento enquanto eles são executados em um sistema que está funcionando normalmente, para que você possa diferenciar aquelas coisas que podem ser anormais enquanto você procura a causa de um problema.
Você também deve estar ciente de que o uso dessas ferramentas de monitoramento altera o uso de recursos do sistema, incluindo memória e tempo de CPU.A parte superior e a maioria desses monitores usam talvez 2% ou 3% do tempo de CPU de um sistema. Os olhares têm muito mais impacto do que os outros e podem usar entre 10% e 20% do tempo de CPU. Considere isso ao escolher seu ferramentas.
Eu tinha a intenção original de incluir SAR (System Activity Reporter) neste artigo, mas à medida que este artigo foi crescendo, também ficou claro para mim que o SAR é significativamente diferente dessas ferramentas de monitoramento e merece ter um artigo separado. Com isso em mente, pretendo escrever um artigo sobre SAR e o sistema de arquivos / proc, e um terceiro artigo sobre como usar todas essas ferramentas para localizar e resolver problemas.
