정보는 Linux 및 Linux가 실행되는 하드웨어와 관련된 문제를 포함하여 모든 컴퓨터 문제를 해결하는 핵심입니다. 기본적으로 모두 설치되지는 않지만 대부분의 배포에 사용할 수 있고 포함 된 많은 도구가 있습니다. 이러한 도구를 사용하여 방대한 양의 정보를 얻을 수 있습니다.
이 문서에서는 Red를 포함한 Red Hat 관련 배포판과 함께 제공되거나 쉽게 설치할 수있는 대화 형 명령 줄 인터페이스 (CLI) 도구에 대해 설명합니다. Hat Enterprise Linux, Fedora, CentOS 및 기타 파생 배포판. GUI 도구를 사용할 수 있고 좋은 정보를 제공하지만 CLI 도구는 모두 동일한 정보를 제공하며 많은 서버에 GUI 인터페이스가 없지만 모든 Linux 시스템에는 명령 줄 인터페이스가 있기 때문에 항상 사용할 수 있습니다.
이 문서는 제가 일반적으로 사용하는 도구에 중점을 둡니다. 내가 좋아하는 도구를 다루지 않았다면 용서해 주시고 어떤 도구를 사용하는지 그리고 그 이유를 댓글 섹션에 알려주십시오.
Linux 환경에서 문제를 파악하기위한 도구로 이동하는 것은 거의 항상 시스템 모니터링 도구. 저에게는 이러한 도구가 모두 top, atop, htop 및 glance입니다.
이러한 모든 도구는 CPU 및 메모리 사용량을 모니터링하며 대부분은 최소한 실행중인 프로세스에 대한 정보를 나열합니다. 일부는 Linux 시스템의 다른 측면도 모니터링합니다. 모두 시스템 활동에 대한 거의 실시간보기를 제공합니다.
부하 평균
모니터링 도구에 대해 논의하기 전에 부하 평균을 더 자세히 논의하는 것이 중요합니다.
부하 평균
p>
부하 평균은 CPU 사용량을 측정하는 데 중요한 기준이지만, 예를 들어 1 (또는 5 또는 10) 분 부하 평균이 4.04라고 말할 때 이것이 실제로 무엇을 의미합니까? 로드 평균은 CPU에 대한 수요의 척도로 간주 될 수 있습니다. CPU 시간을 기다리는 평균 명령어 수를 나타내는 숫자입니다. 따라서 이는 CPU가 실제로 작동하지 않는 I / O 대기 시간을 포함하는 표준 “CPU 백분율”과는 달리 CPU 성능의 진정한 척도입니다.
예를 들어, 완전히 활용 된 단일 프로세서 시스템 CPU 로드 평균은 1이됩니다. 이는 CPU가 수요를 정확히 충족하고 있음을 의미합니다. 즉, 완벽하게 활용됩니다. 로드 평균이 1보다 작 으면 CPU가 충분히 활용되지 않고로드 평균이 1보다 크면 CPU가 과도하게 사용되고 있으며 수요가 부족하고 만족스럽지 않음을 의미합니다. 예를 들어, 단일 CPU 시스템에서로드 평균이 1.5이면 CPU 명령의 1/3이 이전 명령이 완료 될 때까지 실행을 기다려야 함을 나타냅니다.
이것은 여러 명령에 대해서도 마찬가지입니다. 프로세서. 4 CPU 시스템의로드 평균이 4이면 완벽한 활용도를가집니다. 예를 들어로드 평균이 3.24이면 프로세서 중 3 개가 완전히 활용되고 하나는 약 76 %로 활용됩니다. 위의 예에서 4 CPU 시스템의 1 분로드 평균은 4.04입니다. 즉, 4 개의 CPU 사이에 남은 용량이없고 몇 개의 명령이 강제로 대기해야 함을 의미합니다. 완벽하게 활용 된 4 CPU 시스템은로드 평균이 4.00이므로 예제의 시스템이 완전히로드되었지만 오버로드되지는 않습니다.
로드 평균의 최적 조건은 총 CPU 수와 동일해야합니다. 시스템에서. 즉, 모든 CPU가 완전히 활용되지만 명령을 기다리도록 강요해서는 안됩니다. 장기 부하 평균은 전체 사용 추세를 나타냅니다.
