Informacje są kluczem do rozwiązania każdego problemu z komputerem, w tym problemów z Linuksem i sprzętem, na którym działa. Istnieje wiele narzędzi dostępnych i dołączonych do większości dystrybucji, mimo że nie wszystkie są instalowane domyślnie. Narzędzia te mogą być używane do uzyskiwania ogromnych ilości informacji.
W tym artykule omówiono niektóre narzędzia interaktywnego interfejsu wiersza poleceń (CLI), które są dostarczane z dystrybucjami związanymi z Red Hat lub które można łatwo zainstalować w dystrybucjach związanych z Red Hatem, w tym Red Hat Enterprise Linux, Fedora, CentOS i inne dystrybucje pochodne. Chociaż dostępne są narzędzia GUI, które zapewniają dobre informacje, narzędzia CLI zapewniają wszystkie te same informacje i są zawsze użyteczne, ponieważ wiele serwerów nie ma interfejsu GUI, ale wszystkie systemy Linux mają interfejs wiersza poleceń.
Ten artykuł koncentruje się na narzędziach, których zwykle używam. Jeśli nie opisałem twojego ulubionego narzędzia, wybacz mi i daj nam wszystkim znać, jakich narzędzi używasz i dlaczego w sekcji komentarzy.
Moje przejście do narzędzi do rozwiązywania problemów w środowisku Linux jest prawie zawsze narzędzia do monitorowania systemu. Dla mnie są to top, top, htop i spojrzenia.
Wszystkie te narzędzia monitorują użycie procesora i pamięci, a większość z nich zawiera przynajmniej informacje o uruchomionych procesach. Niektórzy monitorują również inne aspekty systemu Linux. Wszystkie zapewniają widoki aktywności systemu niemal w czasie rzeczywistym.
Średnie obciążenia
Zanim przejdę do omówienia narzędzi do monitorowania, ważne jest, aby bardziej szczegółowo omówić średnie obciążenia.
Średnie obciążenia są ważnymi kryteriami pomiaru wykorzystania procesora, ale co to naprawdę oznacza, gdy powiem, że średnie obciążenie 1 (lub 5 lub 10) minut wynosi na przykład 4,04? Średnie obciążenie można uznać za miarę zapotrzebowania na procesor; jest to liczba reprezentująca średnią liczbę instrukcji oczekujących na czas procesora. Jest to więc prawdziwa miara wydajności procesora, w przeciwieństwie do standardowego „procentu użycia procesora”, który obejmuje czasy oczekiwania na operacje we / wy, podczas których procesor tak naprawdę nie działa.
Na przykład w pełni wykorzystany jednoprocesorowy procesor systemowy miałby średnie obciążenie równe 1. Oznacza to, że procesor nadąża dokładnie za zapotrzebowaniem; innymi słowy, ma doskonałe wykorzystanie. Średnie obciążenie mniejsze niż jeden oznacza, że procesor jest niewykorzystany, a średnie obciążenie większe niż 1 oznacza, że procesor jest nadmiernie wykorzystywany i istnieje stłumiony, niezaspokojony popyt. Na przykład średnie obciążenie wynoszące 1,5 w systemie z pojedynczym procesorem oznacza, że jedna trzecia instrukcji procesora jest zmuszona czekać na wykonanie, aż poprzednia została zakończona.
Dotyczy to również wielu procesory. Jeśli system z 4 procesorami ma średnie obciążenie 4, to ma doskonałe wykorzystanie. Jeśli, na przykład, średnie obciążenie wynosi 3,24, to trzy z jego procesorów są w pełni wykorzystane, a jeden w około 76%. W powyższym przykładzie system z 4 procesorami ma 1 minutę obciążenia średnio 4,04, co oznacza, że nie ma pozostałej pojemności między 4 procesorami i kilka instrukcji jest zmuszonych czekać. Doskonale wykorzystany system z 4 procesorami wskazywałby średnie obciążenie równe 4,00, więc system w przykładzie jest w pełni załadowany, ale nie jest przeciążony.
