Les informations sont la clé pour résoudre tout problème informatique, y compris les problèmes avec ou liés à Linux et au matériel sur lequel il fonctionne. De nombreux outils sont disponibles et inclus dans la plupart des distributions, même s’ils ne sont pas tous installés par défaut. Ces outils peuvent être utilisés pour obtenir d’énormes quantités d’informations.
Cet article décrit certains des outils d’interface de ligne de commande (CLI) qui sont fournis avec ou qui peuvent être facilement installés sur les distributions liées à Red Hat, y compris Red Hat Enterprise Linux, Fedora, CentOS et autres distributions dérivées. Bien qu’il existe des outils GUI disponibles et qu’ils offrent de bonnes informations, les outils CLI fournissent toutes les mêmes informations et ils sont toujours utilisables car de nombreux serveurs n’ont pas d’interface graphique mais tous les systèmes Linux ont une interface de ligne de commande.
Cet article se concentre sur les outils que j’utilise généralement. Si je n’ai pas couvert votre outil préféré, pardonnez-moi et dites-nous à tous quels outils vous utilisez et pourquoi dans la section commentaires.
Mes principaux outils pour la détermination des problèmes dans un environnement Linux sont presque toujours les outils de surveillance du système. Pour moi, ce sont top, atop, htop et regards.
Tous ces outils surveillent l’utilisation du processeur et de la mémoire, et la plupart d’entre eux contiennent au moins des informations sur les processus en cours d’exécution. Certains surveillent également d’autres aspects d’un système Linux. Tous fournissent des vues en temps quasi réel de l’activité du système.
Moyennes de charge
Avant de passer à la discussion des outils de surveillance, il est important de discuter des moyennes de charge plus en détail.
Les moyennes de charge sont un critère important pour mesurer l’utilisation du processeur, mais qu’est-ce que cela signifie vraiment quand je dis que la moyenne de charge sur 1 (ou 5 ou 10) minutes est de 4,04, par exemple? La moyenne de charge peut être considérée comme une mesure de la demande pour le processeur; c’est un nombre qui représente le nombre moyen d’instructions en attente de temps CPU. Il s’agit donc d’une véritable mesure des performances du processeur, contrairement au « pourcentage de processeur » standard qui inclut les temps d’attente d’E / S pendant lesquels le processeur ne fonctionne pas vraiment.
Par exemple, un processeur système à processeur unique entièrement utilisé aurait une charge moyenne de 1. Cela signifie que le processeur répond exactement à la demande; en d’autres termes, il a une utilisation parfaite. Une moyenne de charge inférieure à un signifie que le processeur est sous-utilisé et une moyenne de charge supérieure à 1 signifie que le processeur est surutilisé et qu’il y a une demande refoulée et insatisfaite. Par exemple, une moyenne de charge de 1,5 dans un système à processeur unique indique qu’un tiers des instructions du processeur sont forcées d’attendre d’être exécutées jusqu’à ce que celle qui la précède soit terminée.
Ceci est également vrai pour plusieurs processeurs. Si un système à 4 processeurs a une charge moyenne de 4, il a une utilisation parfaite. S’il a une charge moyenne de 3,24, par exemple, alors trois de ses processeurs sont pleinement utilisés et un est utilisé à environ 76%. Dans l’exemple ci-dessus, un système à 4 processeurs a une moyenne de charge d’une minute de 4,04, ce qui signifie qu’il n’y a pas de capacité restante parmi les 4 processeurs et que quelques instructions sont obligées d’attendre. Un système à 4 processeurs parfaitement utilisé afficherait une moyenne de charge de 4,00 pour que le système de l’exemple soit complètement chargé mais pas surchargé.
La condition optimale pour la moyenne de charge est qu’il soit égal au nombre total de processeurs dans un système. Cela signifierait que chaque CPU est pleinement utilisé et pourtant aucune instruction ne doit être obligée d’attendre. Les moyennes de charge à plus long terme fournissent une indication de la tendance générale d’utilisation.