Linux Journal은 부하 평균, 이론 및 그이면의 수학, 그리고이를 해석하는 방법을 2006 년 12 월 1 일에 설명하는 훌륭한 기사를 제공합니다.
신호
여기에서 설명하는 모든 모니터를 사용하여 실행중인 프로세스에 신호를 보낼 수 있습니다. 이러한 신호는 각각 특정 기능을 가지고 있지만 일부는 신호 처리기를 사용하여 수신 프로그램에서 정의 할 수 있습니다.
별도의 kill 명령을 사용하여 모니터 외부의 프로세스에 신호를 보낼 수도 있습니다. kill -l은 보낼 수있는 모든 가능한 신호를 나열하는 데 사용할 수 있습니다. 이 신호 중 3 개를 사용하여 프로세스를 종료 할 수 있습니다.
- SIGTERM (15) : 신호 15, SIGTERM은 k 키를 눌렀을 때 top 및 다른 모니터에서 보내는 기본 신호입니다. 또한 프로그램에 내장 된 신호 처리기가 있어야하므로 효율성이 가장 낮을 수도 있습니다. 프로그램의 시그널 핸들러는 들어오는 시그널을 가로 채서 그에 따라 동작해야합니다. 따라서 대부분 시그널 핸들러가없는 스크립트의 경우 SIGTERM은 무시됩니다. SIGTERM의이면에있는 아이디어는 단순히 프로그램이 스스로 종료하기를 원한다는 것을 알려주는 것입니다. 그것은 그것을 이용하고 열린 파일과 같은 것들을 정리 한 다음 통제되고 좋은 방식으로 스스로 종료됩니다.
- SIGKILL (9) : Signal 9, SIGKILL은 가장 난폭 한 프로그램조차도 죽일 수있는 수단을 제공합니다. , 스크립트 및 신호 처리기가없는 기타 프로그램 포함.그러나 신호 처리기가없는 스크립트 및 기타 프로그램의 경우 실행중인 스크립트를 종료 할뿐만 아니라 스크립트가 실행중인 쉘 세션도 종료합니다. 이것은 원하는 동작이 아닐 수 있습니다. 만약 당신이 프로세스를 죽이고 싶지만 괜찮다고 생각하지 않는다면, 이것이 당신이 원하는 신호입니다.이 신호는 프로그램 코드에서 신호 핸들러에 의해 가로 챌 수 없습니다.
- SIGINT (2) : 신호 2, SIGINT는 SIGTERM이 작동하지 않고 프로그램이 실행중인 쉘 세션을 종료하지 않고 프로그램이 좀 더 멋지게 종료되기를 원할 때 사용할 수 있습니다. SIGINT는 프로그램이있는 세션에 인터럽트를 보냅니다. 이것은 Ctrl-C 키 조합을 사용하여 실행중인 프로그램, 특히 스크립트를 종료하는 것과 같습니다.
이를 실험하려면 터미널 세션을 열고 / tmp에 파일을 만듭니다. cpuHog라는 이름을 지정하고 rwxr_xr_x 권한으로 실행 가능하게 만듭니다. 파일에 다음 콘텐츠를 추가합니다.
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
다른 창에서 다른 터미널 세션을 열고 인접하게 배치합니다. 결과를보고 새 세션에서 top을 실행할 수 있도록 서로에게주고받습니다. 다음 명령으로 cpuHog 프로그램을 실행합니다.
이 프로그램은 단순히 1 씩 계산하고 X의 현재 값을 STDOUT에 인쇄합니다. 그리고 그것은 CPU 사이클을 빨아들입니다. cpuHog가 실행되고있는 터미널 세션은 맨 위에 매우 높은 CPU 사용량을 표시해야합니다. 이것이 시스템 성능에 미치는 영향을 관찰하십시오. CPU 사용량은 즉시 증가해야하며로드 평균도 시간이 지남에 따라 증가하기 시작해야합니다. 원한다면 추가 터미널 세션을 열고 그 안에서 cpuHog 프로그램을 시작하여 여러 인스턴스를 실행하도록 할 수 있습니다.