Optymalnym warunkiem dla średniego obciążenia jest równe całkowitej liczbie procesorów w systemie. Oznaczałoby to, że każdy procesor jest w pełni wykorzystany, a jednak żadne instrukcje nie muszą być zmuszane do czekania. Długoterminowe średnie obciążenia wskazują na ogólny trend wykorzystania.
Linux Journal zawiera doskonały artykuł opisujący średnie obciążenia, teorię i matematykę stojącą za nimi oraz jak je interpretować w publikacji z 1 grudnia 2006 roku. problem.
Sygnały
Wszystkie omówione tutaj monitory umożliwiają wysyłanie sygnałów do uruchomionych procesów. Każdy z tych sygnałów ma określoną funkcję, chociaż niektóre z nich mogą być zdefiniowane przez program odbierający przy użyciu programów obsługi sygnałów.
Oddzielne polecenie kill może być również użyte do wysłania sygnałów do procesów poza monitorami. Polecenia kill -l można użyć do wyświetlenia wszystkich możliwych sygnałów, które mogą zostać wysłane. Trzy z tych sygnałów mogą być użyte do zabicia procesu.
- SIGTERM (15): Sygnał 15, SIGTERM jest domyślnym sygnałem wysyłanym z góry, a pozostałe monitory po naciśnięciu klawisza k. Może być również najmniej efektywny, ponieważ program musi mieć wbudowaną obsługę sygnału. Program obsługi sygnału musi przechwytywać przychodzące sygnały i działać zgodnie z nimi. Tak więc w przypadku skryptów, z których większość nie ma funkcji obsługi sygnału, SIGTERM jest ignorowany. Ideą SIGTERM jest to, że po prostu mówiąc programowi, że chcesz, aby sam się zakończył, skorzysta z tego i wyczyści takie rzeczy, jak otwarte pliki, a następnie zakończy się w kontrolowany i przyjemny sposób.
- SIGKILL (9): Sygnał 9, SIGKILL zapewnia środki do zabijania nawet najbardziej opornych programów , w tym skrypty i inne programy, które nie mają programów obsługi sygnałów.Jednak w przypadku skryptów i innych programów bez obsługi sygnału nie tylko zabija działający skrypt, ale także zabija sesję powłoki, w której skrypt jest uruchomiony; to może nie być pożądane zachowanie. Jeśli chcesz zabić proces i nie zależy ci na byciu miłym, to jest sygnał, którego potrzebujesz. Sygnał ten nie może zostać przechwycony przez moduł obsługi sygnału w kodzie programu.
- SIGINT (2): Sygnał 2, SIGINT może być używany, gdy SIGTERM nie działa i chcesz, aby program umarł trochę ładniej, na przykład bez przerywania sesji powłoki, w której jest uruchomiony. SIGINT wysyła przerwanie do sesji, w której program jest Jest to równoznaczne z zakończeniem uruchomionego programu, szczególnie skryptu, za pomocą kombinacji klawiszy Ctrl-C.
Aby poeksperymentować, otwórz sesję terminala i utwórz plik w / tmp o nazwie cpuHog i uczyń go wykonywalnym z uprawnieniami rwxr_xr_x. Dodaj następującą zawartość do pliku.
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
Otwórz kolejną sesję terminala w innym oknie i umieść je obok siebie do siebie, abyś mógł oglądać wyniki i działać jako pierwszy w nowej sesji. Uruchom program cpuHog za pomocą następującego polecenia:
Ten program po prostu zlicza w górę o jeden i wypisuje bieżącą wartość X na STDOUT. I wysysa cykle procesora. Sesja terminala, w której działa cpuHog, powinna pokazywać bardzo wysokie użycie procesora na górze. Obserwuj wpływ tego na wydajność systemu na górze. Zużycie procesora powinno natychmiast wzrosnąć, a średnie obciążenie również powinno zacząć rosnąć w czasie. Jeśli chcesz, możesz otworzyć dodatkowe sesje terminala i uruchomić w nich program cpuHog, aby mieć uruchomionych wiele instancji.
Określ PID programu cpuHog, który chcesz zabić. Naciśnij klawisz k i spójrz na wiadomość pod linią Zamień u dołu sekcji podsumowania. Top pyta o PID procesu, który chcesz zabić. Wprowadź ten PID i naciśnij Enter. Teraz top pyta o numer sygnału i wyświetla domyślny 15. Wypróbuj każdy z opisanych tutaj sygnałów i obserwuj wyniki.