Le Linux Journal a un excellent article décrivant les moyennes de charge, la théorie et les mathématiques derrière elles, et comment les interpréter dans le 1 décembre 2006 problème.
Signaux
Tous les moniteurs décrits ici vous permettent d’envoyer des signaux aux processus en cours d’exécution. Chacun de ces signaux a une fonction spécifique bien que certains d’entre eux puissent être définis par le programme récepteur en utilisant des gestionnaires de signaux.
La commande kill séparée peut également être utilisée pour envoyer des signaux à des processus en dehors des moniteurs. Le kill -l peut être utilisé pour lister tous les signaux possibles qui peuvent être envoyés. Trois de ces signaux peuvent être utilisés pour tuer un processus.
- SIGTERM (15): Signal 15, SIGTERM est le signal par défaut envoyé par top et les autres moniteurs lorsque la touche k est enfoncée. Il peut également être le moins efficace car le programme doit avoir un gestionnaire de signaux intégré. Le gestionnaire de signaux du programme doit intercepter les signaux entrants et agir en conséquence. Ainsi, pour les scripts, dont la plupart n’ont pas de gestionnaires de signaux, SIGTERM est ignoré. L’idée derrière SIGTERM est qu’en disant simplement au programme que vous voulez qu’il se termine, il en profitera et nettoiera des choses comme les fichiers ouverts, puis se terminera de manière contrôlée et agréable.
- SIGKILL (9): Signal 9, SIGKILL fournit un moyen de tuer même les programmes les plus récalcitrants , y compris les scripts et autres programmes qui n’ont pas de gestionnaire de signaux.Pour les scripts et autres programmes sans gestionnaire de signal, cependant, non seulement cela tue le script en cours d’exécution, mais il tue également la session shell dans laquelle le script s’exécute; ce n’est peut-être pas le comportement que vous souhaitez. Si vous voulez tuer un processus et que vous ne vous souciez pas d’être gentil, c’est le signal que vous voulez. Ce signal ne peut pas être intercepté par un gestionnaire de signal dans le code du programme.
- SIGINT (2): Signal 2, SIGINT peut être utilisé lorsque SIGTERM ne fonctionne pas et que vous voulez que le programme meure un peu plus bien, par exemple, sans tuer la session shell dans laquelle il s’exécute. SIGINT envoie une interruption à la session dans laquelle le programme est en cours d’exécution. Cela équivaut à terminer un programme en cours d’exécution, en particulier un script, avec la combinaison de touches Ctrl-C.
Pour expérimenter cela, ouvrez une session de terminal et créez un fichier dans / tmp nommé cpuHog et rendez-le exécutable avec les permissions rwxr_xr_x. Ajoutez le contenu suivant au fichier.
#!/bin/bash# This little program is a cpu hogX=0;while ;do echo $X;X=$((X+1));done
Ouvrez une autre session de terminal dans une autre fenêtre, positionnez-les adjacentes les uns aux autres afin que vous puissiez regarder les résultats et exécuter top dans la nouvelle session. Exécutez le programme cpuHog avec la commande suivante:
Ce programme compte simplement par un et imprime la valeur courante de X dans STDOUT. Et cela absorbe les cycles du processeur. La session de terminal dans laquelle cpuHog est en cours d’exécution devrait montrer une utilisation très élevée du processeur en haut. Observez l’effet que cela a sur les performances du système en haut. L’utilisation du processeur devrait immédiatement augmenter et les moyennes de charge devraient également commencer à augmenter avec le temps. Si vous le souhaitez, vous pouvez ouvrir des sessions de terminal supplémentaires et y démarrer le programme cpuHog afin que plusieurs instances soient en cours d’exécution.