죽이려는 cpuHog 프로그램의 PID를 결정합니다. k 키를 누르고 요약 섹션 하단의 교체 줄 아래에있는 메시지를 확인합니다. Top은 죽이려는 프로세스의 PID를 묻습니다. 해당 PID를 입력하고 Enter를 누르십시오. 이제 top은 신호 번호를 요청하고 기본값 인 15를 표시합니다. 여기에 설명 된 각 신호를 시도하고 결과를 관찰합니다.
Linux 시스템 모니터링을위한 4 가지 오픈 소스 도구
다음 중 하나 문제점 판별을 수행 할 때 사용하는 첫 번째 도구는 최고입니다. 나는 그것이 영원히 사용되어 왔고 다른 도구가 설치되지 않은 동안 항상 사용할 수 있기 때문에 좋아합니다.
최고의 프로그램은 실행중인 시스템에 대한 많은 정보를 제공하는 매우 강력한 유틸리티입니다. 여기에는 메모리 사용량, CPU로드 및 각 프로세스에서 사용중인 CPU 시간 및 메모리 양을 포함하여 실행중인 프로세스 목록에 대한 데이터가 포함됩니다. Top은 거의 실시간으로 시스템 정보를 표시하며 (기본적으로) 3 초마다 업데이트됩니다. 매우 작은 값은 시스템에 상당한 부하를 줄 수 있지만, 초 단위는 top에서 허용됩니다. 또한 대화 형이며 표시 할 데이터 열과 정렬 열을 수정할 수 있습니다.
상위 프로그램의 샘플 출력은 아래 그림 1에 나와 있습니다. 상단의 출력은 출력의 상단 섹션 인 “요약”섹션과 출력의 하단 부분 인 “프로세스”섹션이라는 두 섹션으로 나뉩니다. 일관성을 위해 top, atop, htop 및 glance에 대해이 용어를 사용하겠습니다.
top 프로그램에는 데이터 표시를 관리하고 개별 프로세스를 조작하는 데 사용할 수있는 유용한 대화 형 명령이 많이 있습니다. . 다양한 대화 형 명령에 대한 간략한 도움말 페이지를 보려면 h 명령을 사용하십시오. 도움말의 두 페이지를 모두 보려면 h를 두 번 누르십시오. 종료하려면 q 명령을 사용하십시오.
요약 섹션
상단 출력의 요약 섹션은 시스템 상태의 개요입니다. 첫 번째 줄은 시스템 가동 시간과 1 분, 5 분, 15 분로드 평균을 보여줍니다. 아래 예에서로드 평균은 각각 4.04, 4.17 및 4.06입니다.
두 번째 줄은 현재 활성화 된 프로세스 수와 각 프로세스의 상태를 보여줍니다.
다음에 CPU 통계가 표시됩니다. 아래 예에서와 같이 시스템에있는 모든 CPU에 대한 통계를 결합하는 단일 행 또는 각 CPU에 대해 하나의 행이있을 수 있습니다. 예제에 사용 된 컴퓨터의 경우 이것은 단일 쿼드 코어 CPU입니다. 1 키를 눌러 통합 된 CPU 사용량 표시와 개별 CPU 표시 사이를 전환합니다. 이 행의 데이터는 사용 가능한 총 CPU 시간의 백분율로 표시됩니다.
이 항목과 CPU 데이터에 대한 기타 필드는 아래에 설명되어 있습니다.
- us : userspace – 애플리케이션 및 커널이 아닌 사용자 공간에서 실행되는 기타 프로그램
- sy : 시스템 호출 – 커널 수준 기능. 여기에는 커널 자체가 소요 한 CPU 시간이 포함되지 않고 커널 시스템 호출 만 포함됩니다.
- ni : nice – 양의 nice 수준에서 실행중인 프로세스
- id : idle – 유휴 시간, 즉 실행중인 프로세스에서 사용하지 않는 시간입니다.
- wa : wait – I / O가 발생하기를 기다리는 데 소비 된 CPU주기입니다. 이것은 낭비되는 CPU 시간입니다.
- hi : 하드웨어 인터럽트 – 하드웨어 인터럽트를 처리하는 데 소비되는 CPU 사이클.
- si : 소프트웨어 인터럽트 – 소프트웨어 생성 인터럽트를 처리하는 데 소비 된 CPU 사이클 시스템 호출로.