4 narzędzia open source do monitorowania systemu Linux
Jeden z pierwsze narzędzia, których używam podczas określania problemów, są najlepsze. Podoba mi się, ponieważ istnieje od zawsze i jest zawsze dostępny, podczas gdy inne narzędzia mogą nie być zainstalowane.
Najlepszy program to bardzo potężne narzędzie, które dostarcza wielu informacji o działającym systemie. Obejmuje to dane dotyczące użycia pamięci, obciążenia procesora i listę uruchomionych procesów, w tym ilość czasu procesora i pamięci używanej przez każdy proces. Top wyświetla informacje systemowe w czasie zbliżonym do rzeczywistego, aktualizując (domyślnie) co trzy sekundy. Górna część dopuszcza ułamkowe części sekund, chociaż bardzo małe wartości mogą spowodować znaczne obciążenie systemu. Jest również interaktywny, a kolumny danych, które mają być wyświetlane, oraz kolumna sortowania mogą być modyfikowane.
Przykładowe dane wyjściowe programu nadrzędnego pokazano na rysunku 1 poniżej. Dane wyjściowe od góry są podzielone na dwie sekcje, zwane sekcją „podsumowanie”, która jest górną sekcją wyniku, oraz sekcją „proces”, która jest dolną częścią wyniku; Będę używał tej terminologii do top, atop, htop i spojrzeń w celu zachowania spójności.
Najwyższy program ma wiele przydatnych interaktywnych poleceń, których możesz użyć do zarządzania wyświetlaniem danych i manipulowania indywidualnymi procesami . Użyj polecenia h, aby wyświetlić krótką stronę pomocy dla różnych poleceń interaktywnych. Pamiętaj, aby dwukrotnie nacisnąć przycisk h, aby wyświetlić obie strony pomocy. Użyj polecenia q, aby zakończyć.
Sekcja podsumowania
Sekcja podsumowania danych wyjściowych od góry to przegląd stanu systemu. Pierwsza linia pokazuje czas pracy systemu oraz średnie obciążenia z 1, 5 i 15 minut. W poniższym przykładzie średnie obciążenie wynosi odpowiednio 4,04, 4,17 i 4,06.
Druga linia pokazuje liczbę aktualnie aktywnych procesów i stan każdego z nich.
Wiersze zawierające Statystyki procesora są wyświetlane obok. Może istnieć jeden wiersz, który łączy statystyki dla wszystkich procesorów obecnych w systemie, jak w poniższym przykładzie, lub jeden wiersz dla każdego procesora; w przypadku komputera użytego w przykładzie jest to pojedynczy czterordzeniowy procesor. Naciśnij klawisz 1, aby przełączać się między skonsolidowanym wyświetlaniem użycia procesora a wyświetlaniem poszczególnych procesorów. Dane w tych wierszach są wyświetlane jako wartości procentowe całkowitego dostępnego czasu procesora.
Te i inne pola danych procesora opisano poniżej.
- us: userspace – Applications i inne programy działające w przestrzeni użytkownika, tj. nie w jądrze.
- sy: wywołania systemowe – funkcje na poziomie jądra. Nie obejmuje to czasu procesora zajmowanego przez samo jądro, tylko wywołania systemowe jądra.
- ni: nice – Procesy, które działają na dodatnim niezłym poziomie.
- id: idle – Czas bezczynności, tj. Czas niewykorzystany przez żaden działający proces.
- wa: wait – cykle procesora spędzone na oczekiwaniu na wystąpienie operacji we / wy. To zmarnowany czas procesora.
- hi: przerwań sprzętowych – cykle procesora, które są poświęcane na obsługę przerwań sprzętowych.
- si: przerwania programowe – cykle procesora spędzone na obsłudze przerwań programowych, takich jak jako wywołania systemowe.
- st: steal time – procent cykli procesora, podczas których wirtualny procesor oczekuje na rzeczywisty procesor, podczas gdy hiperwizor obsługuje inny procesor wirtualny.