Déterminez le PID du programme cpuHog que vous voulez tuer. Appuyez sur la touche k et regardez le message sous la ligne Swap en bas de la section de résumé. Top demande le PID du processus que vous voulez tuer. Entrez ce PID et appuyez sur Entrée. Maintenant, top demande le numéro du signal et affiche la valeur par défaut de 15. Essayez chacun des signaux décrits ici et observez les résultats.
4 outils open source pour la surveillance du système Linux
Un des les premiers outils que j’utilise pour identifier les problèmes sont les meilleurs. Je l’aime parce qu’il existe depuis toujours et qu’il est toujours disponible alors que les autres outils peuvent ne pas être installés.
Le programme principal est un utilitaire très puissant qui fournit de nombreuses informations sur votre système en cours d’exécution. Cela inclut des données sur l’utilisation de la mémoire, les charges du processeur et une liste des processus en cours d’exécution, y compris la quantité de temps processeur et de mémoire utilisée par chaque processus. Top affiche les informations système en temps quasi réel et se met à jour (par défaut) toutes les trois secondes. Les fractions de secondes sont autorisées par top, bien que de très petites valeurs puissent placer une charge importante sur le système. Il est également interactif et les colonnes de données à afficher et la colonne de tri peuvent être modifiées.
Un exemple de sortie du programme principal est illustré dans la figure 1 ci-dessous. La sortie du haut est divisée en deux sections qui sont appelées la section « résumé », qui est la section supérieure de la sortie, et la section « processus » qui est la partie inférieure de la sortie; J’utiliserai cette terminologie pour top, atop, htop et regards dans un souci de cohérence.
Le programme top a un certain nombre de commandes interactives utiles que vous pouvez utiliser pour gérer l’affichage des données et manipuler des processus individuels . Utilisez la commande h pour afficher une brève page d’aide pour les différentes commandes interactives. N’oubliez pas d’appuyer deux fois sur h pour afficher les deux pages de l’aide. Utilisez la commande q pour quitter.
Section récapitulative
La section récapitulative de la sortie de haut est un aperçu de l’état du système. La première ligne montre le temps de fonctionnement du système et les moyennes de charge sur 1, 5 et 15 minutes. Dans l’exemple ci-dessous, les moyennes de charge sont respectivement de 4,04, 4,17 et 4,06.
La deuxième ligne montre le nombre de processus actuellement actifs et l’état de chacun.
Les lignes contenant Les statistiques du processeur sont affichées ensuite. Il peut y avoir une seule ligne qui combine les statistiques de toutes les CPU présentes dans le système, comme dans l’exemple ci-dessous, ou une ligne pour chaque CPU; dans le cas de l’ordinateur utilisé pour l’exemple, il s’agit d’un seul processeur quad core. Appuyez sur la touche 1 pour basculer entre l’affichage consolidé de l’utilisation du processeur et l’affichage des processeurs individuels. Les données de ces lignes sont affichées sous forme de pourcentages du temps CPU total disponible.
Ces champs et les autres pour les données CPU sont décrits ci-dessous.
- us: userspace – Applications et d’autres programmes s’exécutant dans l’espace utilisateur, c’est-à-dire pas dans le noyau.
- sy: appels système – Fonctions au niveau du noyau. Cela n’inclut pas le temps CPU pris par le noyau lui-même, juste les appels système du noyau.
- ni: nice – Processus qui s’exécutent à un niveau positif positif.
- id: idle – Temps d’inactivité, c’est-à-dire temps non utilisé par un processus en cours d’exécution.
- wa: wait – Cycles CPU qui sont passés à attendre que les E / S se produisent. C’est du temps CPU perdu.
- salut: interruptions matérielles – Cycles CPU consacrés aux interruptions matérielles.
- si: interruptions logicielles – Cycles CPU passés à gérer les interruptions créées par le logiciel telles comme des appels système.
- st: steal time – Le pourcentage de cycles de processeur pendant lequel un processeur virtuel attend un processeur réel pendant que l’hyperviseur entretient un autre processeur virtuel.