- st : steal time – 하이퍼 바이저가 다른 가상 프로세서를 서비스하는 동안 가상 CPU가 실제 CPU를 기다리는 CPU주기의 백분율입니다.
요약 섹션의 마지막 두 줄은 메모리 사용량입니다. RAM과 스왑 공간을 모두 포함한 물리적 메모리 사용량을 보여줍니다.
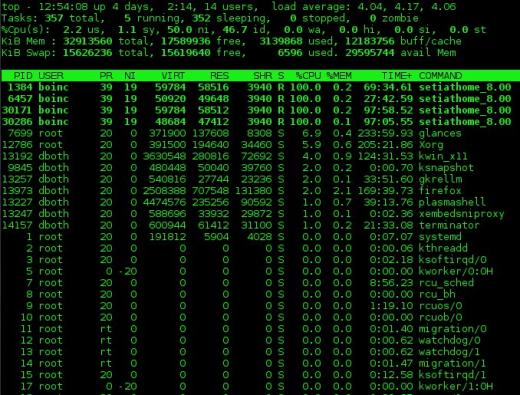
그림 1 : 완전히 활용 된 4 코어 CPU를 보여주는 top 명령.
1 명령을 사용하여 위의 그림 1과 같이 단일 글로벌 번호 또는 개별 CPU별로 CPU 통계를 표시 할 수 있습니다. l 명령은 부하 평균을 켜고 끕니다. t 및 m 명령은 off, text only 및 몇 가지 유형의 막대 그래프 형식을 통해 요약 섹션의 프로세스 / CPU 및 메모리 라인을 각각 회전합니다.
Process section
상단에서 출력되는 프로세스 섹션은 시스템에서 실행중인 프로세스 목록입니다 (최소한 터미널 디스플레이에 공간이있는 프로세스 수에 대해). 맨 위에 표시되는 기본 열은 아래에 설명되어 있습니다. 여러 다른 열을 사용할 수 있으며 각 열은 일반적으로 단일 키 입력으로 추가 할 수 있습니다. 자세한 내용은 맨 위 맨 페이지를 참조하십시오.
- PID – 프로세스 ID
- USER – 프로세스 소유자의 사용자 이름
- PR – 프로세스의 우선 순위
- NI – 프로세스의 좋은 수
- VIRT – 프로세스에 할당 된 총 가상 메모리 양
- RES – 프로세스에서 사용하는 스왑되지 않은 물리적 메모리의 상주 크기 (달리 명시되지 않는 한 kb).
- SHR – 프로세스에서 사용하는 공유 메모리의 양 (KB)
- S – 프로세스의 상태. R은 달리기, S는 수면, Z는 좀비 일 수 있습니다. 덜 자주 표시되는 상태는 추적 또는 중지의 경우 T, 중단 불가능한 절전의 경우 D 일 수 있습니다.
- % CPU – CPU주기의 백분율 또는 마지막 측정 기간 동안이 프로세스에서 사용한 시간입니다.
- % MEM – 프로세스에서 사용한 물리적 시스템 메모리의 백분율
- TIME + – 프로세스가 시작된 이후 프로세스에서 소비 한 총 CPU 시간 (100 분의 1 초)
- COMMAND – 프로세스를 시작하는 데 사용 된 명령입니다.
실행중인 프로세스 목록을 스크롤하려면 Page Up 및 Page Down 키를 사용합니다. d 또는 s 명령은 상호 교환이 가능하며 업데이트 간 지연 간격을 설정하는 데 사용할 수 있습니다. 기본값은 3 초이지만 1 초 간격을 선호합니다. 간격 단위는 1/10 (0.1) 초 정도로 낮을 수 있지만 측정하려는 CPU주기를 더 많이 소모합니다.
< 및 > 키를 사용하여 정렬 열을 왼쪽 또는 오른쪽으로 정렬합니다.
k 명령은 프로세스를 종료하는 데 사용되거나 r 명령은 그것을 renice. 강제 종료 또는 복구하려는 프로세스의 PID (프로세스 ID)를 알아야하며 해당 정보는 상단 디스플레이의 프로세스 섹션에 표시됩니다. 프로세스를 종료 할 때 top은 먼저 PID를 요청한 다음 프로세스를 종료하는 데 사용할 신호 번호를 요청합니다. 그것들을 입력하고 각각 뒤에 Enter 키를 누르십시오. 신호 15, SIGTERM으로 시작하고 프로세스가 종료되지 않으면 9, SIGKILL을 사용합니다.