Ostatnie dwa wiersze w sekcji podsumowania to użycie pamięci. Pokazują fizyczne wykorzystanie pamięci, w tym pamięć RAM i przestrzeń wymiany.
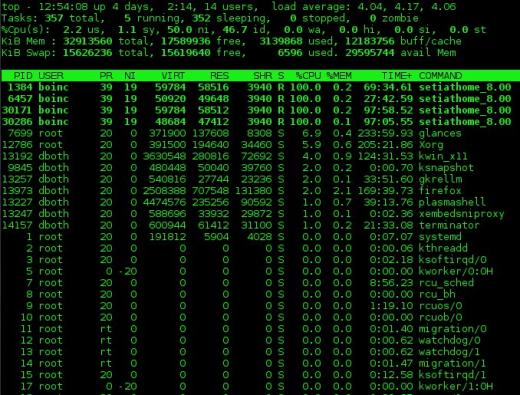
Rysunek 1: Górne polecenie pokazujące w pełni wykorzystany 4-rdzeniowy procesor.
Możesz użyć polecenia 1, aby wyświetlić statystyki procesora jako pojedynczą, globalną liczbę, jak pokazano na rysunku 1 powyżej, lub dla poszczególnych procesorów. Polecenie l włącza i wyłącza średnie obciążenia. Polecenia t i m obracają linie procesu / procesora i pamięci w sekcji podsumowania, odpowiednio, poprzez wyłączenie, tylko tekst i kilka typów formatów wykresów słupkowych.
Sekcja procesu
Sekcja procesu na wyjściu od góry to lista procesów uruchomionych w systemie – przynajmniej dla liczby procesów, dla których jest miejsce na wyświetlaczu terminala. Domyślne kolumny wyświetlane u góry są opisane poniżej. Dostępnych jest kilka innych kolumn, z których każdą można zwykle dodać jednym naciśnięciem klawisza. Szczegółowe informacje można znaleźć na górnej stronie podręcznika.
- PID – identyfikator procesu.
- USER – nazwa użytkownika właściciela procesu.
- PR – Priorytet procesu.
- NI – Niezła liczba procesu.
- VIRT – Całkowita ilość pamięci wirtualnej przydzielonej procesowi.
- RES – Rozmiar rezydentny (w kb, chyba że zaznaczono inaczej) niewymienionej pamięci fizycznej zajmowanej przez proces.
- SHR – Ilość pamięci współdzielonej w kb używanej przez proces.
- S – stan procesu. Może to być R do biegania, S do spania i Z do zombie. Rzadziej obserwowane stany mogą być T dla śledzenia lub zatrzymania i D dla nieprzerywanego uśpienia.
- % CPU – Procent cykli procesora lub czas wykorzystany przez ten proces w ostatnim mierzonym okresie.
- % MEM – procent fizycznej pamięci systemowej używanej przez proces.
- CZAS + – całkowity czas procesora do setnych części sekundy zużyty przez proces od momentu rozpoczęcia.
- COMMAND – To jest polecenie, które zostało użyte do uruchomienia procesu.
Użyj klawiszy Page Up i Page Down, aby przewijać listę uruchomionych procesów. Polecenia d lub s są wymienne i mogą być używane do ustawiania odstępu czasu między aktualizacjami. Wartość domyślna to trzy sekundy, ale ja wolę interwał jednosekundowy. Ziarnistość interwałów może wynosić zaledwie jedną dziesiątą (0,1) sekundy, ale spowoduje to większe zużycie cykli procesora, które próbujesz zmierzyć.
Możesz użyć funkcji < i > do sekwencjonowania kolumny sortowania w lewo lub w prawo.
Polecenie k służy do zabicia procesu lub polecenie r do popraw to. Musisz znać identyfikator procesu (PID) procesu, który chcesz zabić lub zmienić, a informacje te są wyświetlane w sekcji procesu na górnym wyświetlaczu. Podczas zabijania procesu top pyta najpierw o PID, a następnie o numer sygnału, który ma być użyty do zabicia procesu. Wpisz je i po każdym naciśnij klawisz Enter. Zacznij od sygnału 15, SIGTERM, a jeśli to nie zabije procesu, użyj 9, SIGKILL.