Les deux dernières lignes de la section récapitulative concernent l’utilisation de la mémoire. Ils montrent l’utilisation de la mémoire physique, y compris la RAM et l’espace de swap.
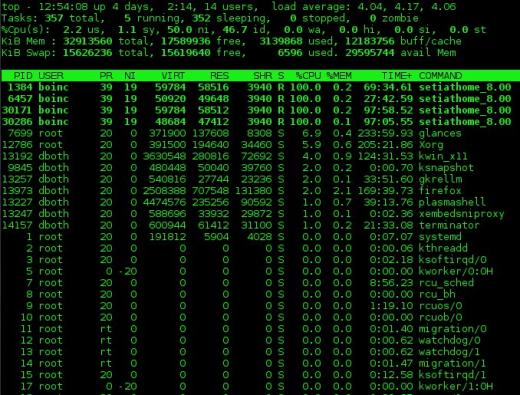
Figure 1: La commande du haut montrant un processeur à 4 cœurs pleinement utilisé.
Vous pouvez utiliser la commande 1 pour afficher les statistiques du processeur sous la forme d’un seul numéro global, comme illustré dans la figure 1 ci-dessus, ou par processeur individuel. La commande l active et désactive les moyennes de charge. Les commandes t et m font pivoter respectivement les lignes de processus / CPU et de mémoire de la section récapitulative, via off, texte uniquement, et quelques types de formats de graphique à barres.
Section de processus
La section processus de la sortie du haut est une liste des processus en cours d’exécution dans le système – au moins pour le nombre de processus pour lesquels il y a de la place sur l’écran du terminal. Les colonnes par défaut affichées par top sont décrites ci-dessous. Plusieurs autres colonnes sont disponibles et chacune peut généralement être ajoutée avec une seule touche. Reportez-vous à la page de manuel supérieure pour plus de détails.
- PID – L’ID du processus.
- USER – Le nom d’utilisateur du propriétaire du processus.
- PR – La priorité du processus.
- NI – Le joli numéro du processus.
- VIRT – La quantité totale de mémoire virtuelle allouée au processus.
- RES – Taille résidente (en ko sauf indication contraire) de la mémoire physique non permutée consommée par un processus.
- SHR – La quantité de mémoire partagée en ko utilisée par le processus.
- S – Le statut du processus. Cela peut être R pour courir, S pour dormir et Z pour zombie. Les états les moins fréquemment vus peuvent être T pour tracé ou arrêté, et D pour veille ininterrompue.
- % CPU – Le pourcentage de cycles de processeur, ou le temps utilisé par ce processus au cours de la dernière période de temps mesurée.
- % MEM – Le pourcentage de mémoire système physique utilisée par le processus.
- TIME + – Temps CPU total jusqu’à 100e de seconde consommé par le processus depuis le démarrage du processus.
- COMMAND – C’est la commande qui a été utilisée pour lancer le processus.
Utilisez les touches Page Up et Page Down pour faire défiler la liste des processus en cours. Les commandes d ou s sont interchangeables et peuvent être utilisées pour définir l’intervalle de retard entre les mises à jour. La valeur par défaut est de trois secondes, mais je préfère un intervalle d’une seconde. La granularité de l’intervalle peut être aussi basse qu’un dixième (0,1) de seconde, mais cela consommera plus de cycles CPU que vous essayez de mesurer.
Vous pouvez utiliser le < et > pour séquencer la colonne de tri à gauche ou à droite.
La commande k est utilisée pour tuer un processus ou la commande r pour renoncez-le. Vous devez connaître l’ID de processus (PID) du processus que vous voulez tuer ou renommer et cette information est affichée dans la section processus de l’affichage supérieur. Lors de la destruction d’un processus, top demande d’abord le PID, puis le numéro de signal à utiliser pour tuer le processus. Tapez-les et appuyez sur la touche Entrée après chaque. Commencez avec le signal 15, SIGTERM, et si cela ne tue pas le processus, utilisez 9, SIGKILL.