구성
상단 디스플레이를 변경하면 W (in 대문자) 명령을 사용하여 구성 파일, ~ / .toprc에 대한 변경 사항을 홈 디렉토리에 기록합니다.
atop
저도 atop을 좋아합니다. 해당 유형의 I / O 활동에 대한 자세한 정보가 필요할 때 사용할 수있는 탁월한 모니터입니다. 기본 새로 고침 간격은 10 초이지만 interval i 명령을 사용하여 수행하려는 작업에 적합한 것으로 변경할 수 있습니다. atop은 top처럼 1 초 미만의 간격으로 새로 고침 할 수 없습니다.
도움말을 표시하려면 h 명령을 사용하세요. 여러 페이지의 도움말이 있으며 스페이스 바를 사용하여 아래로 스크롤하여 나머지를 볼 수 있습니다.
맨 위의 멋진 기능 중 하나는 원시 성능 데이터를 파일에 저장할 수 있다는 것입니다. 나중에 자세히 살펴보기 위해 재생하십시오. 이것은 간헐적 문제, 특히 시스템을 직접 모니터링 할 수없는 시간에 발생하는 문제를 추적하는 데 유용합니다. atopsar 프로그램은 저장된 파일의 데이터를 재생하는 데 사용됩니다.
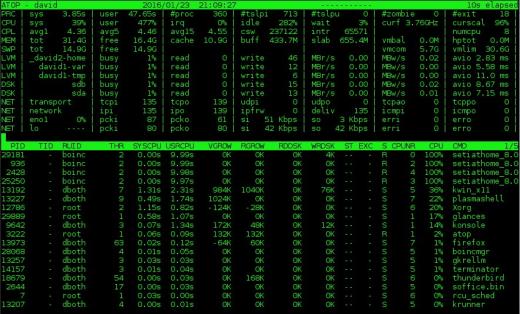 .
.
그림 2 : atop 시스템 모니터는 디스크 및 CPU 및 프로세스 데이터 외에 네트워크 활동.
요약 섹션
atop에는 top과 동일한 정보가 많이 포함되어 있지만 네트워크, 원시 디스크 및 논리 볼륨 활동에 대한 정보도 표시됩니다. 위의 그림 2는 디스플레이 상단의 열에 이러한 추가 데이터를 보여줍니다.더 넓은 디스플레이를 지원하기 위해 수평 화면 공간이있는 경우 추가 열이 표시됩니다. 반대로 가로 너비가 적 으면 표시되는 열이 더 적습니다. 또한 그림 2의 맨 오른쪽 두 열에있는 두 번째 줄에 현재 CPU 주파수와 확장 계수 (다른 모니터에서는 볼 수 없었던 것)를 표시하는 것이 좋습니다.
프로세스 섹션
atop 프로세스 디스플레이에는 top과 동일한 열이 일부 포함되지만 각 프로세스에 대한 디스크 I / O 정보 및 스레드 수는 물론 각 프로세스에 대한 가상 및 실제 메모리 증가 통계도 포함됩니다. 요약 섹션과 마찬가지로 수평 화면 공간이 충분하면 추가 열이 표시됩니다. 예를 들어 그림 2에서는 프로세스 소유자의 RUID (실제 사용자 ID)가 표시됩니다. 디스플레이를 확장하면 프로그램이 SUID (사용자 ID 설정)를 실행할 때 중요 할 수있는 EUID (유효 사용자 ID)도 표시됩니다.
atop은 디스크, 메모리, 네트워크 및 예약 정보에 대한 자세한 정보도 제공 할 수 있습니다. 각 프로세스에 대해. 해당 데이터를 보려면 각각 d, m, n 또는 s 키를 누르십시오. g 키는 디스플레이를 일반 프로세스 디스플레이로 되돌립니다.