Konfiguracja
Jeśli zmienisz górny wyświetlacz, możesz użyć W (w wielkie litery), aby zapisać zmiany w pliku konfiguracyjnym ~ / .toprc w twoim katalogu domowym.
na górze
Lubię też na szczycie. Jest to doskonały monitor do wykorzystania, gdy potrzebujesz więcej szczegółów na temat tego typu aktywności we / wy. Domyślny interwał odświeżania to 10 sekund, ale można go zmienić za pomocą polecenia interwał i na dowolny odpowiedni do tego, co próbujesz zrobić. atop nie może odświeżać się w odstępach poniżej sekundy, jak top can.
Użyj polecenia h, aby wyświetlić pomoc. Pamiętaj, aby zauważyć, że istnieje wiele stron pomocy i możesz użyć spacji, aby przewinąć w dół, aby zobaczyć resztę.
Jedną z fajnych cech na szczycie jest to, że może zapisać nieprzetworzone dane o wydajności do pliku i następnie odtwórz go później, aby dokładnie obejrzeć. Jest to przydatne do śledzenia przejściowych problemów, szczególnie tych, które pojawiają się w czasach, gdy nie można bezpośrednio monitorować systemu. Program atopsar jest używany do odtwarzania danych w zapisanym pliku.
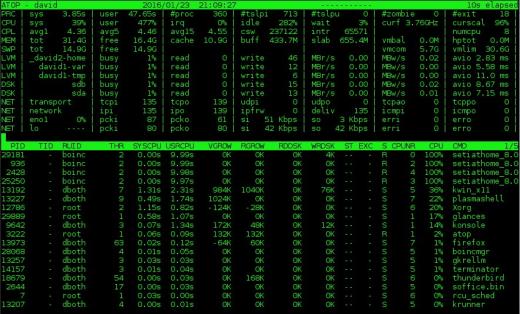 .
.
Rysunek 2: Monitor systemu na górze dostarcza informacji o dysku i aktywność sieci oprócz danych procesora i procesów.
Sekcja Podsumowanie
na górze zawiera wiele takich samych informacji, jak top, ale wyświetla również informacje o aktywności sieci, dysku surowego i woluminu logicznego. Rysunek 2 powyżej przedstawia te dodatkowe dane w kolumnach u góry wyświetlacza.Zwróć uwagę, że jeśli masz poziomą powierzchnię ekranu do obsługi szerszego wyświetlacza, zostaną wyświetlone dodatkowe kolumny. I odwrotnie, jeśli masz mniejszą szerokość w poziomie, wyświetlanych jest mniej kolumn. Podoba mi się również to, że na górze wyświetla aktualną częstotliwość procesora i współczynnik skalowania – coś, czego nie widziałem na żadnym innym z tych monitorów – w drugiej linii w dwóch skrajnych kolumnach po prawej stronie na rysunku 2.
Sekcja procesu
Ekran procesu na szczycie zawiera niektóre z tych samych kolumn, co w przypadku góry, ale zawiera również informacje o dyskowych operacjach we / wy i liczbę wątków dla każdego procesu, a także statystyki wzrostu pamięci wirtualnej i rzeczywistej dla każdego procesu. Podobnie jak w przypadku sekcji podsumowania, dodatkowe kolumny zostaną wyświetlone, jeśli jest wystarczająca ilość miejsca na ekranie w poziomie. Na przykład na rysunku 2 wyświetlany jest RUID (rzeczywisty identyfikator użytkownika) właściciela procesu. Rozwinięcie ekranu pokaże również EUID (efektywny identyfikator użytkownika), który może być ważny, gdy programy działają z SUID (ustaw identyfikatorem użytkownika).
na górze może również zawierać szczegółowe informacje o dysku, pamięci, sieci i harmonogramie dla każdego procesu. Wystarczy nacisnąć odpowiednio klawisze d, m, n lub s, aby wyświetlić te dane. Klawisz g przywraca wyświetlanie do ogólnego ekranu procesu.
Sortowanie można łatwo przeprowadzić, używając C do sortowania według użycia procesora, M do użycia pamięci, D do użycia dysku, N do użycia w sieci i A do automatyczne sortowanie. Automatyczne sortowanie zwykle sortuje procesy według najbardziej obciążonego zasobu. Wykorzystanie sieci można sortować tylko wtedy, gdy moduł jądra netatop jest zainstalowany i załadowany.