Configuration
Si vous modifiez l’affichage supérieur, vous pouvez utiliser le W (dans uppercase) pour écrire les modifications dans le fichier de configuration, ~ / .toprc dans votre répertoire personnel.
atop
J’aime aussi atop. C’est un excellent moniteur à utiliser lorsque vous avez besoin de plus de détails sur ce type d’activité d’E / S. L’intervalle d’actualisation par défaut est de 10 secondes, mais cela peut être modifié à l’aide de la commande interval i en fonction de ce que vous essayez de faire. atop ne peut pas s’actualiser à des intervalles inférieurs à la seconde comme le fait top.
Utilisez la commande h pour afficher l’aide. Assurez-vous de noter qu’il existe plusieurs pages d’aide et que vous pouvez utiliser la barre d’espace pour faire défiler vers le bas pour voir le reste.
Une fonctionnalité intéressante de atop est qu’il peut enregistrer les données de performance brutes dans un fichier et puis relisez-le plus tard pour une inspection minutieuse. Ceci est pratique pour dépister les problèmes internes, en particulier ceux qui surviennent lorsque vous ne pouvez pas surveiller directement le système. Le programme atopsar est utilisé pour lire les données du fichier enregistré.
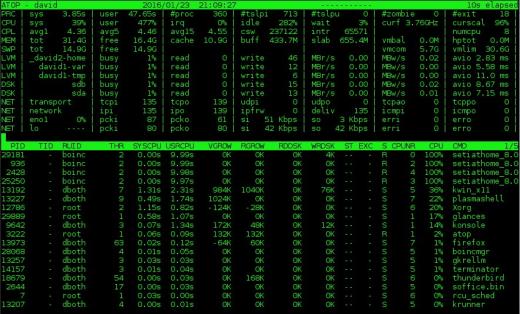 .
.
Figure 2: Le moniteur système au sommet fournit des informations sur le disque et l’activité du réseau en plus du processeur et des données de processus.
La section récapitulative
au sommet contient une grande partie des mêmes informations que top mais affiche également des informations sur le réseau, le disque brut et l’activité du volume logique. La figure 2 ci-dessus montre ces données supplémentaires dans les colonnes en haut de l’écran.Notez que si vous disposez d’un écran horizontal pour prendre en charge un affichage plus large, des colonnes supplémentaires seront affichées. Inversement, si vous avez moins de largeur horizontale, moins de colonnes sont affichées. J’aime aussi que le haut affiche la fréquence actuelle du processeur et le facteur d’échelle – quelque chose que je n’ai vu sur aucun de ces moniteurs – sur la deuxième ligne dans les deux colonnes les plus à droite de la figure 2.
Section Processus
L’affichage du processus en haut inclut certaines des mêmes colonnes que celui de top, mais il inclut également des informations d’E / S disque et le nombre de threads pour chaque processus ainsi que des statistiques de croissance de la mémoire virtuelle et réelle pour chaque processus. Comme pour la section récapitulative, des colonnes supplémentaires s’afficheront s’il y a suffisamment d’espace sur l’écran horizontal. Par exemple, dans la figure 2, le RUID (Real User ID) du propriétaire du processus est affiché. L’extension de l’écran affichera également l’EUID (ID utilisateur effectif), ce qui peut être important lorsque les programmes exécutent SUID (Set User ID).
au sommet peut également fournir des informations détaillées sur le disque, la mémoire, le réseau et les informations de planification pour chaque processus. Appuyez simplement sur les touches d, m, n ou s respectivement pour afficher ces données. La touche g ramène l’affichage à l’affichage générique du processus.
Le tri peut être effectué facilement en utilisant C pour trier par utilisation du processeur, M pour l’utilisation de la mémoire, D pour l’utilisation du disque, N pour l’utilisation du réseau et A pour tri automatique. Le tri automatique trie généralement les processus en fonction de la ressource la plus chargée. L’utilisation du réseau ne peut être triée que si le module du noyau netatop est installé et chargé.