C를 사용하여 CPU 사용량, M (메모리 사용량), D (디스크 사용량), N (네트워크 사용량), A (A)를 사용하여 쉽게 정렬 할 수 있습니다. 자동 정렬. 자동 정렬은 일반적으로 가장 바쁜 리소스를 기준으로 프로세스를 정렬합니다. 네트워크 사용량은 netatop 커널 모듈이 설치되고로드 된 경우에만 정렬 할 수 있습니다.
k 키를 사용하여 프로세스를 종료 할 수 있지만 프로세스를 다시 만드는 옵션은 없습니다.
기본적으로 지정된 시간 간격 동안 활동이 발생하지 않는 네트워크 및 디스크 장치는 표시되지 않습니다. 이로 인해 호스트의 하드웨어 구성에 대한 잘못된 가정이 발생할 수 있습니다. f 명령은 atop이 유휴 리소스를 표시하도록 강제하는 데 사용할 수 있습니다.
Configuration
atop man 페이지는 전역 및 사용자 수준 구성 파일을 참조하지만 내에서 찾을 수 없습니다. 자신의 Fedora 또는 CentOS 설치. 수정 된 구성을 저장하는 명령도 없으며 프로그램이 종료 될 때 자동으로 저장되지 않습니다. 따라서 이제 구성을 영구적으로 변경하는 방법이있는 것 같습니다.
htop
htop 프로그램은 top과 매우 비슷하지만 강력합니다. top과 매우 비슷해 보이지만 top이 제공하지 않는 몇 가지 기능도 제공합니다. 그러나 atop과 달리 디스크, 네트워크 또는 어떤 유형의 I / O 정보도 제공하지 않습니다.
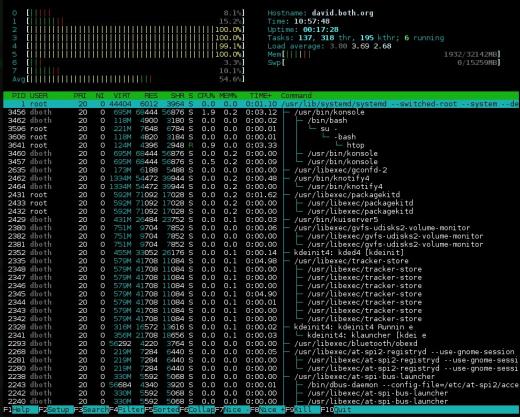
그림 3 : htop에는 리소스 사용량을 나타내는 멋진 막대 차트가 있으며 프로세스 트리를 표시 할 수 있습니다.
요약 섹션
htop의 요약 섹션은 두 개의 열에 표시됩니다. 매우 유연하며 원하는 순서대로 여러 가지 유형의 정보로 구성 할 수 있습니다. top 및 atop의 CPU 사용량 섹션은 결합 된 디스플레이와 각 CPU에 대해 하나의 막대 그래프를 표시하는 디스플레이간에 전환 할 수 있지만 htop은 그렇지 않습니다. 따라서 단일 결합 막대, 각 CPU에 대한 막대 및 특정 CPU를 단일 막대로 그룹화 할 수있는 다양한 조합을 포함하여 CPU 디스플레이에 대한 다양한 옵션이 있습니다.
제 생각에는 이것은 다른 시스템 모니터보다 더 깔끔한 요약 표시이며 읽기가 더 쉽습니다. 이 요약 섹션의 단점은 사용자 별 CPU 비율, 유휴 및 시스템 시간과 같이 다른 모니터에서 사용할 수있는 일부 정보를 htop에서 사용할 수 없다는 것입니다.
F2 (설정) 키는 다음과 같습니다. htop의 요약 섹션을 구성하는 데 사용됩니다. 사용 가능한 데이터 디스플레이 목록이 표시되며 기능 키를 사용하여 왼쪽 또는 오른쪽 열에 추가하고 선택한 열 내에서 위아래로 이동할 수 있습니다.
프로세스 섹션
htop의 프로세스 섹션은 top의 프로세스 섹션과 매우 유사합니다. 다른 모니터와 마찬가지로 프로세스는 CPU 또는 메모리 사용량, 사용자 또는 PID를 비롯한 여러 요소 중 하나로 정렬 할 수 있습니다. 트리보기를 선택하면 정렬이 불가능합니다.