Możesz użyć klawisza k, aby zabić proces, ale nie ma opcji zmiany konfiguracji procesu.
Domyślnie urządzenia sieciowe i dyskowe, w przypadku których nie występuje żadna aktywność w danym przedziale czasu, nie są wyświetlane. Może to prowadzić do błędnych założeń dotyczących konfiguracji sprzętowej hosta. Polecenie f może być użyte do wymuszenia na szczycie wyświetlenia bezczynnych zasobów.
Konfiguracja
Strona podręcznika na szczycie odnosi się do plików konfiguracyjnych na poziomie globalnym i użytkownika, ale żadnego nie można znaleźć w moim własne instalacje Fedory lub CentOS. Nie ma również polecenia zapisywania zmodyfikowanej konfiguracji, a zapis nie jest wykonywany automatycznie po zakończeniu działania programu. Wygląda więc na to, że istnieje sposób na trwałe wprowadzenie zmian w konfiguracji.
htop
Program htop jest podobny do programu top, ale na sterydach. Wygląda bardzo podobnie do góry, ale zapewnia również pewne możliwości, których nie ma top. Jednak w przeciwieństwie do atop nie dostarcza żadnych informacji o dysku, sieci ani we / wy dowolnego typu.
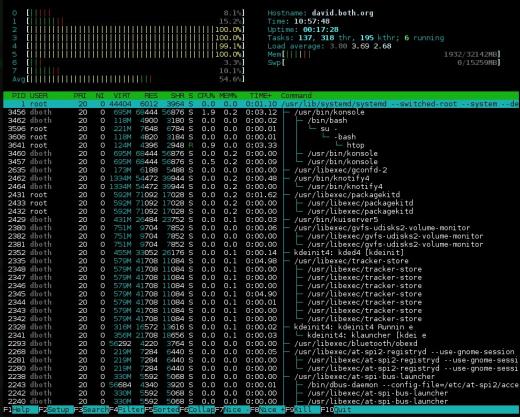
Rysunek 3: htop ma ładne wykresy słupkowe pokazujące użycie zasobów i może pokazywać drzewo procesów.
Sekcja podsumowania
Sekcja podsumowania htop jest wyświetlana w dwóch kolumnach. Jest bardzo elastyczny i można go skonfigurować z kilkoma różnymi typami informacji w praktycznie dowolnej kolejności. Chociaż sekcje użycia procesora na górze i na górze można przełączać między połączonym wyświetlaczem i wyświetlaczem, który pokazuje jeden wykres słupkowy dla każdego procesora, htop nie może. Ma więc wiele różnych opcji wyświetlania procesora, w tym pojedynczy połączony pasek, pasek dla każdego procesora i różne kombinacje, w których określone procesory mogą być zgrupowane w jednym pasku.
Myślę, że jest to bardziej przejrzyste podsumowanie niż niektóre inne monitory systemowe i jest łatwiejsze do odczytania. Wadą tej sekcji podsumowania jest to, że niektóre informacje nie są dostępne w htop, które są dostępne na innych monitorach, takie jak procenty procesora według użytkownika, bezczynności i czasu systemowego.
Klawisz F2 (Konfiguracja) jest służy do konfigurowania sekcji podsumowania htop. Wyświetlana jest lista dostępnych ekranów danych i możesz użyć klawiszy funkcyjnych, aby dodać je do lewej lub prawej kolumny i przesuwać je w górę iw dół w wybranej kolumnie.
Sekcja procesu
Sekcja procesu w htop jest bardzo podobna do tej w topie. Podobnie jak w przypadku innych monitorów, procesy można sortować według dowolnego z kilku czynników, w tym użycia procesora lub pamięci, użytkownika lub PID. Zauważ, że sortowanie nie jest możliwe, gdy wybrany jest widok drzewa.
Klawisz F6 umożliwia wybranie kolumny sortowania; wyświetli listę kolumn dostępnych do sortowania, a następnie wybierz żądaną kolumnę i naciśnij klawisz Enter.