Vous pouvez utiliser la touche k pour tuer un processus mais il n’y a pas d’option pour renommer un processus.
Par défaut, les périphériques réseau et disque pour lesquels aucune activité ne se produit pendant un intervalle de temps donné ne sont pas affichés. Cela peut conduire à des hypothèses erronées sur la configuration matérielle de l’hôte. La commande f peut être utilisée pour forcer atop à afficher les ressources inactives.
Configuration
La page de manuel atop fait référence aux fichiers de configuration globaux et de niveau utilisateur, mais aucun ne peut être trouvé dans mon propres installations Fedora ou CentOS. Il n’y a pas non plus de commande pour enregistrer une configuration modifiée et une sauvegarde n’a pas lieu automatiquement lorsque le programme est terminé. Donc, il semble y avoir maintenant moyen de rendre les changements de configuration permanents.
htop
Le programme htop ressemble beaucoup à top mais sous stéroïdes. Cela ressemble beaucoup à top, mais il offre également des fonctionnalités que top n’a pas. Contrairement à atop, cependant, il ne fournit aucune information de disque, réseau ou E / S de quelque type que ce soit.
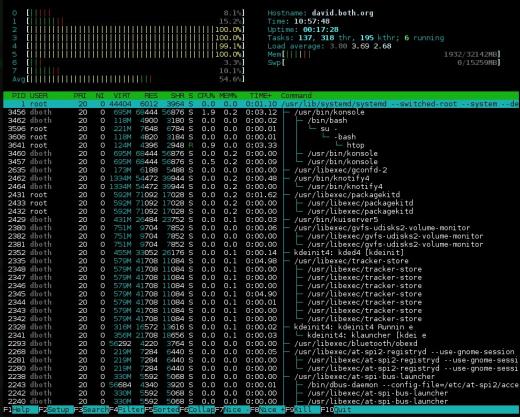
Figure 3: htop a de jolis graphiques à barres pour indiquer l’utilisation des ressources et il peut afficher l’arborescence des processus.
Section récapitulative
La section récapitulative de htop est affichée dans deux colonnes. Il est très flexible et peut être configuré avec différents types d’informations dans à peu près n’importe quel ordre que vous souhaitez. Bien que les sections d’utilisation du processeur en haut et en haut puissent être basculées entre un affichage combiné et un affichage affichant un graphique à barres pour chaque processeur, htop ne le peut pas. Il a donc un certain nombre d’options différentes pour l’affichage du processeur, y compris une seule barre combinée, une barre pour chaque processeur et diverses combinaisons dans lesquelles des processeurs spécifiques peuvent être regroupés dans une seule barre.
Je pense il s’agit d’un affichage récapitulatif plus propre que certains des autres moniteurs système et il est plus facile à lire. L’inconvénient de cette section de résumé est que certaines informations ne sont pas disponibles dans htop qui est disponible dans les autres moniteurs, comme les pourcentages de CPU par utilisateur, inactif et heure système.
La touche F2 (Setup) est utilisé pour configurer la section récapitulative de htop. Une liste des affichages de données disponibles s’affiche et vous pouvez utiliser les touches de fonction pour les ajouter à la colonne de gauche ou de droite et pour les déplacer de haut en bas dans la colonne sélectionnée.
Section de processus
La section process de htop est très similaire à celle de top. Comme pour les autres moniteurs, les processus peuvent être triés selon plusieurs facteurs, notamment l’utilisation du processeur ou de la mémoire, l’utilisateur ou le PID. Notez que le tri n’est pas possible lorsque l’arborescence est sélectionnée.
La touche F6 vous permet de sélectionner la colonne de tri; il affiche une liste des colonnes disponibles pour le tri et vous sélectionnez la colonne souhaitée et appuyez sur la touche Entrée.