F6 키를 사용하면 정렬 열을 선택할 수 있습니다. 정렬 할 수있는 열 목록이 표시되고 원하는 열을 선택하고 Enter 키를 누릅니다.
위 / 아래 화살표 키를 사용하여 프로세스를 선택할 수 있습니다. 프로세스를 종료하려면 위쪽 및 아래쪽 화살표 키를 사용하여 대상 프로세스를 선택하고 k 키를 누릅니다. 15, SIGTERM이 선택된 상태로 프로세스를 보낼 신호 목록이 표시됩니다. SIGTERM과 다른 경우 사용할 신호를 지정할 수 있습니다. F7 및 F8 키를 사용하여 선택한 프로세스를 복원 할 수도 있습니다.
특히 좋아하는 명령 중 하나는 실행중인 프로세스를 트리 형식으로 표시하여 실행중인 부모 / 자식 관계를 쉽게 결정할 수있는 F5입니다.
구성
각 사용자는 자신의 구성 파일 인 ~ / .config / htop / htoprc를 가지고 있으며 htop 구성에 대한 변경 사항은 여기에 자동으로 저장됩니다.htop에 대한 글로벌 구성 파일이 없습니다.
glances
최근에 glances에 대해 배웠습니다. 이것은 현재 제가 익숙한 다른 모니터보다 컴퓨터에 대한 더 많은 정보를 표시 할 수 있습니다. 와. 여기에는 디스크 및 네트워크 I / O, CPU 및 기타 하드웨어 온도뿐만 아니라 팬 속도를 표시 할 수있는 열 판독 값, 하드웨어 장치 및 논리 볼륨 별 디스크 사용량이 포함됩니다.
이 모든 정보를 보유 할 때의 단점 glances는 자체적으로 상당한 양의 CPU를 사용한다는 것입니다. 내 시스템에서는 CPU주기의 약 10 %에서 18 %를 사용할 수 있습니다. 모니터를 선택할 때 그 영향을 고려해야합니다.
요약 섹션
시선 요약 섹션에는 다른 요약 섹션과 동일한 정보가 대부분 포함되어 있습니다. 모니터. 수평 화면 공간이 충분하면 막대 그래프와 숫자 표시기로 CPU 사용량을 표시 할 수 있습니다. 그렇지 않으면 숫자 만 표시합니다.
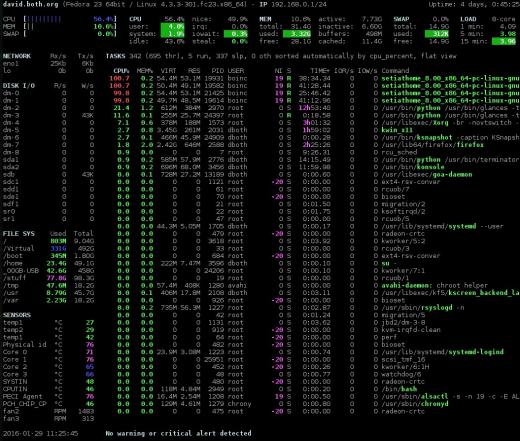
그림 4 : 네트워크, 디스크, 파일 시스템 및 센서 정보가있는 glances 인터페이스.
다른 모니터보다이 요약 섹션이 더 좋습니다. 이해하기 쉬운 형식으로 올바른 정보를 제공한다고 생각합니다. atop 및 htop과 마찬가지로 1 키를 눌러 개별 CPU 코어 표시 또는 위의 그림 4와 같이 단일 평균으로 모든 CPU 코어가있는 전역 표시간에 전환 할 수 있습니다.
프로세스 섹션
프로세스 섹션은 실행중인 각 프로세스에 대한 표준 정보를 표시합니다. 프로세스는 자동으로 a 또는 CPU c, 메모리 m, 이름 p, 사용자 u, I / O 속도 i 또는 시간 t별로 정렬 할 수 있습니다. 자동으로 정렬되면 프로세스는 가장 많이 사용되는 리소스를 기준으로 먼저 정렬됩니다.
Glances는 이벤트 시간 및 기간을 포함하여 화면 맨 아래에 경고 및 중요 알림도 표시합니다. 이것은 한 번에 몇 시간 동안 화면을 응시할 수 없을 때 문제를 진단하려고 할 때 유용 할 수 있습니다. 이러한 경고 로그는 l 명령으로 켜거나 끌 수 있으며, 경고는 w 명령으로 지울 수 있으며, 경고 및 경고는 모두 x로 지울 수 있습니다.