Możesz użyć klawiszy strzałek w górę iw dół, aby wybrać proces. Aby zabić proces, użyj klawiszy strzałek w górę iw dół, aby wybrać proces docelowy i naciśnij klawisz k. Lista sygnałów do wysłania procesu jest wyświetlana z zaznaczonym 15, SIGTERM. Możesz określić sygnał, który ma być używany, jeśli różni się od SIGTERM. Możesz również użyć klawiszy F7 i F8, aby zmienić ustawienia wybranego procesu.
Jednym z poleceń, które szczególnie lubię, jest F5, który wyświetla uruchomione procesy w formacie drzewa, co ułatwia określenie relacji rodzic / dziecko w uruchomionym
Konfiguracja
Każdy użytkownik ma swój własny plik konfiguracyjny ~ / .config / htop / htoprc i zmiany w konfiguracji htop są tam automatycznie zapisywane.Nie ma globalnego pliku konfiguracyjnego dla htop.
spojrzenia
Niedawno dowiedziałem się o spojrzeniach, które mogą wyświetlać więcej informacji o twoim komputerze niż jakikolwiek inny monitor, który obecnie znam z. Obejmuje to dysk i sieć we / wy, odczyty termiczne, które mogą wyświetlać temperaturę procesora i innego sprzętu, a także prędkości wentylatorów, a także wykorzystanie dysku przez urządzenie sprzętowe i wolumin logiczny.
Wadą posiadania wszystkich tych informacji polega na tym, że spojrzenia same zużywają znaczną ilość zasobów procesora. W moich systemach stwierdzam, że może zużywać od około 10% do 18% cykli procesora. To dużo, więc powinieneś wziąć pod uwagę ten wpływ przy wyborze monitora.
Sekcja podsumowania
Sekcja podsumowania spojrzeń zawiera większość tych samych informacji, co sekcje podsumowania innych monitory. Jeśli masz wystarczająco dużo miejsca na poziomym ekranie, może on pokazywać użycie procesora zarówno za pomocą wykresu słupkowego, jak i wskaźnika liczbowego, w przeciwnym razie pokaże tylko liczbę.
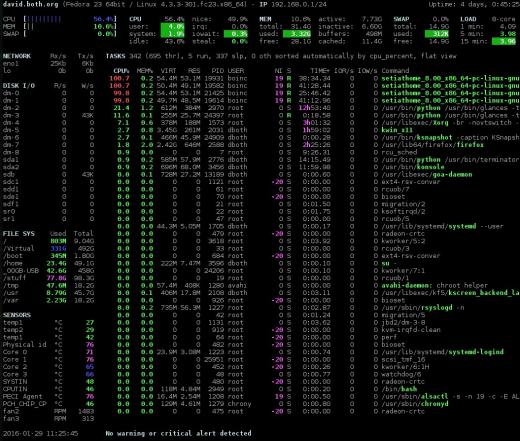
Rysunek 4: Interfejs spojrzeń z informacjami o sieci, dysku, systemie plików i czujnikach.
Ta sekcja podsumowania podoba mi się bardziej niż w przypadku innych monitorów; Myślę, że zawiera właściwe informacje w łatwo zrozumiałym formacie. Podobnie jak w przypadku atop i htop, możesz nacisnąć klawisz 1, aby przełączyć się między wyświetlaniem poszczególnych rdzeni procesora lub globalnym z wszystkimi rdzeniami procesora jako jedną średnią, jak pokazano na rysunku 4 powyżej.
Sekcja procesu
Sekcja procesu wyświetla standardowe informacje o każdym z uruchomionych procesów. Procesy mogą być sortowane automatycznie a lub według procesora c, pamięci m, nazwy p, użytkownika u, szybkości I / O i lub czasu t. Po posortowaniu automatyczne procesy są najpierw sortowane według najczęściej używanych zasobów.
Spojrzenia pokazują także ostrzeżenia i krytyczne alerty na samym dole ekranu, w tym czas i czas trwania zdarzenia. Może to być pomocne, gdy próbujesz zdiagnozować problemy, gdy nie możesz godzinami wpatrywać się w ekran. Te dzienniki alertów można włączać i wyłączać za pomocą polecenia l, ostrzeżenia można wyczyścić za pomocą polecenia w, a wszystkie alerty i ostrzeżenia można wyczyścić za pomocą x.