Vous pouvez utiliser les touches fléchées haut et bas pour sélectionner un processus. Pour arrêter un processus, utilisez les touches fléchées haut et bas pour sélectionner le processus cible et appuyez sur la touche k. Une liste de signaux pour envoyer le processus s’affiche avec 15, SIGTERM, sélectionné. Vous pouvez spécifier le signal à utiliser, s’il est différent de SIGTERM. Vous pouvez également utiliser les touches F7 et F8 pour renommer le processus sélectionné.
Une commande que j’aime particulièrement est F5 qui affiche les processus en cours dans un format d’arborescence, ce qui facilite la détermination des relations parent / enfant de l’exécution
Configuration
Chaque utilisateur a son propre fichier de configuration, ~ / .config / htop / htoprc et les modifications apportées à la configuration de htop y sont automatiquement stockées.Il n’existe pas de fichier de configuration globale pour htop.
regards
Je viens tout juste de découvrir les regards, qui peuvent afficher plus d’informations sur votre ordinateur que tous les autres moniteurs que je connais actuellement avec. Cela inclut les E / S disque et réseau, les lectures thermiques qui peuvent afficher les températures du processeur et d’autres matériels ainsi que la vitesse des ventilateurs, et l’utilisation du disque par périphérique matériel et volume logique.
L’inconvénient d’avoir toutes ces informations est que regards utilise une quantité importante de ressources CPU se ressuscite. Sur mes systèmes, je trouve qu’il peut utiliser environ 10% à 18% des cycles du processeur. C’est beaucoup donc vous devriez considérer cet impact lorsque vous choisissez votre moniteur.
Section récapitulative
La section récapitulative de regards contient la plupart des mêmes informations que les sections récapitulatives de l’autre moniteurs. Si vous disposez d’un écran horizontal suffisant, il peut afficher l’utilisation du processeur avec à la fois un graphique à barres et un indicateur numérique, sinon il n’affichera que le nombre.
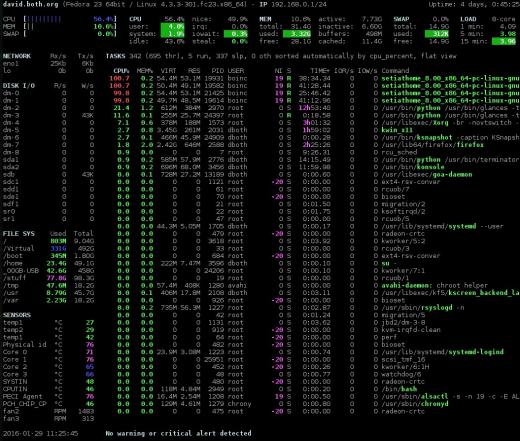
Figure 4: L’interface glances avec les informations sur le réseau, le disque, le système de fichiers et les capteurs.
J’aime cette section de résumé mieux que celles des autres moniteurs; Je pense qu’il fournit les bonnes informations dans un format facilement compréhensible. Comme avec atop et htop, vous pouvez appuyer sur la touche 1 pour basculer entre un affichage des cœurs de processeur individuels ou un affichage global avec tous les cœurs de processeur sous forme de moyenne unique, comme illustré à la figure 4 ci-dessus.
Section Processus
La section Process affiche les informations standard sur chacun des processus en cours. Les processus peuvent être triés automatiquement a, ou par CPU c, mémoire m, nom p, utilisateur u, débit d’E / S i ou heure t. Une fois triés automatiquement, les processus sont d’abord triés par la ressource la plus utilisée.
Glances affiche également les avertissements et les alertes critiques tout en bas de l’écran, y compris l’heure et la durée de l’événement. Cela peut être utile lorsque vous essayez de diagnostiquer des problèmes lorsque vous ne pouvez pas regarder l’écran pendant des heures à la fois. Ces journaux d’alertes peuvent être activés ou désactivés avec la commande l, les avertissements peuvent être effacés avec la commande w tandis que les alertes et les avertissements peuvent tous être effacés avec x.