프로세스를 죽이거나 재생성하는 데 사용할 수없는 이러한 모니터. 그것은 엄격히 모니터로 의도 된 것입니다. 외부 kill 및 renice 명령을 사용하여 프로세스를 조작 할 수 있습니다.
사이드 바
Glances에는 top 또는 htop에서 사용할 수없는 정보를 표시하는 매우 멋진 사이드 바가 있습니다. Atop은이 데이터 중 일부를 표시하지만 센서 데이터를 표시하는 유일한 모니터는 glances입니다. 때로는 컴퓨터 내부의 온도를 확인하는 것이 좋습니다. 개별 모듈, 디스크, 파일 시스템, 네트워크 및 센서는 각각 d, f, n 및 s 명령을 사용하여 켜고 끌 수 있습니다. 전체 사이드 바는 2를 사용하여 토글 할 수 있습니다.
Docker 통계는 D로 표시 할 수 있습니다.
구성
Glances가 제대로 작동하기 위해 구성 파일이 필요하지 않습니다. 하나를 선택하면 구성 파일의 시스템 전체 인스턴스는 /etc/glances/glances.conf에 있습니다. 개별 사용자는 전역 구성을 재정의하는 ~ / .config / glances / glances.conf에서 로컬 인스턴스를 가질 수 있습니다. 이러한 구성 파일의 주요 목적은 경고 및 위험 경고에 대한 임계 값을 설정하는 것입니다. 사이드 바 모듈 또는 CPU 디스플레이와 같은 다른 구성 변경을 영구적으로 수행 할 수있는 방법은 없습니다. glances를 시작할 때마다 해당 항목을 재구성해야하는 것 같습니다.
사용에 대한 많은 정보를 제공하는 /usr/share/doc/glances/glances-doc.html 문서가 있습니다. 구성 파일을 사용하여 표시되는 모듈을 구성 할 수 있음을 명시 적으로 설명합니다. 그러나 제공된 정보 나 예제는이를 수행하는 방법을 설명하지 않습니다.
결론
많은 양의 모니터가 있으므로 각 모니터의 맨 페이지를 읽으십시오. 구성 및 상호 작용에 대한 정보. 또한 대화 형 모드에서 도움말을 보려면 h 키를 사용하십시오. 이 도움말은 데이터 열 선택 및 정렬, 업데이트 간격 설정 등에 대한 정보를 제공합니다.
이러한 프로그램은 문제의 원인을 찾을 때 많은 정보를 제공 할 수 있습니다. 그들은 언제 어떤 프로세스가 CPU 시간을 소모하는지, 충분한 여유 메모리가 있는지, 디스크 또는 네트워크 액세스와 같은 I / O가 완료되기를 기다리는 동안 프로세스가 중단되었는지 등을 알려줄 수 있습니다.
문제의 원인을 찾는 동안 비정상 일 수있는 것들을 구별 할 수 있도록 정상적으로 작동하는 시스템에서 이러한 모니터링 프로그램이 실행되는 동안 이러한 모니터링 프로그램을 시청하는 데 시간을 할애 할 것을 강력히 권장합니다.
또한 이러한 모니터링 도구를 사용하면 메모리 및 CPU 시간을 포함하여 시스템의 리소스 사용이 변경된다는 점을 알고 있어야합니다.이러한 모니터의 상단 및 대부분은 시스템 CPU 시간의 2 % 또는 3 %를 사용합니다. 시선은 다른 모니터보다 훨씬 더 많은 영향을 미치며 CPU 시간의 10 %에서 20 % 사이를 사용할 수 있습니다. 선택시이를 고려하십시오. 도구.
원래이 기사에 SAR (System Activity Reporter)을 포함하려고했지만이 기사가 길어지면서 SAR이 이러한 모니터링 도구와 크게 다르며 이를 염두에두고 SAR 및 / proc 파일 시스템에 대한 기사와 이러한 모든 도구를 사용하여 문제를 찾고 해결하는 방법에 대한 세 번째 기사를 작성할 계획입니다.