Co ciekawe, tylko spojrzenia te monitory, których nie można użyć do zabicia lub zmiany ustawień procesu. Ma służyć wyłącznie jako monitor. Możesz użyć zewnętrznych poleceń kill i renice do manipulowania procesami.
Pasek boczny
Spojrzenie ma bardzo ładny pasek boczny, który wyświetla informacje, które nie są dostępne w górnej lub górnej części. Atop wyświetla niektóre z tych danych, ale jedynym monitorem wyświetlającym dane z czujników jest spojrzenie. Czasami dobrze jest zobaczyć temperaturę wewnątrz komputera. Poszczególne moduły, dysk, system plików, sieć i czujniki mogą być włączane i wyłączane odpowiednio za pomocą poleceń d, f, n i s. Cały pasek boczny można przełączać za pomocą 2.
Statystyki Dockera można wyświetlić za pomocą D.
Konfiguracja
Spojrzenia nie wymagają pliku konfiguracyjnego do poprawnego działania. Jeśli wybierzesz taką opcję, ogólnosystemowe wystąpienie pliku konfiguracyjnego będzie znajdować się w /etc/glances/glances.conf. Poszczególni użytkownicy mogą mieć lokalną instancję pod adresem ~ / .config / glances / glances.conf, która nadpisuje globalną konfigurację. Głównym celem tych plików konfiguracyjnych jest ustawienie progów dla ostrzeżeń i krytycznych alertów. Nie ma sposobu, bym mógł znaleźć inne zmiany w konfiguracji – takie jak moduły paska bocznego lub wyświetlacze procesora – trwałe. Wygląda na to, że za każdym razem, gdy zaczynasz spoglądać, musisz ponownie skonfigurować te elementy.
Istnieje dokument /usr/share/doc/glances/glances-doc.html, który zawiera wiele informacji na temat używania spojrzenia i wyraźnie stwierdza, że można użyć pliku konfiguracyjnego do skonfigurowania wyświetlanych modułów. Jednak ani podane informacje, ani przykłady nie opisują, jak to zrobić.
Podsumowanie
Pamiętaj, aby przeczytać strony podręcznika dla każdego z tych monitorów, ponieważ jest tam dużo informacje o konfiguracji i interakcji z nimi. Użyj również klawisza h, aby uzyskać pomoc w trybie interaktywnym. Ta pomoc może dostarczyć informacji o wybieraniu i sortowaniu kolumn danych, ustawianiu interwału aktualizacji i wielu innych.
Te programy mogą wiele powiedzieć, gdy szukasz przyczyny problemu. Mogą ci powiedzieć, kiedy proces i który z nich pochłania czas procesora, czy jest wystarczająca ilość wolnej pamięci, czy procesy są wstrzymane podczas oczekiwania na zakończenie operacji we / wy, takich jak dostęp do dysku lub sieci, i wiele więcej.
Zdecydowanie zalecam, abyś spędził czas na oglądaniu tych programów monitorujących, gdy działają one w systemie, który działa normalnie, abyś mógł odróżnić te rzeczy, które mogą być nienormalne podczas poszukiwania przyczyny problemu.
Należy również pamiętać, że czynność korzystania z tych narzędzi monitorujących zmienia wykorzystanie zasobów systemu, w tym pamięci i czasu procesora.większość z tych monitorów zużywa od 2% do 3% czasu procesora systemu. spojrzenia mają znacznie większy wpływ niż inne i mogą zużywać od 10% do 20% czasu procesora. Pamiętaj, aby wziąć to pod uwagę przy wyborze narzędzi.
Pierwotnie zamierzałem zamieścić SAR (System Activity Reporter) w tym artykule, ale w miarę wydłużania się tego artykułu stało się dla mnie jasne, że SAR znacznie różni się od tych narzędzi monitorujących i zasługuje na osobny artykuł. Mając to na uwadze, planuję napisać artykuł o SAR i systemie plików / proc oraz trzeci artykuł o tym, jak używać wszystkich tych narzędzi do lokalizowania i rozwiązywania problemów.