Il est intéressant de noter que les regards sont le seul parmi ces moniteurs qui ne peuvent pas être utilisés pour tuer ou renommer un processus. Il est strictement conçu comme un moniteur. Vous pouvez utiliser les commandes externes kill et renice pour manipuler les processus.
Barre latérale
Glances a une très belle barre latérale qui affiche des informations qui ne sont pas disponibles en haut ou en htop. Atop affiche certaines de ces données, mais regards est le seul moniteur qui affiche les données des capteurs. Parfois, il est agréable de voir les températures à l’intérieur de votre ordinateur. Les modules individuels, le disque, le système de fichiers, le réseau et les capteurs peuvent être activés et désactivés à l’aide des commandes d, f, n et s, respectivement. La barre latérale entière peut être basculée en utilisant 2.
Les statistiques de Docker peuvent être affichées avec D.
Configuration
Glances ne nécessite pas de fichier de configuration pour fonctionner correctement. Si vous choisissez d’en avoir un, l’instance du fichier de configuration à l’échelle du système se trouvera dans /etc/glances/glances.conf. Les utilisateurs individuels peuvent avoir une instance locale dans ~ / .config / glances / glances.conf qui remplacera la configuration globale. L’objectif principal de ces fichiers de configuration est de définir des seuils pour les avertissements et les alertes critiques. Il n’y a aucun moyen que je puisse trouver pour apporter d’autres modifications de configuration, telles que les modules de la barre latérale ou les affichages du processeur, de manière permanente. Il semble que vous deviez reconfigurer ces éléments à chaque fois que vous lancez des regards.
Il existe un document, /usr/share/doc/glances/glances-doc.html, qui fournit de nombreuses informations sur l’utilisation regards, et il indique explicitement que vous pouvez utiliser le fichier de configuration pour configurer les modules affichés. Cependant, ni les informations fournies ni les exemples ne décrivent comment faire cela.
Conclusion
Assurez-vous de lire les pages de manuel de chacun de ces moniteurs car il y a un grand nombre de des informations sur leur configuration et leur interaction. Utilisez également la touche h pour obtenir de l’aide en mode interactif. Cette aide peut vous fournir des informations sur la sélection et le tri des colonnes de données, la définition de l’intervalle de mise à jour et bien plus encore.
Ces programmes peuvent vous en dire beaucoup lorsque vous recherchez la cause d’un problème. Ils peuvent vous dire quand un processus, et lequel, consomme du temps CPU, s’il y a suffisamment de mémoire libre, si les processus sont bloqués en attendant la fin des E / S telles que l’accès au disque ou au réseau, et bien plus encore.
Je vous recommande fortement de passer du temps à regarder ces programmes de surveillance pendant qu’ils fonctionnent sur un système qui fonctionne normalement afin que vous puissiez différencier les choses qui peuvent être anormales pendant que vous cherchez la cause d’un problème.
Vous devez également être conscient que le fait d’utiliser ces outils de surveillance modifie l’utilisation des ressources du système, y compris la mémoire et le temps CPU.top et la plupart de ces moniteurs utilisent peut-être 2% ou 3% du temps CPU d’un système. Les regards ont beaucoup plus d’impact que les autres et peuvent utiliser entre 10% et 20% du temps CPU. Veillez à en tenir compte lors du choix de votre
Au départ, j’avais l’intention d’inclure SAR (System Activity Reporter) dans cet article, mais au fur et à mesure que cet article s’allongeait, il m’est également apparu clairement que SAR est très différent de ces outils de surveillance et mérite d’avoir un article séparé. Dans cet esprit, je prévois d’écrire un article sur SAR et le système de fichiers / proc, et un troisième article sur la façon d’utiliser tous ces outils pour localiser et résoudre les problèmes.
